标签:pytho div com off 点击 目标 很多 windows type
前言:
学习python3爬虫大概有一周的时间,熟悉了爬虫的一些基本原理和基本库的使用,本次就准备利用requests库和正则表达式来抓取猫眼电影排行TOP100的相关内容。
1、本次目标:
需要爬去出猫眼电影排行TOP100的电影相关信息,包括:名称、图片、演员、时间、评分,排名。提取站点的URL为http://maoyan.com/board/4,提取的结果以文本形式保存下来。
2、准备工作
只需要安装好requests库即可。
安装方式有很多种,这里只简单的介绍一下通过pip这个包管理工具来安装。
在命令行界面中输入pip3 install requests即可完成安装。(无论是windows、linux、还是mac,都可以使用该方式)
完成之后可以导入requests模块进行测试:
>python Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import requests >>>
如果没有错误提示,就证明已经成功安装了。
3、抓取分析
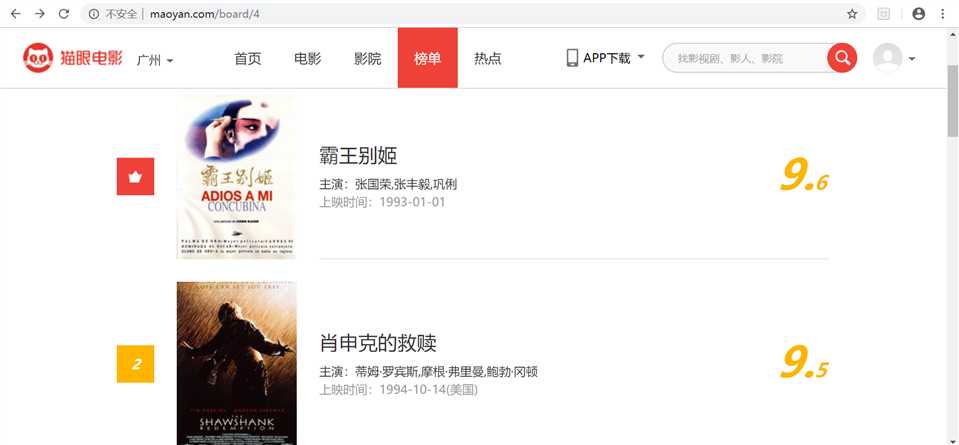
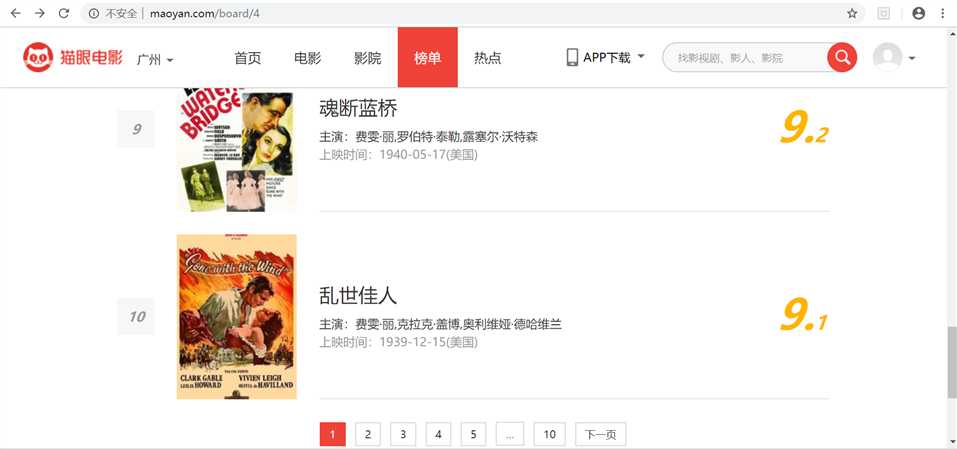
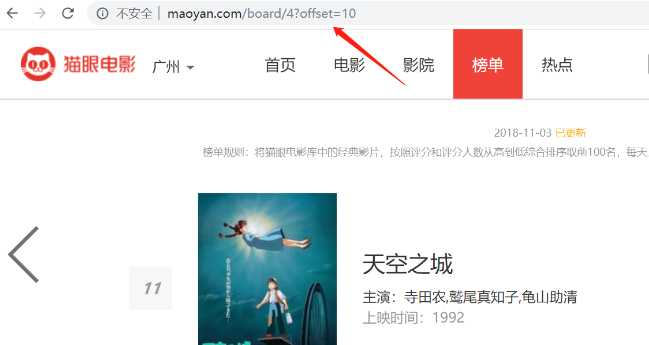
首先进入目标站点http://maoyan.com/board/4,可以看到有电影的排名、演员、时间、评分等信息,翻到页面底部可以发现,每个页面有10部电影,点击下一页可看到站点的URL变为了http://maoyan.com/board/4?offset=10,里面是排名11-20的电影。也就是说要获取TOP100的电影信息,只需要请求offset=0,10,20...90的页面,然后再利用正则表达式爬取每一页所需要的电影信息即可。
标签:pytho div com off 点击 目标 很多 windows type
原文地址:https://www.cnblogs.com/knowing/p/9900879.html