标签:shuf 用处 date item 处理器 扩展信息 script 查询 根据
from:https://zhuanlan.zhihu.com/p/31271788
SIMD,即Single Instruction, Multiple Data,一条指令操作多个数据.是CPU基本指令集的扩展.主要用于提供fine grain parallelism,即小碎数据的并行操作.比如说图像处理,图像的数据常用的数据类型是RGB565, RGBA8888, YUV422等格式,这些格式的数据特点是一个像素点的一个分量总是用小于等于8bit的数据表示的.如果使用传统的处理器做计算,虽然处理器的寄存器是32位或是64位的,处理这些数据确只能用于他们的低8位,似乎有点浪费.如果把64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升了8倍.SIMD指令的初衷就是这样的,只不过后来慢慢cover的功能越来越多.
好多处理器都有SIMD指令,我们先仅关注Intel的SIMD.
Intel的初代SIMD指令集是MMX,Multi-Media Extension, 即多媒体扩展,因为它的首要目标是为了支持MPEG视频解码.MMX将64位寄存当作2X32或8X8来用,只能处理整形计算.这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,也就是说MMX指令执行的时候,FPU就没有办法工作.
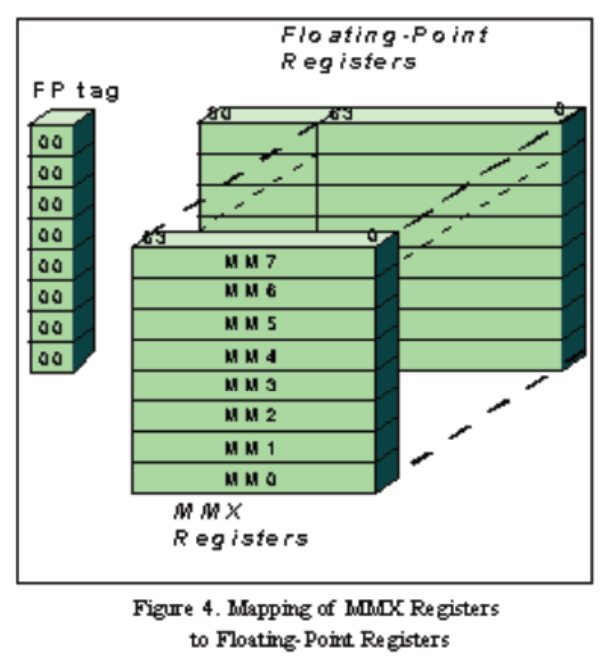
后来Intel进一步实现了SSE, SSE2~SSE4指令集,给了他们单独的寄存器,之后MMX就被停掉了.
SSE, SSE2一直到SSE4,AVX都是一代一代发展过来的,基本上是在原来的基础上增加一些功能,这个增加的过程在网上找到了一张图可以很好的解释.

图中可以看出,SSE首先就是有了属于自己的8个128位长的寄存器,即32x4,可以支持4个单精度浮点数同时计算,这8个寄存器称为XMM0~XMM7, SSE指令要求数据是16byte对齐的.SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.SSE3支持一些更加复杂的算术计算.SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
AVX指令集是Sandy Bridge和Larrabee架构下的新指令集。AVX是在之前的128bit扩展到和256bit的SIMD(Single Instruction, Multiple Data)。而Sandy Bridge的SIMD演算单元扩展到256bits的同时数据传输也获得了提升,所以从理论上看CPU内核浮点运算性能提升到了2倍。
Intel AVX指令集,在SIMD计算性能增强的同时也沿用了的MMX/SSE指令集。不过和MMX/SSE的不同点在于增强的AVX指令,从指令的格式上就发生了很大的变化。x86(IA-32/Intel 64)架构的基础上增加了prefix(Prefix),所以实现了新的命令,也使更加复杂的指令得以实现,从而提升了x86 CPU的性能。
以上来自百度百科。
说起AVX来,还有一个有意思的故事。SSE及其后面的进化过程中一直是增加其后面的数字,即SSE2, SSE3, SSE4,按理说下一次进化应该称为SSE5。实际上SSE5是存在的,只不过仅存在于AMD的处理器里。前几代SSE处理器都是Intel先出,然后AMD跟随,然而到SSE4之后,突然AMD先出了SSE5,抢了Intel的先。Intel不能忍,于是SSE5就没了。
2007年8月,AMD抢先宣布了SSE5指令集(之前从SSE到SSE4均为Intel制定),当时表示该指令集将于2009年推出的Bulldozer处理器中采用。但Intel随即表示,不会支持SSE5。转而在2008年3月,Intel宣布了Sandy Bridge微架构(Intel Tick-Tock策略:45nm Nehalem - 32nm Westmere - 32nm Sandy Bridge),其中将引入全新的AVX指令集。4月份,Intel公布了AVX指令集规范,随后开始不断进行更新。
以上来自再见SSE5 AMD宣布支持Intel AVX指令集-AMD,Intel,AVX-驱动之家
根据Dave Christie的说法,AMD在2007年宣布的SSE5指令集主要包括以下几项革新:3操作数指令甚至4操作数指令,置换与条件移动指令,乘加指令以及其他一系列解决现有SSE指令集缺陷的新指令。
而Intel在2008年4月公布的AVX指令集中,同样包含了SSE5指令集的多项新特性,包括3操作数指令/4操作数指令支持,乘加指令以及部分置换指令等,但实现形式与SSE5不同。并且,AVX指令集还加入了一些SSE5中没有的新特性:SIMD浮点指令长度加倍,为旧版SSE指令增加3操作数指令支持,为未来的指令扩展预留大量OpCode空间等。
由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集,避免让软件开发者因为要面对两套不同指令集而徒增开发难度。
不过,由于AVX指令集的制定权在Intel手中,未来还可能进行修改。AMD只能保证,其首款支持AVX指令集产品支持目前的最新版本:2009年1月发布的AVX第五版规范。并且,FMA乘加指令只支持到2008年8月的AVX第三版规范。
由于SIMD指令有多个版本,每个版本支持的指令集不同。所以如果你的软件要支持更多的CPU,就要在使用SIMD指令之前知道当前指令运行所在的CPU是否支持这条指令。
x86/x86_64 提供了CPUID指令,可以通过这个指令查询当前CPU指令支持SSE指令集情况。
CPUID指令可以用来查询CPU的好多东西,Intel有一个超过100页的文档,专门介绍cpuid这条指令。这里我们仅介绍一下SSE相关的内容,后面如有机会也可以专门介绍一下这条指令。
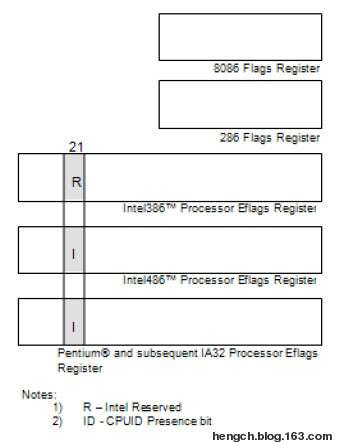
首先, CPUID指令是从80486开始才有,之前的CPU没有这条指令,当然这个问题大家大可不必担心,因为你能用到486之前的处理器的机会机乎没有,除非你用模拟器去专门模拟这个处理器。
在EFLAGS中的bit 21可以识别CPU是否支持CPUID指令,如下图:
 图片来自图片上的水印,呵呵
图片来自图片上的水印,呵呵
CPUID指令的使用有点类似于一个函数调用,你传一个参数给CPUID,然后CPUID指令执行后将一些返回值返回给你。你通过EAX寄存器传参数给CPUID指令,CPUID指令执行完后通过EAX, EBX, ECX, EDX返回给你想的数据。
当输入EAX==0x1时,EDX返回的扩展信息解释如下:
位 标号 解释
0 FPU Floating Point Unit On-Chip. CPU是否内置浮点计算单元
1 VME Virtual 8086 Mode Enhancements. 是否支持虚拟8086模式
2 DE Debugging Extensions. 是否支持调试功能.
3 PSE Page Size Extension. 是否支持大于4MB的分页.
4 TSC Time Stamp Counter. 是否支持RDTSC指令.(注:RDTSC指令可以计算出CPU的频率)
5 MSR Module Specific Registers RDMSR and WRMSR Instructions. 是否支持RDMSR与WRMSR (*注1)
6 PAE Physical Address Extension. 是否支持大于32bit的物理地址.
7 MCE Machine Check Exception. (*注2)
8 CX8 CMPXCHG8B Instruction. 是否支持8bytes(64bit)数的比较与交换指令.
9 APIC APIC On-Chip.是否支持APIC(Advanced Programmable Interrupt Controller)
10 保留
11 SEP SYSENTER and SYSEXIT Instructions.是否支持SYSENTER与SYSEXIT指令.(*注3)
12 MTRR Memory Type Range Registers. 是否支持MTTR(*注4)
13 PGE PTE Global Bit. 是否支持全局页面目录入口标志位 (global bit in page directory entries)
14 MCA Machine Check Architecture. 是否支持MCA,MCA是Pentium4,Xeon,P6级处理器的一个错误报告机制
15 CMOV Conditional Move Instructions. CMOV指令是否可用.
16 PAT Page Attribute Table. 是否支持PAT,PAT允许操作系统指定4K大小的线性内存空间
17 PSE-36 32-bit Page Size Extension. 是否支持4GB的扩展内存
18 PSN Processor Serial Number. 是否支持处理器序列号.(P3有效)
19 CLFSH CLFLUSH Instruction.是否支持CLFLUSH.(*注5)
20 保留
21 DS Debug Store. 是否支持把调试信息写入缓存,
22 ACPI ACPI Processor Performance Modulation Registers. 处理器使用特别的寄存器以允许软件控制处理器的运行周期.
23 MMX Inter MMX Technology.是否支持MMX
24 FXSR FXSAVE and FXRSTOR Instructions. FXSAVE与FXRSTOR指令是否可用(*注6)
25 SSE SSE.是否支持SSE.
26 SSE2 是否支持SSE2.
27 SS Self Snoop. 处理器是否支持总线监视,以防止储存器冲突.
28 保留
29 TM Thermal Monitor.CPU是否支持温度控制.
30 & 31 保留
ECX定义如下(资料来自Intel):
bit Name Description
---------------------------------------------------------
00 SSE3 Streaming SIMD Extensions 3
01 Reserved
02 DTES64 64-Bit Debug Store
03 MONITOR MONITOR/MWAIT
04 DS-CPL CPL Qualified Debug Store
05 VMX Virtual Machine Extensions
06 SMX Safer Mode Extensions
07 EST Enhanced Intel SpeedStep? Technology
08 TM2 Thermal Monitor 2
09 SSSE3 Supplemental Streaming SIMD Extensions 3
10 CNXT-ID L1 Context ID
12:11 Reserved
13 CX16 CMPXCHG16B
14 xTPR xTPR Update Control
15 PDCM Perfmon and Debug Capability
17:16 Reserved
18 DCA Direct Cache Access
19 SSE4.1 Streaming SIMD Extensions 4.1
20 SSE4.2 Streaming SIMD Extensions 4.2
21 x2APIC Extended xAPIC Support
22 MOVBE MOVBE Instruction
23 POPCNT POPCNT Instruction
25:24 Reserved
26 XSAVE XSAVE/XSTOR States
27 OSXSAVE
28 AVX
31:29 Reserved
以上可能好多位的含义大家见都没见过,但只关注SSE~AVX的使能标志就可以了,后面有机会的话,大家会一一了解。
一个MMX指令来实现乘累加操作是这样婶儿的:

这是一个PMADD指令,后缀WD是word的意思,即操作数长度为word,即16位,在这个示例中,指令完成了两个乘累加操作,结果为两个32位数,放在一个64位寄存器里.示例是城的a0, a1, a2,a3都是16位数.
这个操作的用处可多了,什么FFT啊,DCT呀都用得着.

SSE指令的控制更加精细,比如说Single Scalar和Packed Scalar的区别.Single Scalar(-ss后缀)乘法中,四组操作数中有一组操作数进行了计算,其他操作数不动.Packed-Scalar(-ps后缀)乘法中,四组操作数都参与计算.
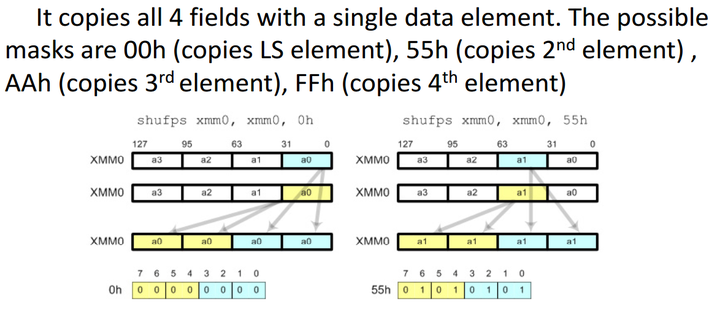
shuffle就是对数据重排,比如说常用的shufps,它将四个字段都复制一份同样的值.
使用SIMD指令有三种方法,(1)最简单的方法就是我们写C/C++代码,让编译器自己转化。写代码的时候遵守某些规则可以帮助编译器尽量吧。(2)使用编译器提供的intrinsic,即编译器实现了一些内置函数和类型,使用它们的时候,对应的操作会翻译成SIMD指令。(3)写汇编代码或是C语言嵌入汇编代码。
具体用法网上一搜一大堆,就不抄了。
SIMD指令集——一条指令操作多个数,SSE,AVX都是,例如:乘累加,Shuffle等
标签:shuf 用处 date item 处理器 扩展信息 script 查询 根据
原文地址:https://www.cnblogs.com/bonelee/p/9920610.html