标签:als [] idt 生成 span 聚合 book eth 设定
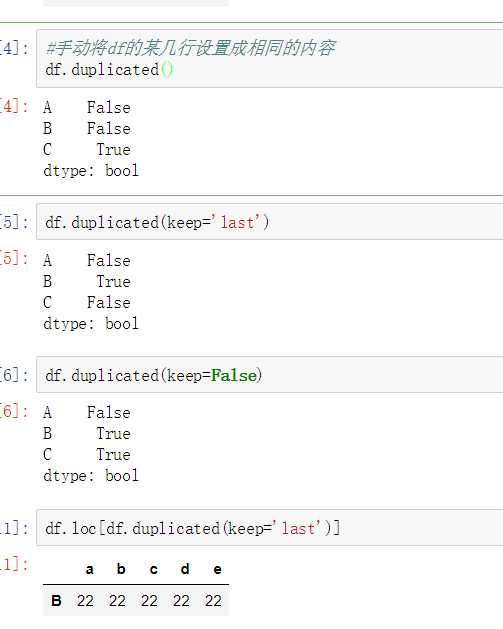
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True。
- keep参数:指定保留哪一重复的行数据
- True 重复的行from pandas import Series,DataFrame import numpy as np import pandas as pd #创建一个df np.random.seed(10) df = DataFrame(data=np.random.randint(0,100,size=(3,5)),index=[‘A‘,‘B‘,‘C‘],columns=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘]) df # a b c d e A 9 15 64 28 89 B 93 29 8 73 0 C 40 36 16 11 54 df.loc[‘B‘] = [‘22‘,‘22‘,‘22‘,‘22‘,‘22‘] df.loc[‘C‘] = [‘22‘,‘22‘,‘22‘,‘22‘,‘22‘] df # a b c d e A 9 15 64 28 89 B 22 22 22 22 22 C 22 22 22 22 22
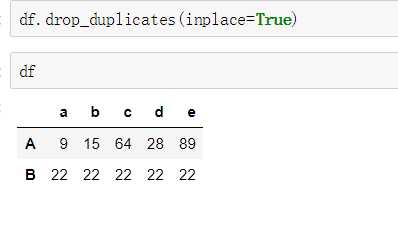
使用drop_duplicates()函数删除重复的行
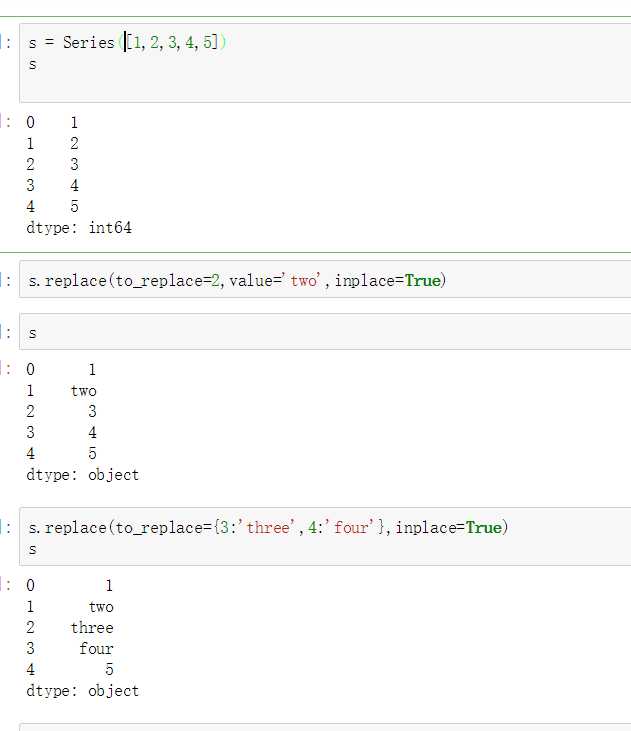
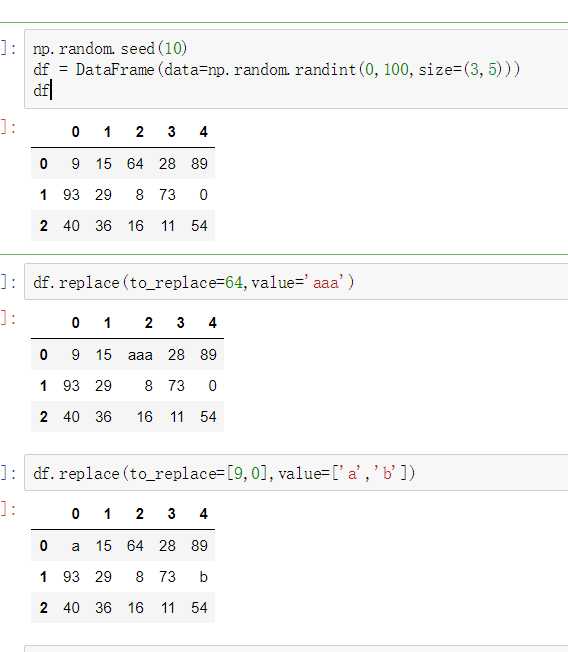
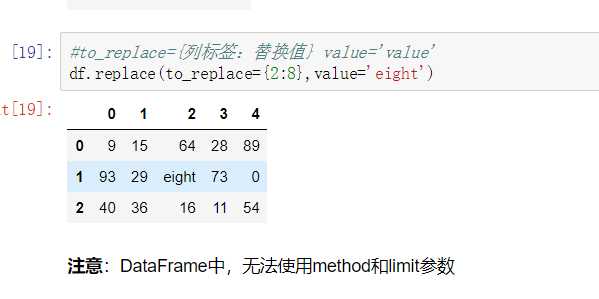
使用replace()函数,对values进行映射操作
单值普通替换
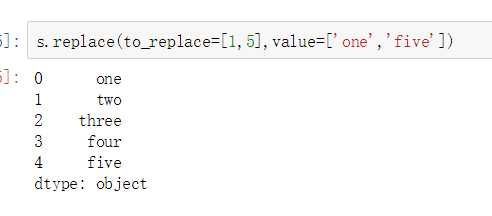
eplace参数说明:
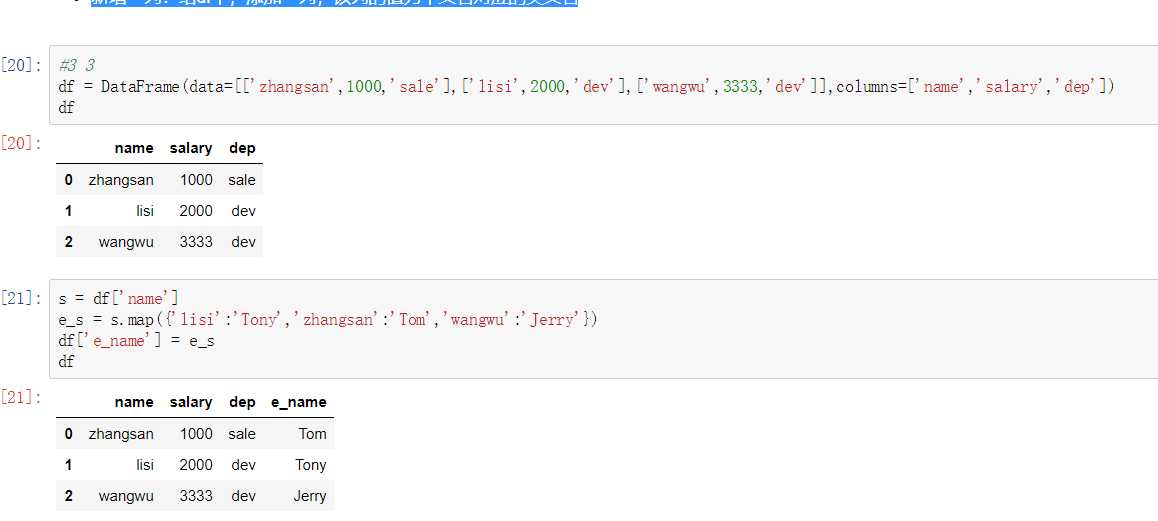
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
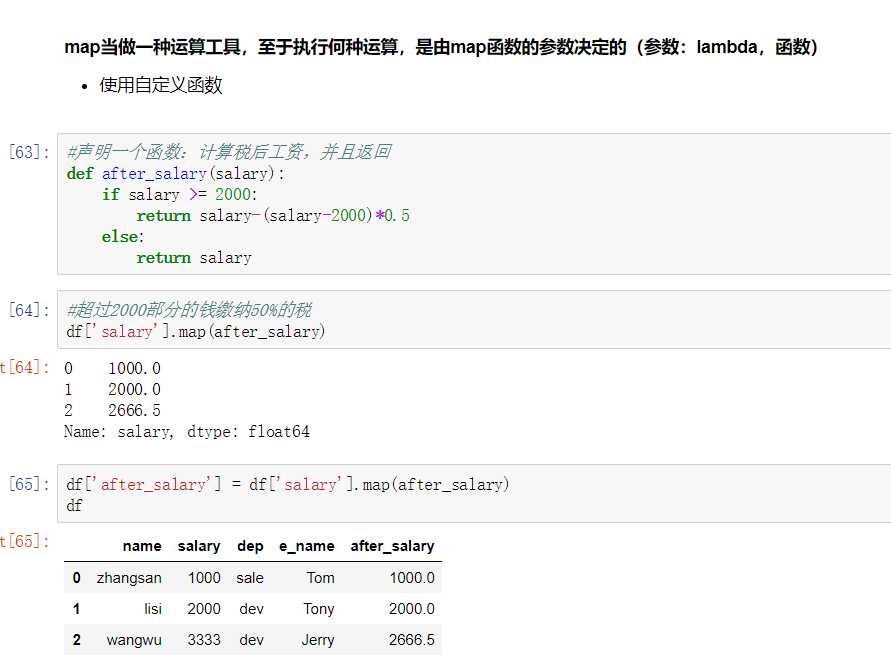
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
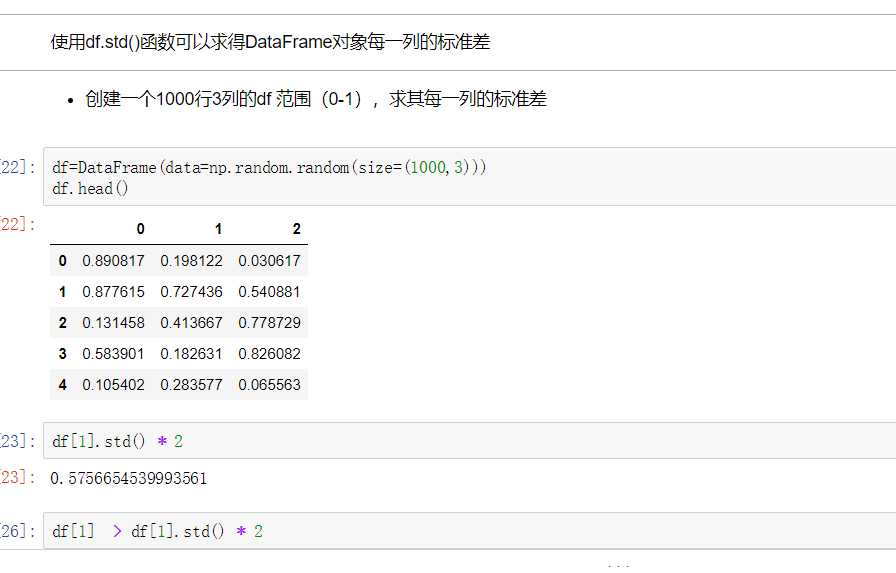

- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序
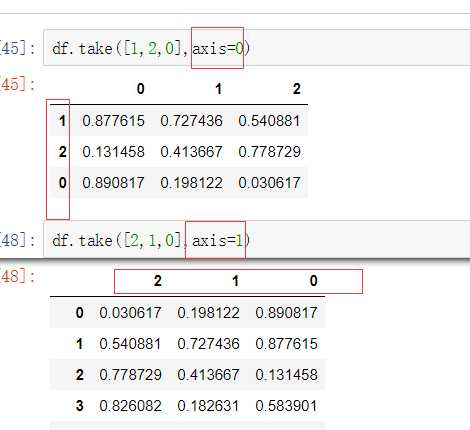
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
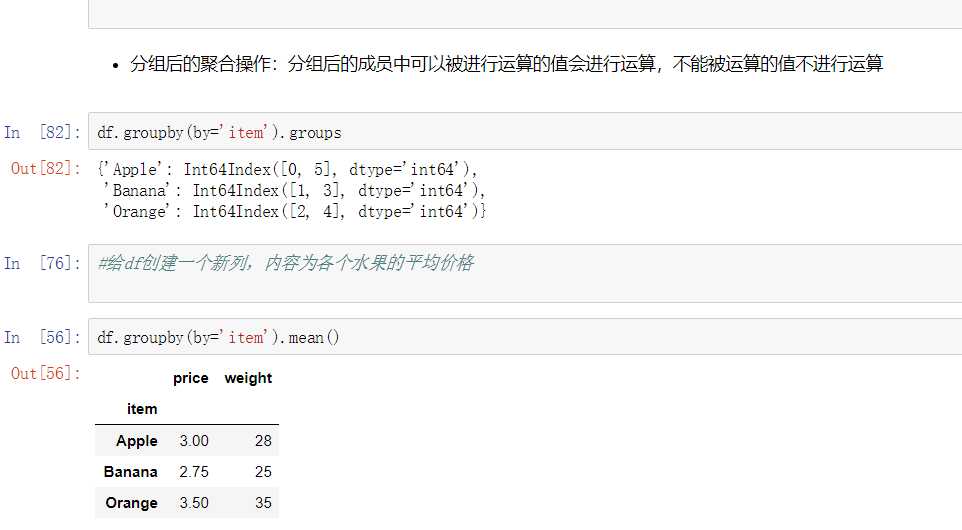
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
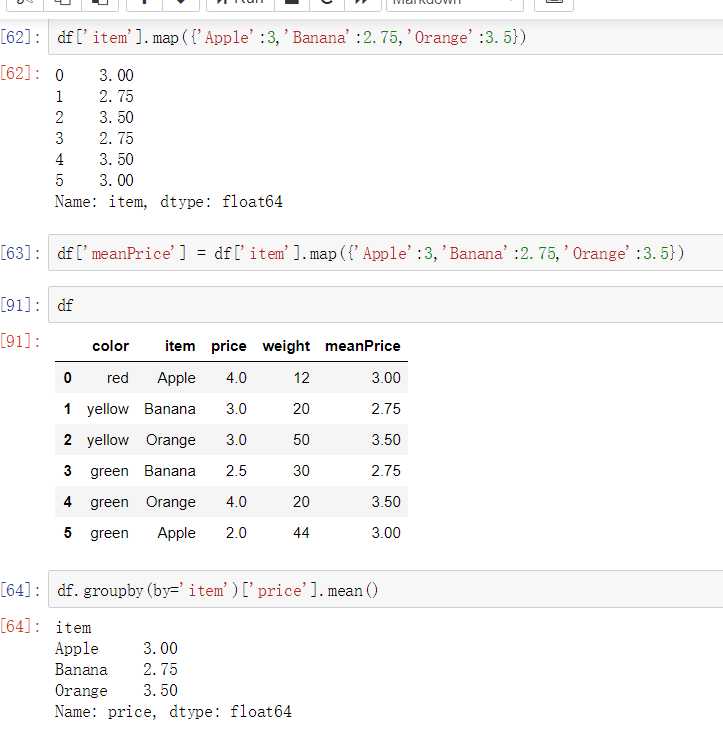
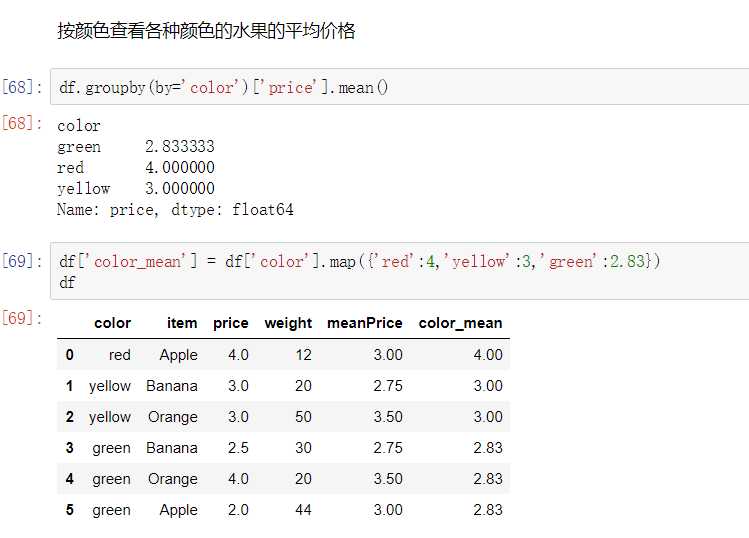
- eg: df.groupby(by=‘item‘).groups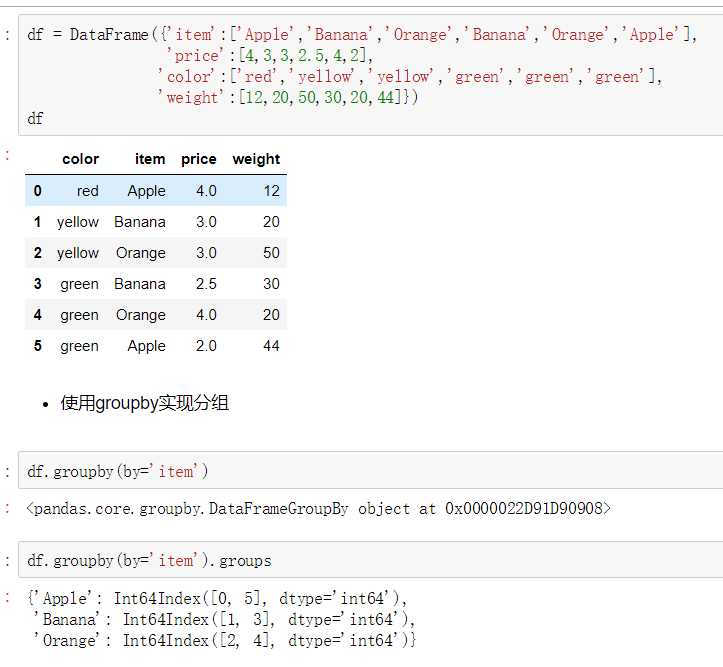
标签:als [] idt 生成 span 聚合 book eth 设定
原文地址:https://www.cnblogs.com/glh-ty/p/9919443.html