标签:同步 font 需要 控制器 完成 结构 bit 并行 快速
作者:MingChaoSun
原文:https://blog.csdn.net/sunmc1204953974/article/details/51000970
一、CPU和GPU

上图是CPU与GPU的对比图,对于浮点数操作能力,CPU与GPU的能力相差在GPU更适用于计算强度高,多并行的计算中。因此,GPU拥有更多晶体管,而不是像CPU一样的数据Cache和流程控制器。这样的设计是因为多并行计算的时候每个数据单元执行相同程序,不需要那么繁琐的流程控制,而更需要高计算能力,这也不需要大cache。但也因此,每个GPU的计算单元的结构是十分简单的,因此对程序的可并行性的要求也是十分苛刻的。
这里我们再介绍一下使用GPU计算的优缺点(摘自《深入浅出谈CUDA》):
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个优点:
当然,使用显示芯片也有它的缺点:
二、CUDA架构
Host 和 Kernel
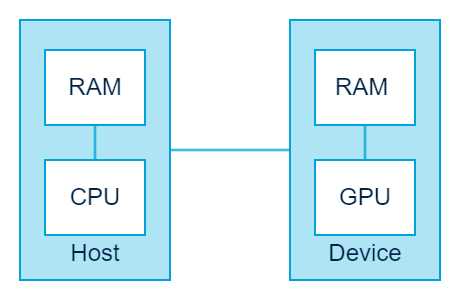
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能太常进行这类动作,以免降低效率。
thread-block-grid 结构
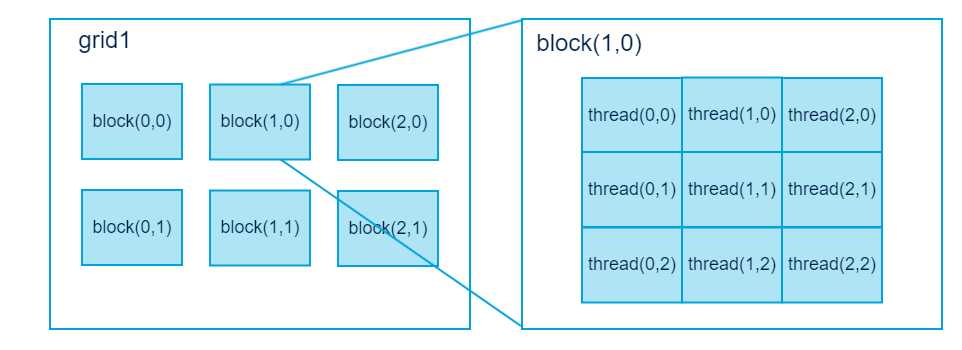
在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
执行模式
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
标签:同步 font 需要 控制器 完成 结构 bit 并行 快速
原文地址:https://www.cnblogs.com/gdut-gordon/p/9904513.html