标签:不一致 zab 相同 设置 应用 它的 不同 时间 db2
一、分布式架构详解1、分布式发展历程
1.1 单点集中式
特点:App、DB、FileServer都部署在一台机器上。并且访问请求量较少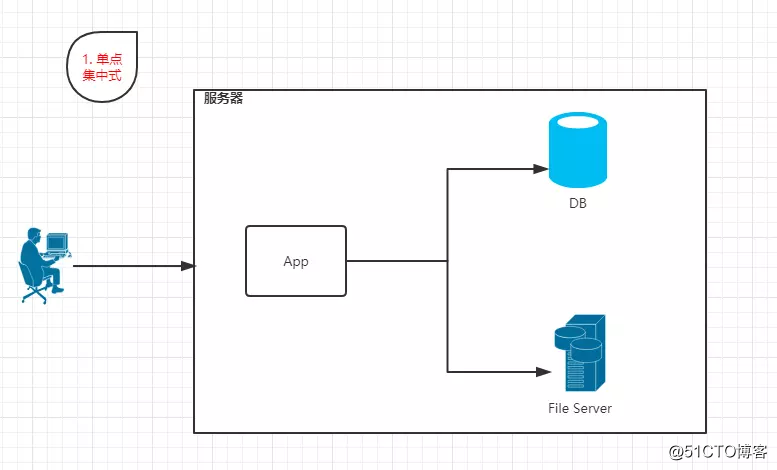
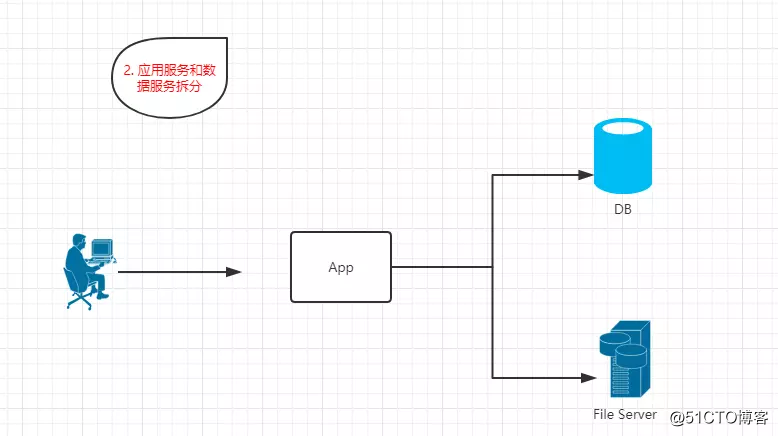
1.2? 应用服务和数据服务拆分
?特点:App、DB、FileServer分别部署在独立服务器上。并且访问请求量较少
1.3? 使用缓存改善性能
?特点:数据库中频繁访问的数据存储在缓存服务器中,减少数据库的访问次数,降低数据库的压力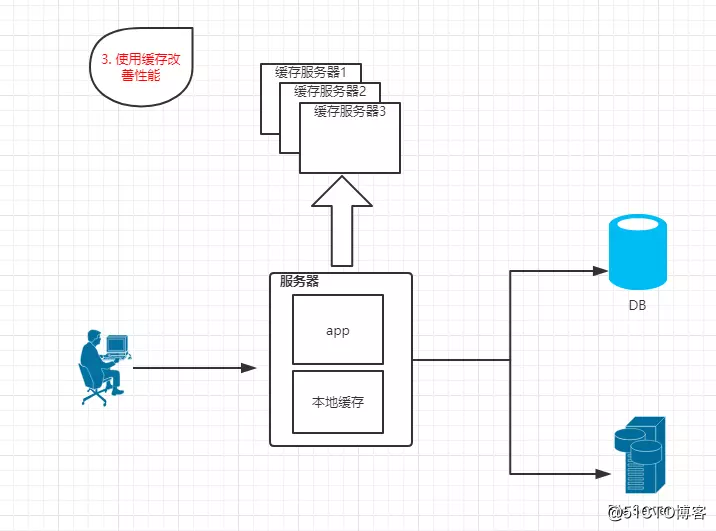
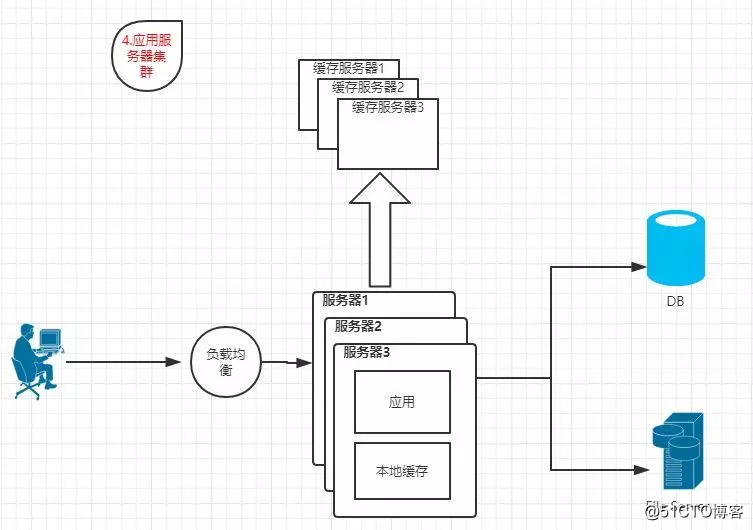
1.4 应用服务器集群
?特点:多台应用服务器通过负载均衡同时对外提供服务,解决单台服务器处理能力上限的问题
1.5 数据库读写分离
特点:数据库进行读写分离(主从)设计,解决数据库的处理压力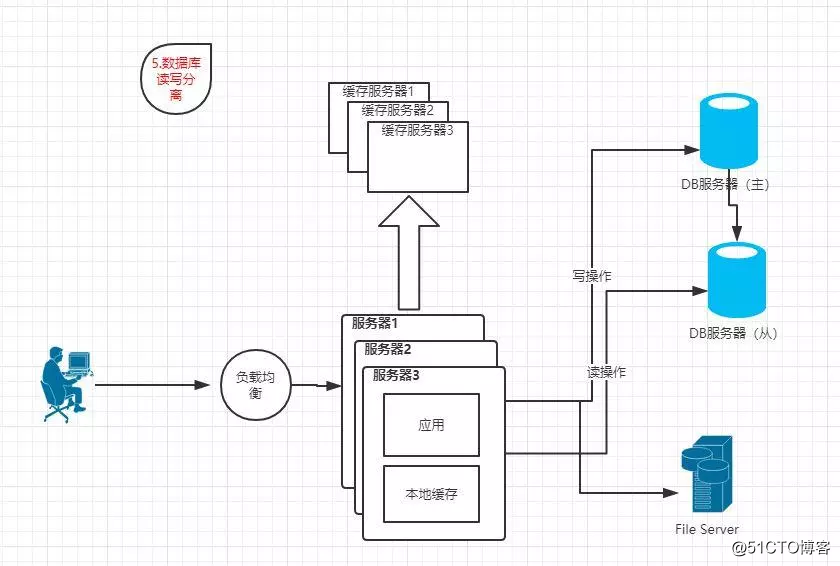
1.6 反向代理和CDN加速
?特点:采用反向代理和CDN加快系统的访问速度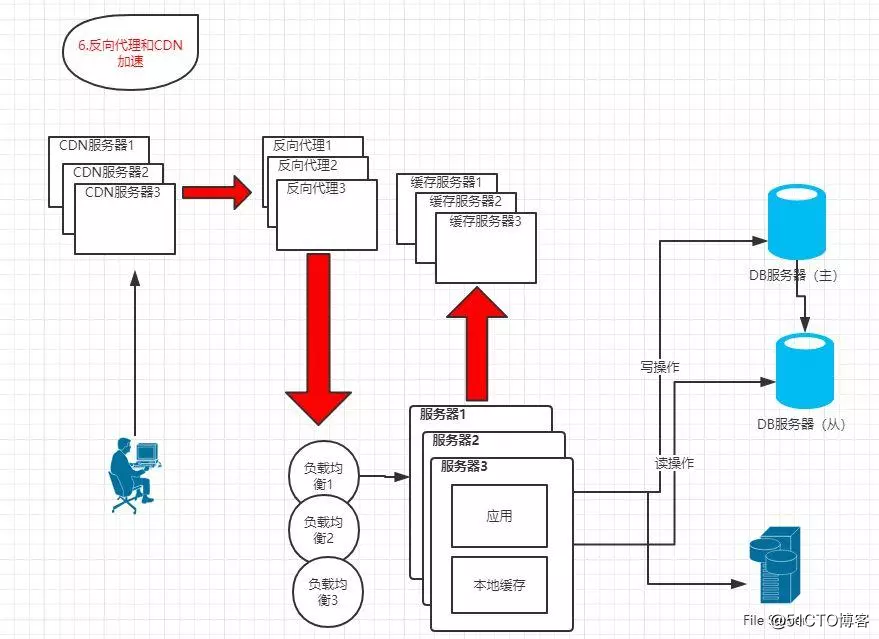
1.7 分布式文件系统和分布式数据库
?特点:数据库采用分布式数据库,文件系统采用分布式文件系统
随着业务的发展,最终数据库读写分离也将无法满足需求,需要采用分布式数据库和分布式文件系统来支撑
分布式数据库是数据库拆分后的最后方法,只有在单表规模非常庞大的时候才使用,更常用的数据库拆分手段是业务分库,将不同业务的数据库部署在不同的机器上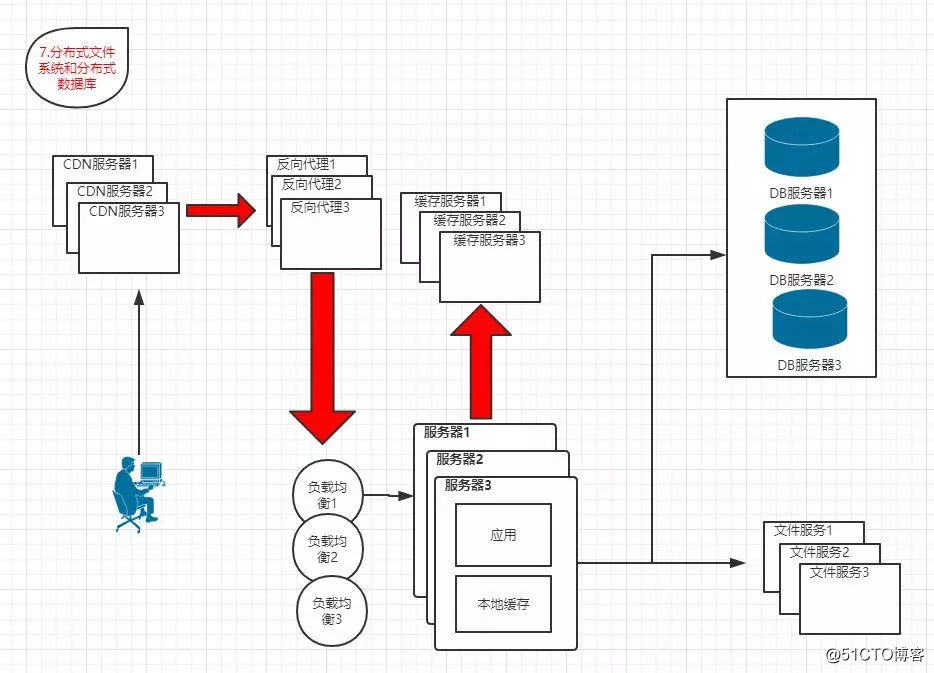
二、?分布式技术详解
并发性
大任务拆分成多个任务部署到多台机器上对外提供服务
时间要统一
一个服务部署在多台机器上是一样的,无任何差别
?硬盘坏了 CPU烧了....
三、分布式事务
原子性(Atomicity):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
比如A有500元,B有300元,A向B转账100,无论怎么样,A和B的总和总是800元
隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
2P= Two Phase commit ??二段提交(RDBMS(关系型数据库管理系统)经常就是这种机制,保证强一致性)
3P= Three Phase commit ?三段提交
说明:2P/3P是为了保证事务的ACID(原子性、一致性、隔离性、持久性)
2.1 2P的两个阶段
阶段1:提交事务请求(投票阶段)询问是否可以提交事务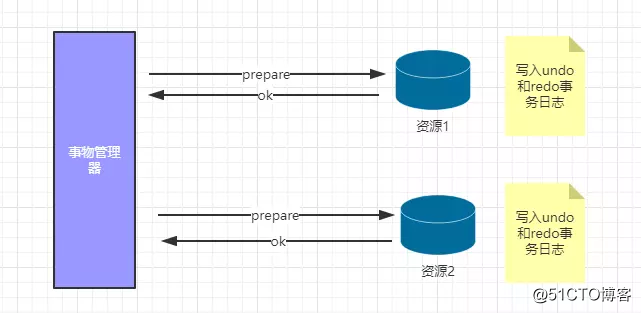
阶段2:执行事务提交(commit、rollback)?真正的提交事务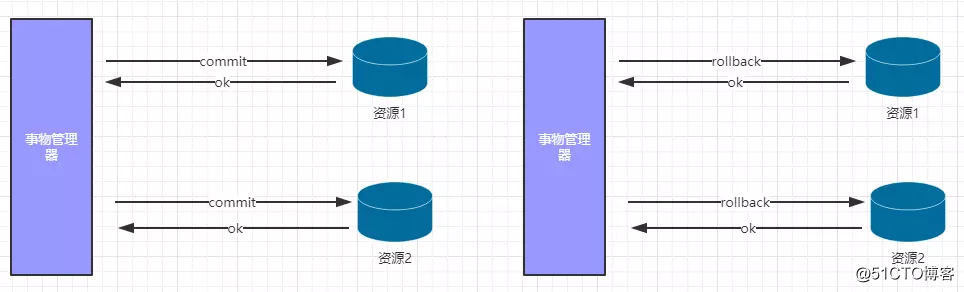
2.2 3P的三个阶段
阶段1:是否提交-询问是否可以做事务提交
阶段2:预先提交-预先提交事务
阶段3:执行事务提交(commit、rollback)真正的提交事务
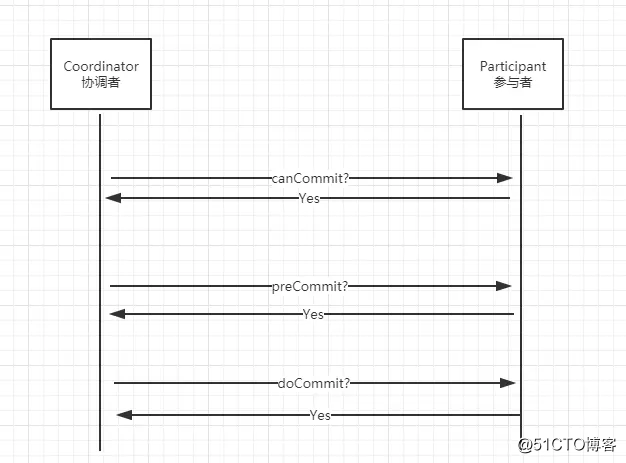
说明:3P把2P的阶段一拆分成了前面两个阶段
一致性(Consistency):分布式数据库的数据保持一致
可用性(Availability):任何一个节点挂了,其他节点可以继续对外提供服务
分区容错性(网络分区)Partition tolerance:一个数据库所在的机器坏了,如硬盘坏了,数据丢失了,可以新增一台机器,然后从其他正常的机器把备份的数据同步过来
CAP理论的特点:CAP只能满足其中2条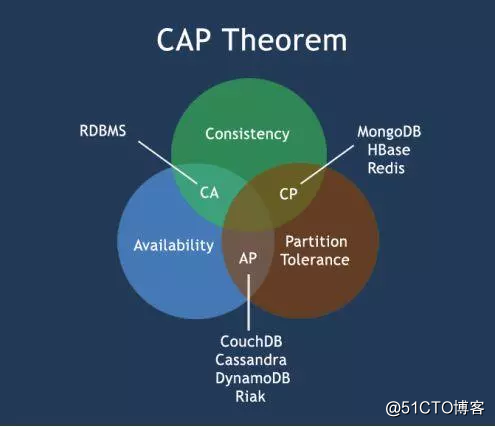
CA(放弃P):将所有的数据放在一个节点。满足一致性、可用性。
AP(放弃C):放弃强一致性,用最终一致性来保证。
CP(放弃A):一旦系统遇见故障,受到影响的服务器需要等待一段时间,在恢复期间无法对外提供服务。
举例说明CAP理论:
有3台机器分别有3个数据库分别有两张表,数据都是一样的
Machine1-db1-tbl_person、tbl_order
Machine2-db2-tbl_person、tbl_order
Machine3-db3-tbl_person、tbl_order
1)当向machine1的db1的表tbl_person、tbl_order插入数数据时,同时要把插入的数据同步到machine2、machine3,这就是一致性
2)当其中的一台机器宕机了,可以继续对外提供服务,把宕机的机器重新启动起来可以继续服务,这就是可用性
3)当machine1的机器坏了,数据全部丢失了,不会有任何问题,因为machine2和machine3上还有数据,重新加一台机器machine4,把machine2和machine3其中一台机器的备份数据同步过来就可以了,这就是分区容错性
基本可用(bascially available)、软状态(soft state)、最终一致性(Eventually consistent)
基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)
软状态:允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。
1、这里的中间状态是指不同的data replication之间的数据更新可以出现延时的最终一致性
2、如CAP理论里面的示例,当向machine1的db1的表tbl_person、tbl_order插入数数据时,同时要把插入的数据同步到machine2、machine3,当machine3的网络有问题时,同步失败,但是过一会网络恢复了就同步成功了,这个同步失败的状态就称为软状态,因为最终还是同步成功了。
最终一致性:data replications经过一段时间达到一致性。
5.1 介绍Paxos算法之前我们先来看一个小故事
拜占庭将军问题
拜占庭帝国就是5~15世纪的东罗马帝国,拜占庭即现在土耳其的伊斯坦布尔。我们可以想象,拜占庭军队有许多分支,驻扎在敌人城外,每一分支由各自的将军指挥。假设有11位将军,将军们只能靠通讯员进行通讯。在观察敌人以后,忠诚的将军们必须制订一个统一的行动计划——进攻或者撤退。然而,这些将军里有叛徒,他们不希望忠诚的将军们能达成一致,因而影响统一行动计划的制订与传播。
问题是:将军们必须有一个协议,使所有忠诚的将军们能够达成一致,而且少数几个叛徒不能使忠诚的将军们作出错误的计划——使有些将军进攻而另一些将军撤退。
假设有9位忠诚的将军,5位判断进攻,4位判断撤退,还有2个间谍恶意判断撤退,虽然结果是错误的撤退,但这种情况完全是允许的。因为这11位将军依然保持着状态一致性。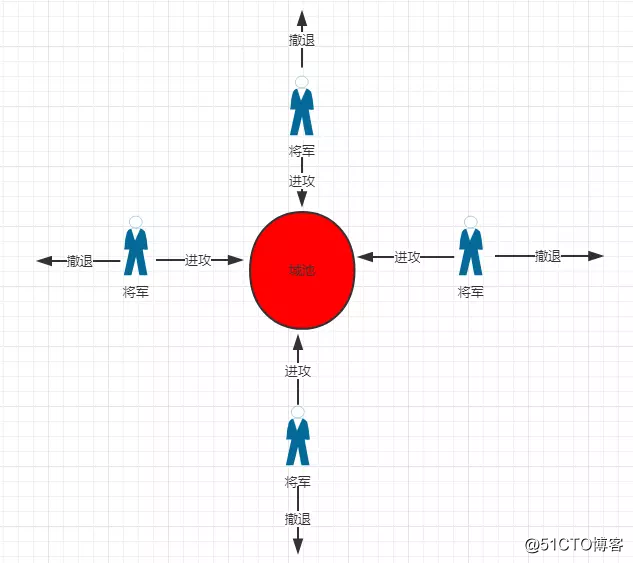
总结:
1)11位将军进攻城池
2)同时进攻(议案、决议)、同时撤退(议案、决议)
3)不管撤退还是进攻,必须半数的将军统一意见才可以执行
4)将军里面有叛徒,会干扰决议生成
5.2 下面就来介绍一下Paxos算法
Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。?
Paxos:多数派决议(最终解决一致性问题)
Paxos算法有三种角色:Proposer,Acceptor,Learner
Proposer:提交者(议案提交者)
??????????提交议案(判断是否过半),提交批准议案(判断是否过半)
Acceptor:接收者(议案接收者)
??????????接受议案或者驳回议案,给proposer回应(promise)
Learner:学习者(打酱油的)
?????????如果议案产生,学习议案。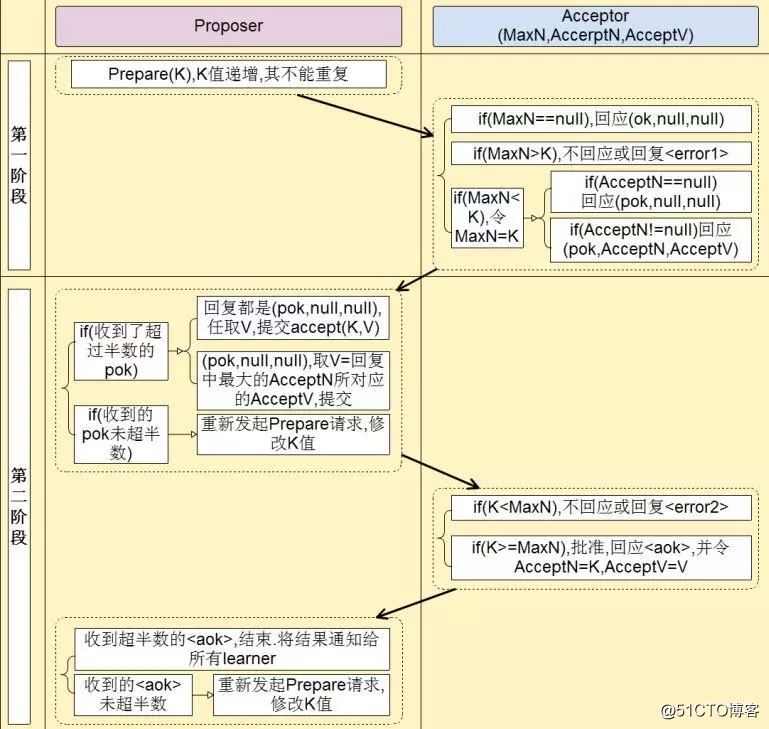
设定1:如果Acceptor没有接受议案,那么他必须接受第一个议案
设定2:每个议案必须有一个编号,并且编号只能增长,不能重复。越往后越大。
设定3:接受编号大的议案,如果小于之前接受议案编号,那么不接受
设定4:议案有2种(提交的议案,批准的议案)
1)Prepare阶段(议案提交)
a)Proposer希望议案V。首先发出Prepare请求至大多数Acceptor。Prepare请求内容为序列号K
b)Acceptor收到Prepare请求为编号K后,检查自己手里是否有处理过Prepare请求。
c)如果Acceptor没有接受过任何Prepare请求,那么用OK来回复Proposer,代表Acceptor必须接受收到的第一个议案(设定1)
d)否则,如果Acceptor之前接受过任何Prepare请求(如:MaxN),那么比较议案编号,如果K<MaxN,则用reject或者error回复Proposer
e)如果K>=MaxN,那么检查之前是否有批准的议案,如果没有则用OK来回复Proposer,并记录K
f)如果K>=MaxN,那么检查之前是否有批准的议案,如果有则回复批准的议案编号和议案内容(如:<AcceptN, AcceptV>, AcceptN为批准的议案编号,AcceptV为批准的议案内容)
2)Accept阶段(批准阶段)
a)Proposer收到过半Acceptor发来的回复,回复都是OK,且没有附带任何批准过的议案编号和议案内容。那么Proposer继续提交批准请求,不过此时会连议案编号K和议案内容V一起提交(<K, V>这种数据形式)
b)Proposer收到过半Acceptor发来的回复,回复都是OK,且附带批准过的议案编号和议案内容(<pok,议案编号,议案内容>)。那么Proposer找到所有回复中超过半数的那个(假设为<pok,AcceptNx,AcceptVx>)作为提交批准请求(请求为<K,AcceptVx>)发送给Acceptor。
c)Proposer没有收到过半Acceptor发来的回复,则修改议案编号K为K+1,并将编号重新发送给Acceptors(重复Prepare阶段的过程)
d)Acceptor收到Proposer发来的Accept请求,如果编号K<MaxN则不回应或者reject。
e)Acceptor收到Proposer发来的Accept请求,如果编号K>=MaxN则批准该议案,并设置手里批准的议案为<K,接受议案的编号,接受议案的内容>,回复Proposer。
f)经过一段时间Proposer对比手里收到的Accept回复,如果超过半数,则结束流程(代表议案被批准),同时通知Leaner可以学习议案。
g) 经过一段时间Proposer对比手里收到的Accept回复,如果未超过半数,则修改议案编号重新进入Prepare阶段。
5.3 Paxos示例
示例1:先后提议的场景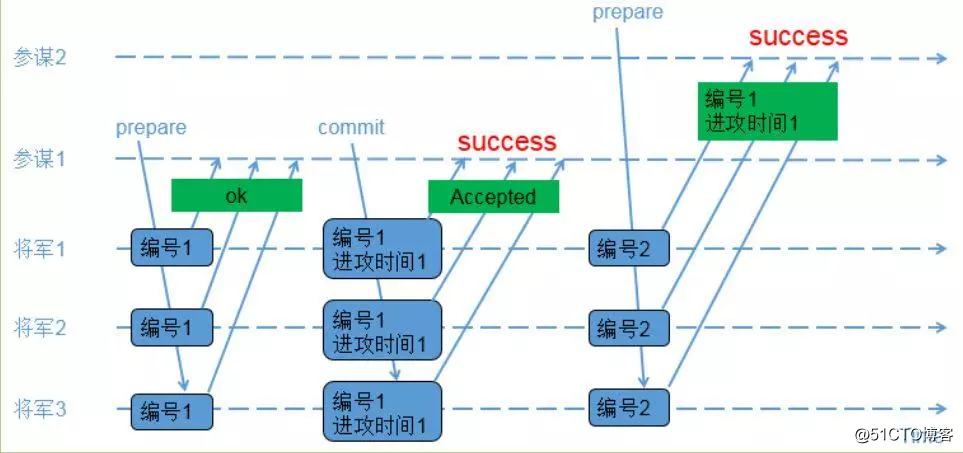
角色:
proposer:参谋1,参谋2
acceptor:将军1,将军2,将军3(决策者)
1)参谋1发起提议,派通信兵带信给3个将军,内容为(编号1);
2)3个将军收到参谋1的提议,由于之前还没有保存任何编号,因此把(编号1)保存下来,避免遗忘;同时让通信兵带信回去,内容为(ok);
3)参谋1收到至少2个将军的回复,再次派通信兵带信给3个将军,内容为(编号1,进攻时间1);
4)3个将军收到参谋1的时间,把(编号1,进攻时间1)保存下来,避免遗忘;同时让通信兵带信回去,内容为(Accepted);
5)参谋1收到至少2个将军的(Accepted)内容,确认进攻时间已经被大家接收;
6)参谋2发起提议,派通信兵带信给3个将军,内容为(编号2);
7)3个将军收到参谋2的提议,由于(编号2)比(编号1)大,因此把(编号2)保存下来,避免遗忘;又由于之前已经接受参谋1的提议,因此让通信兵带信回去,内容为(编号1,进攻时间1);
8)参谋2收到至少2个将军的回复,由于回复中带来了已接受的参谋1的提议内容,参谋2因此不再提出新的进攻时间,接受参谋1提出的时间;
示例2:交叉场景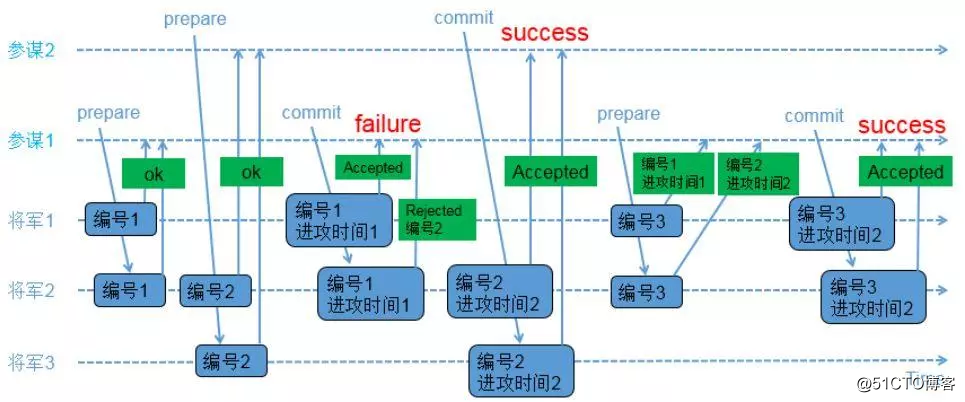
角色:
proposer:参谋1,参谋2
acceptor:将军1,将军2,将军3(决策者)
1)参谋1发起提议,派通信兵带信给3个将军,内容为(编号1);
2)3个将军的情况如下
a)将军1和将军2收到参谋1的提议,将军1和将军2把(编号1)记录下来,如果有其他参谋提出更小的编号,将被拒绝;同时让通信兵带信回去,内容为(ok);
b)负责通知将军3的通信兵被抓,因此将军3没收到参谋1的提议;
3)参谋2在同一时间也发起了提议,派通信兵带信给3个将军,内容为(编号2);
4)3个将军的情况如下
a)将军2和将军3收到参谋2的提议,将军2和将军3把(编号2)记录下来,如果有其他参谋提出更小的编号,将被拒绝;同时让通信兵带信回去,内容为(ok);
b)负责通知将军1的通信兵被抓,因此将军1没收到参谋2的提议;
5)参谋1收到至少2个将军的回复,再次派通信兵带信给有答复的2个将军,内容为(编号1,进攻时间1);
6)2个将军的情况如下
a)将军1收到了(编号1,进攻时间1),和自己保存的编号相同,因此把(编号1,进攻时间1)保存下来;同时让通信兵带信回去,内容为(Accepted);
b)将军2收到了(编号1,进攻时间1),由于(编号1)小于已经保存的(编号2),因此让通信兵带信回去,内容为(Rejected,编号2);
7)参谋2收到至少2个将军的回复,再次派通信兵带信给有答复的2个将军,内容为(编号2,进攻时间2);
8)将军2和将军3收到了(编号2,进攻时间2),和自己保存的编号相同,因此把(编号2,进攻时间2)保存下来,同时让通信兵带信回去,内容为(Accepted);
9)参谋2收到至少2个将军的(Accepted)内容,确认进攻时间已经被多数派接受;
10)参谋1只收到了1个将军的(Accepted)内容,同时收到一个(Rejected,编号2);参谋1重新发起提议,派通信兵带信给3个将军,内容为(编号3);
11)3个将军的情况如下
a)将军1收到参谋1的提议,由于(编号3)大于之前保存的(编号1),因此把(编号3)保存下来;由于将军1已经接受参谋1前一次的提议,因此让通信兵带信回去,内容为(编号1,进攻时间1);
b)将军2收到参谋1的提议,由于(编号3)大于之前保存的(编号2),因此把(编号3)保存下来;由于将军2已经接受参谋2的提议,因此让通信兵带信回去,内容为(编号2,进攻时间2);
c)负责通知将军3的通信兵被抓,因此将军3没收到参谋1的提议;
12)参谋1收到了至少2个将军的回复,比较两个回复的编号大小,选择大编号对应的进攻时间作为最新的提议;参谋1再次派通信兵带信给有答复的2个将军,内容为(编号3,进攻时间2);
13)将军1和将军2收到了(编号3,进攻时间2),和自己保存的编号相同,因此保存(编号3,进攻时间2),同时让通信兵带信回去,内容为(Accepted);
14)参谋1收到了至少2个将军的(accepted)内容,确认进攻时间已经被多数派接受。
四. Zookeeper ZAB协议
Zookeeper Automic Broadcast(ZAB),即Zookeeper原子性广播,是Paxos经典实现
术语:
quorum:集群过半数的集合
looking:选举Leader的状态(崩溃恢复状态下)
following:跟随者(follower)的状态,服从Leader命令
leading:当前节点是Leader,负责协调工作。
observing:observer(观察者),不参与选举,只读节点。
2.?ZAB中的两个模式(ZK是如何进行选举的)
崩溃恢复、消息广播
1)崩溃恢复
leader挂了,需要选举新的leader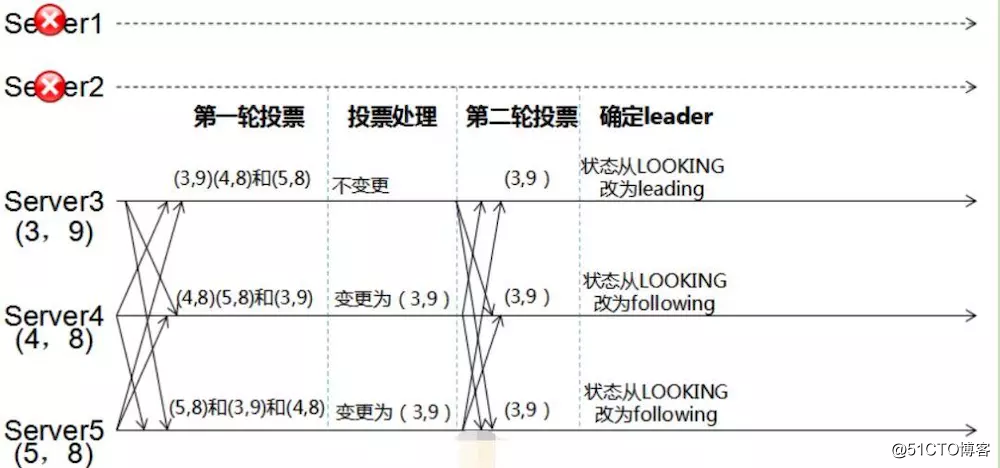
a.每个server都有一张选票,如(3,9),选票投自己。
b.每个server投完自己后,再分别投给其他还可用的服务器。如把Server3的(3,9)分别投给Server4和Server5,一次类推
c.比较投票,比较逻辑:优先比较Zxid,Zxid相同时才比较myid。比较Zxid时,大的做leader;比较myid时,小的做leader
d.改变服务器状态(崩溃恢复->数据同步,或者崩溃恢复->消息广播)
相关概念补充说明:
epoch周期值
acceptedEpoch(比喻:年号):follower已经接受leader更改年号的(newepoch)提议。
currentEpoch(比喻:当前的年号):当前的年号
lastZxid:history中最近接收到的提议zxid(最大的值)
history:当前节点接受到事务提议的log
Zxid数据结构说明:
cZxid = 0x10000001b
64位的数据结构
高32位:10000
Leader的周期编号+myid的组合
低32位:001b
事务的自增序列(单调递增的序列)只要客户端有请求,就+1
当产生新Leader的时候,就从这个Leader服务器上取出本地log中最大事务Zxid,从里面读出epoch+1,作为一个新epoch,并将低32位置0(保证id绝对自增)
2)消息广播(类似2P提交)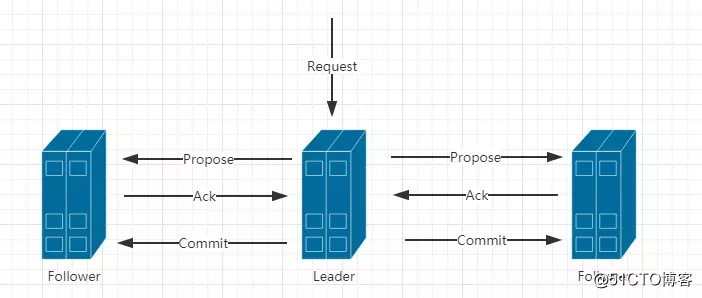
a.Leader接受请求后,将这个请求赋予全局的唯一64位自增Id(zxid)。
b.将zxid作为议案发给所有follower。
c.所有的follower接受到议案后,想将议案写入硬盘后,马上回复Leader一个ACK(OK)。
d.当Leader接受到合法数量(过半)Acks,Leader给所有follower发送commit命令。
e.follower执行commit命令。
注意:到了这个阶段,ZK集群才正式对外提供服务,并且Leader可以进行消息广播,如果有新节点加入,还需要进行同步。
3)数据同步
a.取出Leader最大lastZxid(从本地log日志来)
b.找到对应zxid的数据,进行同步(数据同步过程保证所有follower一致)
c.只有满足quorum同步完成,准Leader才能成为真正的Leader
Zookeeper技术:分布式架构详解、分布式技术详解、分布式事务
标签:不一致 zab 相同 设置 应用 它的 不同 时间 db2
原文地址:http://blog.51cto.com/13981400/2312739