标签:生成 定义 路径 界面 笔记本电脑 pager 微观经济学 soc 压力
https://mp.weixin.qq.com/s/tHRl5OQHY2mNXqKwACCVWw?utm_source=tuicool&utm_medium=referral
一、架构的三个维度和六个层面
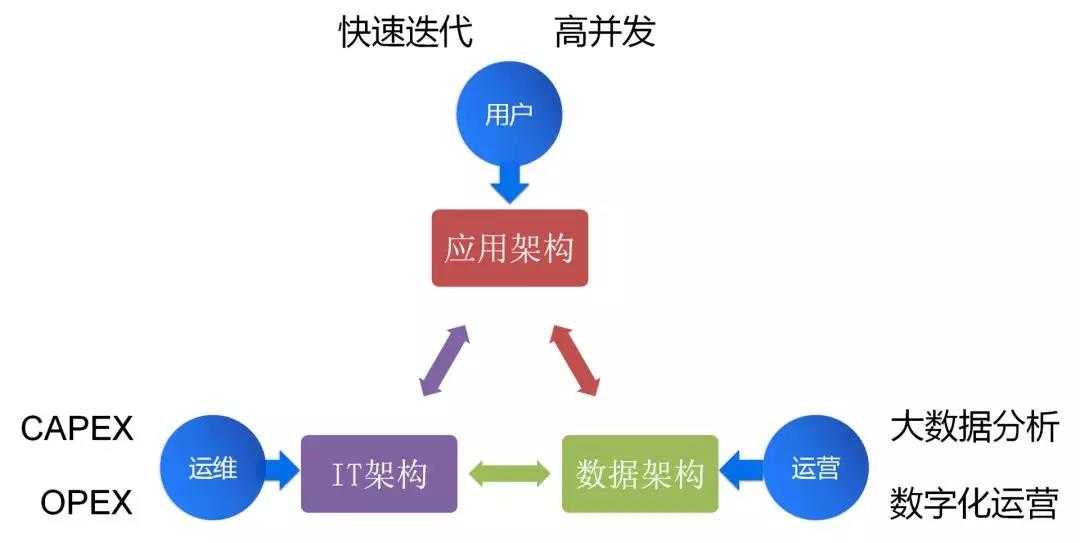
1.1、三大架构
在互联网时代,要做好一个合格的云架构师,需要熟悉三大架构。
第一个是IT架构,其实就是计算,网络,存储。这是云架构师的基本功,也是最传统的云架构师应该首先掌握的部分,良好设计的IT架构,可以降低CAPEX和OPEX,减轻运维的负担。数据中心,虚拟化,云平台,容器平台都属于IT架构的范畴。
第二个是应用架构,随着应用从传统应用向互联网应用转型,仅仅搞定资源层面的弹性还不够,常常会出现创建了大批机器,仍然撑不住高并发流量。因而基于微服务的互联网架构,越来越成为云架构师所必需的技能。良好设计的应用架构,可以实现快速迭代和高并发。数据库,缓存,消息队列等PaaS,以及基于SpringCloud和Dubbo的微服务框架,都属于应用架构的范畴。
第三个是数据架构,数据成为人工智能时代的核心资产,在做互联网化转型的同时,往往进行的也是数字化转型,并有战略的进行数据收集,这就需要云架构师同时又大数据思维。有意识的建设统一的数据平台,并给予数据进行数字化运营。搜索引擎,Hadoop,Spark,人工智能都属于数据架构的范畴。
1.2、六个层面
上面的三个维度是从人的角度出发的,如果从系统的角度出发,架构分六个层次。
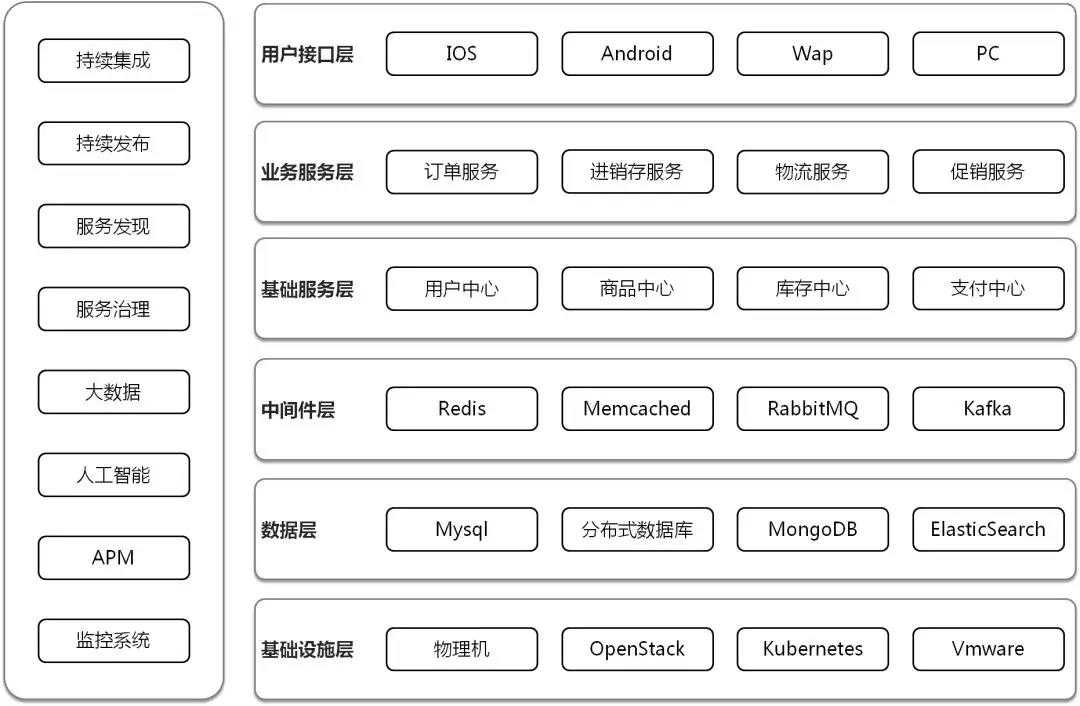
第一个层次是基础设施层,在数据中心里面,会有大量的机架,大量的服务器,并通过交换机和路由器将服务器连接起来,有的应用例如Oracle是需要部署在物理机上的。为了管理的方便,在物理机之上会部署虚拟化,例如Vmware,可以将对于物理机复杂的运维简化为虚拟机灵活的运维。虚拟化采取的运维方式多是由运维部门统一管理,当一个公司里面部门非常多的时候,往往要引入良好的租户管理,基于Quota和QoS的资源控制,基于VPC的网络规划等,实现从运维集中管理到租户自助使用模式的转换,托生于公有云的OpenStack在这方面做的是比较好的。随着应用架构越来越重要,对于标准化交付和弹性伸缩的需求越来越大,容器最为软件交付的集装箱,可以实现基于镜像的跨环境迁移,Kubernetes是容器管理平台的事实标准。
第二个层次是数据层,也即一个应用的中军大营,如果是传统应用,可能会使用Oracle,并使用大量的存储过程,有大量的表联合查询,成本也往往比较高。但是对于高并发的互联网应用,需要进行微服务的拆分,数据库实例会比较多,使用开源的Mysql是常见的选择,大量的存储过程和联合查询往往会使得微服务无法拆分,性能会比较差,因而需要放到应用层去做复杂的业务逻辑,数据库表和索引的设计非常重要。当并发量比较大的时候,需要实现横向扩展,就需要基于分布式数据库,也是需要基于单库良好的表和索引设计。对于结构比较灵活的数据,可以使用MongoDB数据库,横向扩展能力比较好。对于大量的联合查询需求,可以使用ElasticSearch之类的搜索引擎来做,速度快,更加灵活。
第三个层次是中间件层,因为数据库层往往需要保证数据的不丢失以及一些事务,因而并发性能不可能非常大,所以我们经常说,数据库是中军大营,不能所有的请求都到这里来,因而需要一层缓存层,用来拦截大部分的热点请求。Memcached适合做简单的key-value存储,内存使用率比较高,而且由于是多核处理,对于比较大的数据,性能较好。但是缺点也比较明显,Memcached严格来讲没有集群机制,横向扩展完全靠客户端来实现。另外Memcached无法持久化,一旦挂了数据就都丢失了,如果想实现高可用,也是需要客户端进行双写才可以。Redis的数据结构比较丰富,提供持久化的功能,提供成熟的主备同步,故障切换的功能,从而保证了高可用性。另外微服务拆分以后,有时候处理一个订单要经过非常多的服务,处理过程会比较慢,这个时候需要使用消息队列,让服务之间的调用变成对于消息的订阅,实现异步处理。RabbitMQ和Kafka是常用的消息队列,当事件比较重要的时候,会结合数据库实现可靠消息队列。
第四个层次是基础服务层,有的时候成为中台层,将通用的能力抽象为服务对外提供原子化接口。这样上层可以根据业务需求,通过灵活的组合这些原子化接口,灵活的应对业务需求的变化,实现能力的复用,以及数据的统一管理,例如用户数据,支付数据,不会分散到各个应用中。另外基础服务层称为应用和数据库和缓存的一个分界线,不应该所有的应用都直接连数据库,一旦出现分库分表,数据库迁移,缓存选型改变等,影响面会非常大,几乎无法执行。如果将这些底层的变更拦截在基础服务层,上层仅仅使用基础服务层的接口,这样底层的变化会对上层透明,可以逐步演进。
第五个层次是业务服务层,或者组合服务层,大部分的业务逻辑都是在这个层面实现,业务逻辑比较面向用户,因而会经常改变,所以需要组合基础服务的接口进行实现。在这一层,会经常进行服务的拆分,实现开发独立,上线独立,扩容独立,容灾降级独立。微服务的拆分不应该是一个运动,而应该是一个遇到耦合痛点的时候,不断解决,不断演进的一个过程。微服务拆分之后,有时候需要通过分布式事务,保证多个操作的原子性,也是在组合服务层来实现的。
第六个层次是用户接口层,也即对终端客户呈现出来的界面和APP,但是却不仅仅是界面这么简单。这一层有时候称为接入层。在这一层,动态资源和静态资源应该分离,静态资源应该在接入层做缓存,使用CDN进行缓存。也应该UI和API分离,界面应该通过组合API进行数据拼装。API会通过统一的API网关进行统一的管理和治理,一方面后端组合服务层的拆分对APP是透明的,一方面当并发量比较大的时候,可以在这一层实现限流和降级。
为了支撑这六个层次,在上图的左侧是一些公共能力。
持续集成和持续发布是保证微服务拆分过程中的快速迭代,以及变更后保证功能不变的,不引入新的Bug。
服务发现和服务治理是微服务之间互相的调用,以及调用过程中出现异常情况下的熔断,限流,降级策略。
大数据和人工智能是通过收集各个层面的数据,例如用户访问数据,用户下单数据,客服询问数据等,结合统一的中台,对数据进行分析,实现智能推荐。
监控与APM是基础设施的监控和应用的监控,发现资源层面的问题以及应用调用的问题。
作为一个云架构师还是很复杂的,千里之行,始于足下,让我们慢慢来。
二、了解云计算的历史演进与基本原理
在一头扎进云计算的汪洋大海之前,我们应该先有一个全貌的了解,有人说了解一个知识的起点,就是了解他的历史,也就是知道他是如何一步一步到今天的,这样如此庞大的一个体系,其实是逐步加进来的,这样的知识体系对我们来说,就不是一个冷冰冰的知识网,而是一个有血有肉的人,我们只要沿着演进的线索,一步一步摸清楚他的脾气就可以了。
如何把云计算讲的通俗易懂,我本人思考了半天,最终写下了下面这篇文章。
在这里,我把核心的要点在这里写一下:
第一:云计算的本质是实现从资源到架构的全面弹性。所谓的弹性就是时间灵活性和空间灵活性,也即想什么时候要就什么时候要,想要多少就要多少。
资源层面的弹性也即实现计算、网络、存储资源的弹性。这个过程经历了从物理机,到虚拟化,到云计算的一个演进过程。
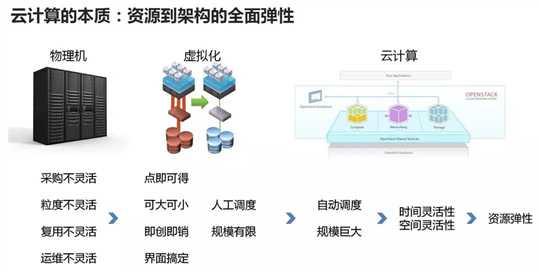
架构层面的弹性也即实现通用应用和自有应用的弹性扩展。对于通用的应用,多集成为PaaS平台。对于自己的应用,通过基于脚本的Puppet, Chef, Ansible到基于容器镜像的容器平台CaaS。
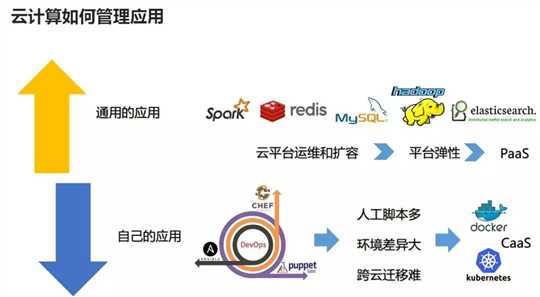
第二:大数据包含数据的收集,数据的传输,数据的存储,数据的处理和分析,数据的检索和挖掘等几个过程。
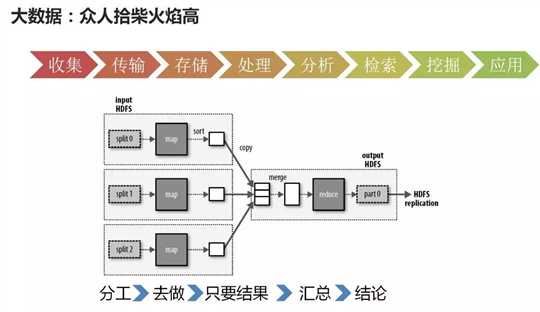
当数据量很小时,很少的几台机器就能解决。慢慢的,当数据量越来越大,最牛的服务器都解决不了问题时,怎么办呢?这时就要聚合多台机器的力量,大家齐心协力一起把这个事搞定,众人拾柴火焰高。
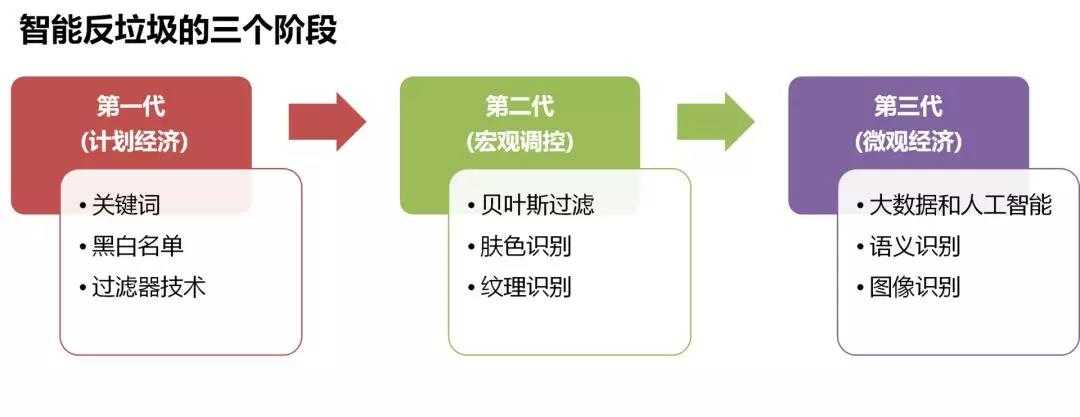
第三:人工智能经历了基于专家系统的计划经济,基于统计的宏观调控,基于神经网络的微观经济学三个阶段。
三、开源软件是进阶的利器
架构师除了要掌握大的架构和理论之外,指导落地也是必备的技能,所谓既要懂设计模式,也要懂代码。那从哪里去学习这些良好的,有借鉴意义的,可以落地的架构实践呢?
这个世界上还是有很多有情怀的大牛的,尤其是程序员里面,他们喜欢做一件什么事情呢?开源。很多软件都是有闭源就有开源,源就是源代码。当某个软件做的好,所有人都爱用,这个软件的代码呢,我封闭起来只有我公司知道,其他人不知道,如果其他人想用这个软件,就要付我钱,这就叫闭源。但是世界上总有一些大牛看不惯钱都让一家赚了去。大牛们觉得,这个技术你会我也会,你能开发出来,我也能,我开发出来就是不收钱,把代码拿出来分享给大家,全世界谁用都可以,所有的人都可以享受到好处,这个叫做开源。
非常建议大家了解,深入研究,甚至参与贡献开源软件,因为收益匪浅。
第一:通过开源软件,我们可以了解大牛们的架构原则,设计模式。
其实咱们平时的工作中,是很难碰到大牛的,他可能是你渴望而不可及的公司的员工,甚至在国外,你要想进这种公司,不刷个几年题目,面试个N轮是进不去的。即便进去了,他可能是公司的高层,每天很忙,不怎么见得到他,就算当面讨教,时间也不会很长,很难深入交流。也有的大牛会选择自主创业,或者是自由职业者,神龙见首不见尾,到了大公司都见不到。
但是感谢互联网和开源社区,将大牛们拉到了我们身边,你可以订阅邮件组,可以加入讨论群,可以看到大牛们的设计,看到很多人的评论,提问,还有大牛的回答,可以看到大牛的设计也不是一蹴而就完美的,看到逐渐演进的过程,等等。这些都是能够帮助我们快速提升水平的地方,有的时候,拿到一篇设计,都要查资料看半天,一开始都可能好多的术语都看不懂,没关系肯下他,当你看blueprints越来越顺畅的时候,你就进步了。
第二:通过开源软件,我们可以学习到代码级的落地实践。
有时候我们能看到很多大牛写的书和文章,也能看到很多理论的书籍,但是存在一个问题是,理论都懂,但是还是做不好架构。这是因为没有看到代码,所有的理论都是空中楼阁,当你到了具体的代码设计层面,那些学会的设计模式,无法转化为你自己的实践。
好在开源软件的代码都是公开的,凝结了大牛的心血,也能够看到大牛在具体落地时候的取舍,一切那么真实,看得见,摸得着。通过代码进行学习,配合理论知识,更容易获得第一手的经验,并且在自己做设计和写代码的时候,马上能够映射到可以参考的场景,让我们在做自己的系统的时候,少走弯路。
第三:通过开源软件,我们可以加入社区,和其他技术人员在同一背景下共同进步
大牛我们往往不容易接触到,正面讨论技术问题的时间更是难能可贵,但是没有关系,开源软件构建了一个社区,大家可以在一起讨论,你是怎么理解的,别人是怎么理解的,越讨论越交流,越明晰,有时候和比你经验稍微丰富一点的技术人员交流,可能比直接和大牛对话更加有直接作用。大牛的话可能让你消化半天,依然不知所云,大牛可能觉得很多普通人觉得的难点是显而易见的,不屑去解释。但是社区里面的技术人员,可能和你一样慢慢进步过来的,知道哪些点是当年自己困惑的,如果踩过这一个个的坑,他们一点拨,你就会豁然开朗。
而且每个人遇到的具体情况不同,从事的行业不同,客户的需求不同,因而软件设计的时候考虑的因素不同,大牛是牛,但是不一定能够遇到和你一样的场景,但是社区里面,有你的同行业的,背景相近的技术人员,你们可以讨论出符合你们特定场景的解决方案。
第四:通过开源软件,我们作为个人,比较容易找到工作
我们面试的时候,常常遇到的问题是,怎么能够把在原来工作中自己的贡献,理解,设计,技术能力。其实我发现很多程序员不能很好的做的这一点,所以造成很多人面试很吃亏。原因之一是背景信息不对称,例如原来面临的业务上很难的问题,面试官由于不理解背景,而且短时间解释不清楚,而轻视候选人的水平,我也遇到过很多面试官才听了几分钟,就会说,这不挺简单的,你这样这样不就行了,然后彻底否定你们一个团队忙了三年的事情。原因之二是很多有能力的程序员不会表达,导致真正写代码的说不明白,可能原来在公司里面一个绩效非常好,一个绩效非常差,但是到了面试官那里就拉平了。原因之三是新的公司不能确定你在上家公司做的工作,到这一家都能用的,例如你做的工作有30%是和具体业务场景相关的,70%是通用技术,可能下家公司只会为你的通用技术部分买单。
开源软件的好处就是,参与的人所掌握的技能都是通的,而且大家在同一个上下文里面对话,面试官和候选人之间的信息差比较少。掌握某个开源软件有多难,不用候选人自己说,大家心里都有数。
对于很多技术能力强,但是表达能力较弱的极少数人员来讲,talk is cheap, show me the code,代码呈上去,就能够表现出实力来了,而且面试官也不需要根据短短的半个小时了解一个人,可以做很多背景调查。
另外由于掌握的技术的通用的,你到下一家公司,马上就能够上手,几乎不需要预热时间,对于双方都有好处。
第五:通过开源软件,我们作为招聘方,比较容易招到相应人员。
如果在创业公司待过的朋友会了解到创业公司招人很难,人员流失很快,而且创业公司往往对于开发进度要求很快,因为大家都在抢时间。因而开源软件对于招聘方来讲,也是好消息。首先创业公司没办法像大公司一样,弄这么多的技术大牛,自己完全落地一套自己的体系,使用开源软件快速搭建一套平台先上线是最好的选择。其次使用开源软件,会使得招聘相对容易,市场上火的开源软件会有大批的从业者,参与各种论坛和社区,比较容易挖到人。最后,开源软件的使用使得新人来了之后没有预热时间,来了就上手,保证开发速度。
那如何快速上手一款开源软件呢?我写了一篇文章
在这篇文章中,我总结了九个步骤。
一、手动安装起来,一定要手动
二、使用一下,推荐XXX in Action系列
三、读文档,读所有的官方文档,记不住,看不懂也要读下来
四、了解核心的原理和算法,推荐XXX the definitive guide系列
五、看一本源码分析的书,会让你的源码阅读之旅事半功倍
六、开始阅读核心逻辑源代码
七、编译并Debug源代码
八、开发一个插件,或者对组件做少量的修改
九、大量的运维实践经验和面向真实场景的定制开发
所以做一个云架构师,一定不能脱离代码,反而要不断的拥抱开源软件。
四、了解Linux基础知识
作为一个云架构师,首要的一点,就是要熟悉Linux的基础知识,基本原理了。
说到操作系统,一般有三个维度,一个是桌面操作系统,一个是移动操作系统,一个是服务器操作系统。
Stack Overflow Developer Survey 2018有这样一个统计,对于开发人员来说,桌面操作系统的排名是Windows,MacOS,Linux,所以大部分人平时的办公系统都是windows。
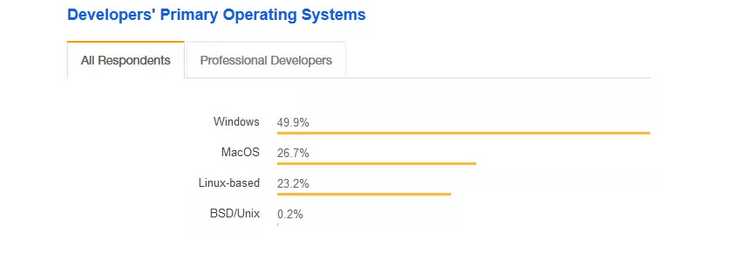
当然因为办公的原因,平时使用windows的比较多,所以在学校里,很多同学接触到的操作系统基本上都是Windows,但是一旦从事计算机行业,就一定要跨过Linux这道坎。
根据今年W3Techs的统计,对于服务器端,Unix-Like OS占到的比例为近70%。所谓Unix-Like OS 包括下图的Linux,BSD等一系列。
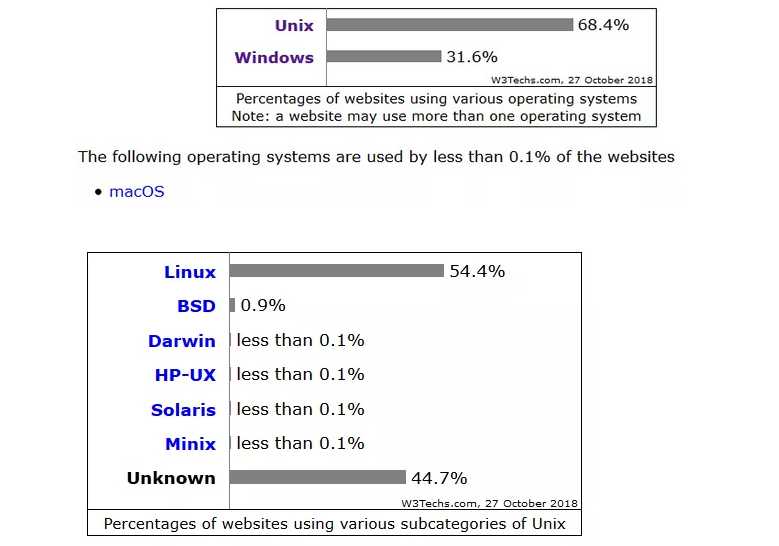
从这个统计可以看出,随着云计算的发展,软件SaaS化,服务化,甚至微服务化,大部分的计算都是在服务端做的,因而要成为云架构师,就必须懂Linux。
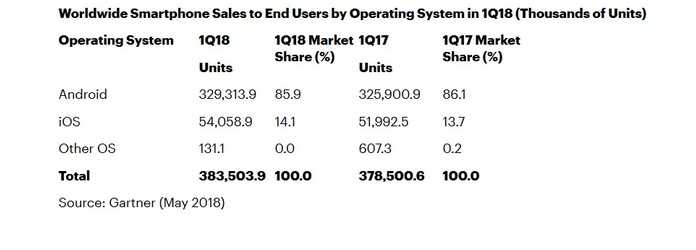
随着移动互联网的发展,客户端基本上以Android和iOS为主,下图是Gartner的统计。Android是基于Linux内核的。因而客户端也进入了Linux阵营,很多智能终端,智能设备等开发职位,都需要懂Linux的人员。
学习Linux主要包含两部分,一个是怎么用,一个是怎么编程,背后原理是什么。
对于怎么用,上手的话,推荐《鸟哥的Linux私房菜》,按着这个手册,就能够学会基本的Linux的使用,如果再深入一点,推荐《Linux系统管理技术手册》,砖头厚的一本书,是Linux运维手边必备。
对于怎么编程,上手的话,推荐《UNIX环境高级编程》,有代码,有介绍,有原理,如果对内核的原理感兴趣,推荐《深入理解LINUX内核》。
Linux的架构如下图
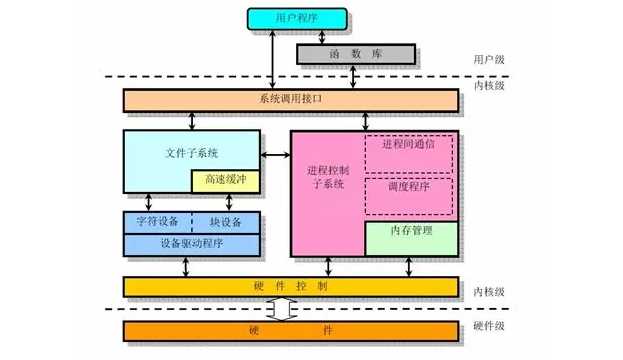
我们知道,一台物理机上有很多的硬件,最重要的是CPU,内存,硬盘,网络,但是一个物理机上要跑很多的程序,这些资源应该给谁用呢?当然是大家轮着用,谁也别独占,谁也别饿死。为了完成这件事情,操作系统的内核就起到了大管家的作用,将硬件资源分配给不同的用户程序使用,并且在适当的时间将资源拿回来,再分配给其他的用户进程,这个过程称为调度。
操作系统的功能之一是系统调用
当用户程序想请求资源的时候,需要调用操作系统的系统调用接口,这是内核和用户态程序的分界线,就像你要打车,要通过打车软件的界面,下发打车指令一样,这样打车软件才会给你调度一辆车。
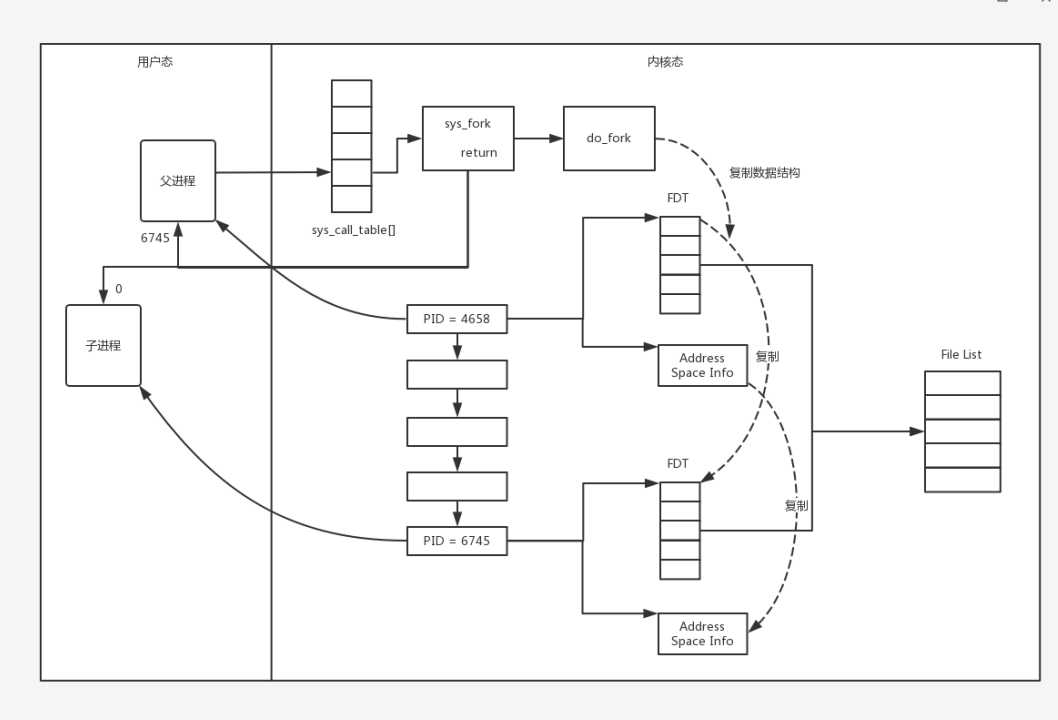
操作系统的功能之二是进程管理
当一个用户进程运行的时候,内核为他分配的资源,总要有一个数据结构保存,哪些资源分配给了这个进程。分配给这个进程的资源往往包括打开的文件,内存空间等。
操作系统的功能之三是内存管理
每个进程有独立的内存空间,内存空间是进程用来存放数据的,就像一间一间的仓库。为了进程使用方便,每个进程内存空间,在进程的角度来看都是独立的,也即都是从0号仓库,1号仓库,一直到N号仓库,都是独享的。但是从操作系统内核的角度来看,当然不可能独享,而是大家共享,M号仓库只有一个,你用他就不能用,这就需要一个仓库调度系统,将用户进程的仓库号和实际使用的仓库号对应起来,例如进程1的10号仓库,对应到真实的仓库是110号,进程2的20号仓库,对应到真实的仓库是120号。
操作系统功能之四是文件系统
对于Linux来讲,很多东西都是文件,例如进程号回对应一个文件,建立一个网络连接也对应一个文件。文件系统多种多样,为了能够统一适配,有一个虚拟文件系统的中间层VFS。
操作系统功能之五是设备管理
设备分两种,一种是块设备,一种是字符设备,例如硬盘就是块设备,可以格式化为文件系统,再如鼠标和键盘的输入输出是字符设备。
操作系统功能之六是网络管理
其实对于Linux来讲,网络也是基于设备和文件系统的,但是由于网络有自己的协议栈,要遵循TCP/IP协议栈标准。
对于Linux的基础知识方面,我写了几篇文章如下。
五、了解数据中心和网络基础知识
云平台当然会部署在数据中心里面,由于数据中心里面的硬件设备也是非常专业的,因而很多地方机房部门和云计算部门是两个部门,但是作为一个云架构师,需要和机房部门进行沟通,因而需要一定的数据中心知识,在数据中心里面,最难搞定的是网络,因而这里面网络知识是重中之重。
下面这个图是一个典型的数据中心图。
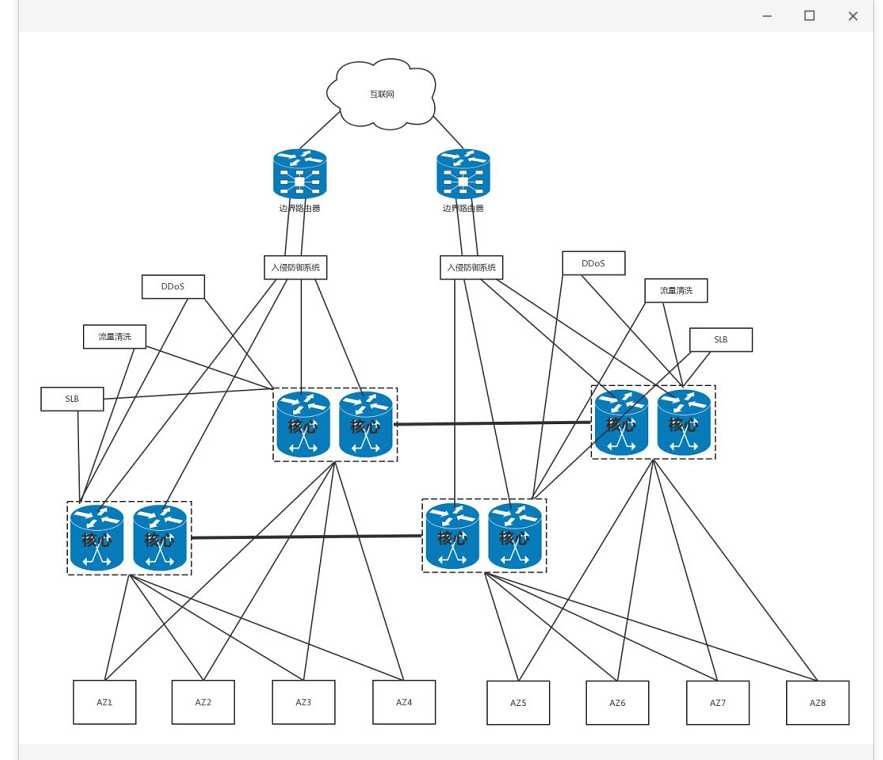
最外层是Internet Edge,也叫Edge Router,也叫Border Router,它提供数据中心与Internet的连接。
第一层core network,包含很多的core switches
Available Zone同Edge router之间通信
Available Zone之间的通信提供
提供高可用性连接HA
提供Intrusion Prevention Services
提供Distributed Denial of Service Attack Analysis and Mitigation
提供Tier 1 Load Balancer
第二层也即每个AZ的最上层,我们称为Aggregation layer。
第三层是access layer,就是一个个机架的服务器,用接入交换机连接在一起。
这是一个典型的三层网络结构,也即接入层、汇聚层、核心层三层。
对于数据中心,我写了几篇文章
除了数据中心以外,哪怕是做应用架构,对于网络的了解也是必须的。
云架构说到底是分布式架构,既然是分布式,就是去中心化的,因而就需要系统之间通过网络进行互通,因而网络是作为大规模系统架构绕不过去的一个坎。
对于网络的基本原理,推荐书籍《计算机网络-严伟与潘爱民译》,《计算机网络:自顶向下方法》。
对于TCP/IP协议栈的了解,推荐书籍《TCP/IP详解》,《The TCP/IP Guide》
对于
对于网络程序设计,推荐书籍《UNIX网络编程》
如果你想了解网络协议栈的实现,推荐书籍《深入理解LINUX网络内幕》
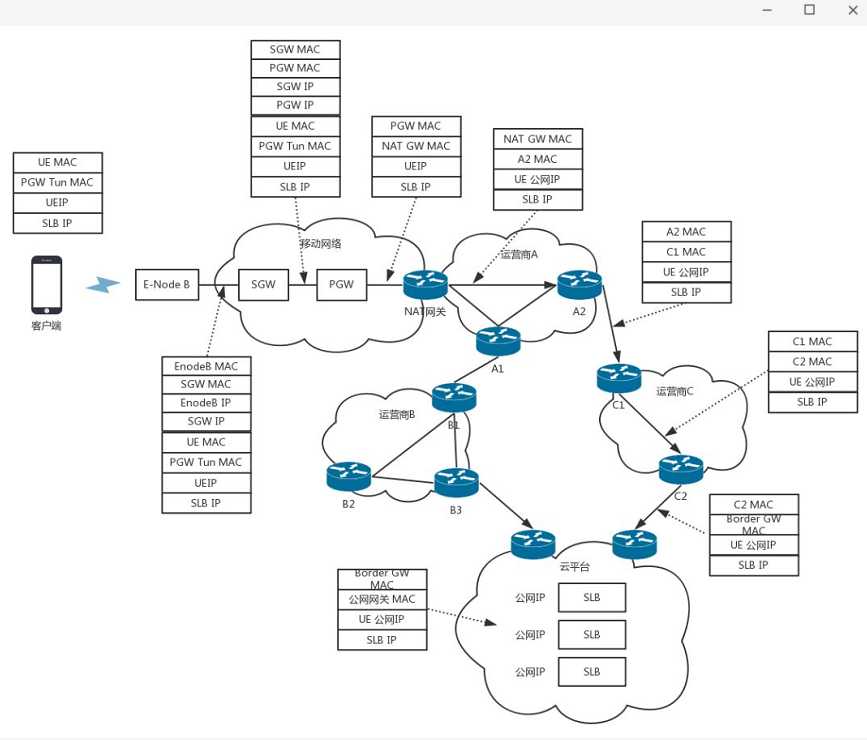
这里还自我推荐一下本人写的极客时间专栏《趣谈网络协议》。
其中有个综合场景,串起来所有的网络协议。
六、基于KVM了解计算虚拟化
当物理机搭建完毕之后,接下来就是基于物理机上面搭建虚拟机了。
没有了解虚拟机的同学,可以在自己的笔记本电脑上用VirtualBox或者Vmware创建虚拟机,你会发现,很容易就能在物理机的操作系统之内再安装多个操作系统,通过这种方式,你可以很方便的在windows办公系统之内安装一个Linux系统。从而保持LInux系统的持续学习。
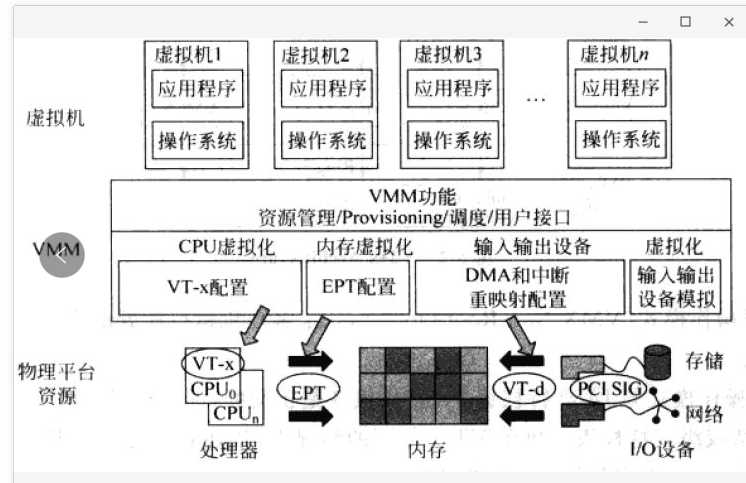
前面讲linux操作系统的时候,说到操作系统,就是整个系统的管家。应用程序要申请资源,都需要通过操作系统的系统调用接口,向操作系统内核申请将CPU,内存,网络,硬盘等资源分配给他。
这时候你会发现,虚拟机也是物理机上的一个普通进程,当虚拟机内部的应用程序申请资源的时候,需要向虚拟机的操作系统请求。然而虚拟机的操作系统自己本身也没有权限操作资源,因而又需要像物理机的操作系统申请资源。这中间要多一次翻译的工作,完成这件事情的称为虚拟化软件。例如上面说的VirtualBox和Vmware都是虚拟化软件。
但是多一层翻译,就多一层性能损耗,如果虚拟机里面的每一个操作都要翻译,都不能直接操作硬件,性能就会差很多,简直没办法用,于是就出现了上图中的硬件辅助虚拟化,也即通过硬件的特殊配置,例如VT-x和VT-d等,让虚拟机里面的操作系统知道,他不是一个原生的操作系统了,是一个虚拟机的操作系统,不能按照原来的模式操作资源了,而是通过特殊的驱动以硬件辅助的方式抄近道操作物理资源。
刚才说的是桌面虚拟化,也就是在你的笔记本电脑上,在数据中心里面,也可以使用Vmware进行虚拟化,但是价格比较贵,如果规模比较大,会采取开源的虚拟化软件qemu-kvm。
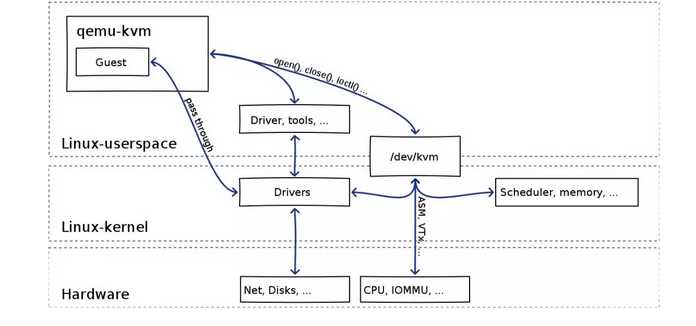
对于qemu-kvm来说,和上面的原理是一样的,其中qemu的emu是emulator的意思,也即模拟器,就是翻译的意思。KVM是一个可以使用CPU的硬件辅助虚拟化的方式,而网络和存储的,需要通过特殊的virtio的方式,提供高性能的设备虚拟化功能。
要了解虚拟化的基本原理,推荐书籍《系统虚拟化——原理与实现》
要了解KVM,推荐两本书籍《KVM Virtualization Cookbook》和《Mastering KVM Virtualization》。
另外KVM和qemu的官方文档也是必须要看的,还有Redhat的官网很多文章非常值得学习。
对于虚拟化方面,我写了以下的文章。
裸用KVM创建虚拟机,体验virtualbox为你做的10件事情
KVM虚拟机镜像那点儿事,qcow2六大功能,内部快照和外部快照有啥区别?
七、基于Openvswitch了解网络虚拟化
当虚拟机创建出来了,最主要的诉求就是要能上网,他能访问到网上的资源,如果虚拟机里面部署一个网站,也希望别人能够访问到他。
这一方面依赖于qemu-KVM的网络虚拟化,将网络包从虚拟机里面传播到虚拟机外面,这需要物理机内核转换一把,形成虚拟机内部的网卡和虚拟机外部的虚拟网卡。
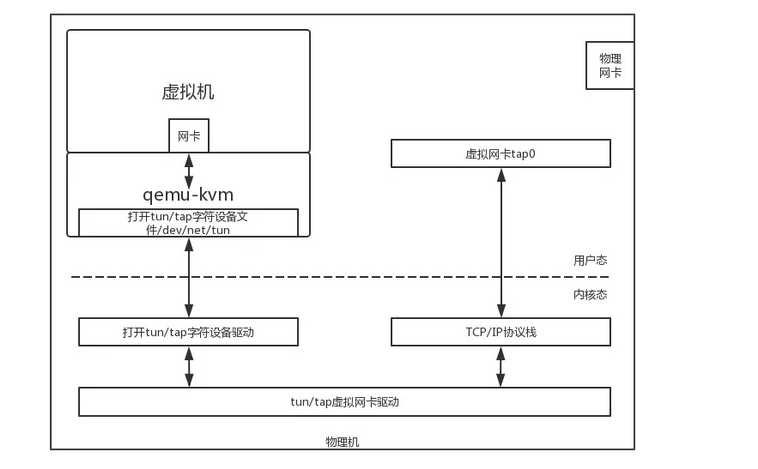
另外一方面就是虚拟机的网络如何能够连接到物理网络里面。物理网络常常称为underlay network,虚拟网络常常称为overlay network,从物理网络到虚拟网络称为网络虚拟化,能非常好的完成这件事情的是一个叫Openvswitch的虚拟交换机软件。
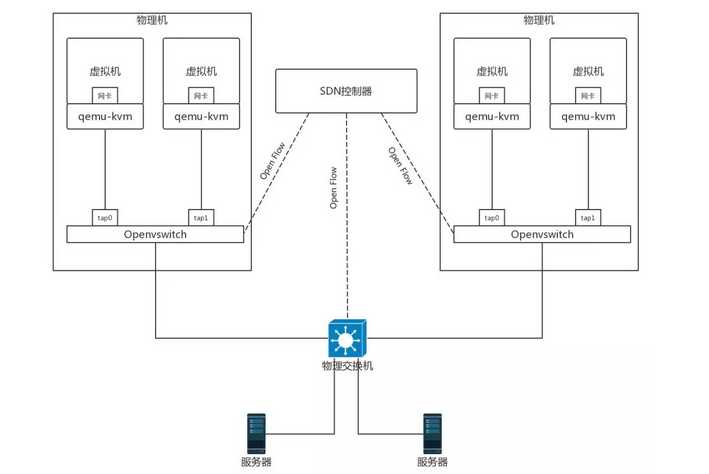
Openvswitch会有一个内核驱动,监听物理网卡,可以将物理网卡上收到的包拿进来。虚拟机创建出来的外部的虚拟网卡也可以添加到Openvswitch上,而Openvswitch可以设定各种的网络包处理策略,将网络包在虚拟机和物理机之间进行传递,从而实现了网络虚拟化。
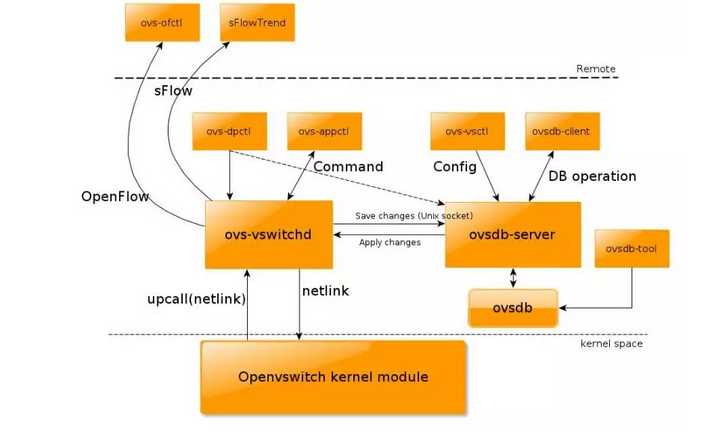
对于Openvswitch,我主要是通过官方文档进行研究,写下了这个系列。
Openvswitch的入门篇
Openvswitch的操作篇
玩转Openvwitch第二站:Bridge和Controller
玩转Openvswitch第八站:Interface和Tunnel (下)
玩转Openvswitch第八站:Interface和Tunnel (上)
Openvswitch的代码分析篇
八、基于OpenStack了解云平台
当有了虚拟机,并且虚拟机能够上网了之后,接下来就是搭建云平台的时候了。
云是基于计算,网络,存储虚拟化技术的,云和虚拟化的主要区别在于,管理员的管理模式不同,用户的使用模式也不同。
虚拟化平台没有多层次的丰富的租户管理,没有灵活quota配额的限制,没有灵活的QoS的限制,多采用虚拟网络和物理网络打平的桥接模式,虚拟机直接使用机房网络,没有虚拟子网VPC的概念,虚拟网络的管理和隔离不能和租户隔离完全映射起来。对于存储也是,公司采购了统一的存储,也不能和租户的隔离完全映射起来。
使用虚拟化平台的特点是,对于这个平台的操作完全由运维部门统一管理,而不能将权限下放给业务部门自己进行操作。因为一旦允许不同的部门自己操作,大家都用机房网络,在没有统一管控的情况下,很容易网段冲突了。如果业务部门向申请虚拟机,需要通过工单向运维部门统一的申请。当然这个运维部门很适应这种方式,因为原来物理机就是这样管理的。
但是公有云,例如aws就没办法这样,租户千千万万,只能他们自己操作。在私有云里面,随着服务化甚至微服务化的进行,服务数目越来越多,迭代速度越来越快,业务部门需要更加频繁的创建和消耗虚拟机,如果还是由运维部统一审批,统一操作,会使得运维部门压力非常大,而且极大限制了迭代速度,因而要引入 租户管理,运维部灵活配置每个租户的配额quota和QoS,在这个配额里面,业务部门随时可以按照自己的需要,创建和删除虚拟机,无需知会运维部门。每个部门都可以创建自己的虚拟网络VPC,不同租户的VPC之前完全隔离,所以网段可以冲突,每个业务部门自己规划自己的网络架构,只有少数的机器需要被外网或者机房访问的时候,需要少数的机房IP,这个也是和租户映射起来的,可以分配给业务部门机房网IP的个数范围内,自由的使用。这样每个部门自主操作,迭代速度就能够加快了。
云平台中的开源软件的代表是OpenStack,建议大家研究OpenStack的设计机制,是在云里面通用的,了解了OpenStack,对于公有云,容器云,都能发现相似的概念和机制。
沿着OpenStack创建虚拟机的过程,我总结了100个知识点,写下了下面的文章。
用OpenStack界面轻松创建虚拟机的你,看得懂虚拟机启动的这24个参数么?
觉得OpenStack的网络复杂?其实你家里就有同样一个网络
当发现你的OpenStack虚拟机网络有问题,不妨先试一下这16个步骤
手动用KVM模拟OpenStack Cinder挂载iSCSI卷
不仅Docker会使用Control Group,KVM也会使用Cgroup来控制资源分配
通过我们研究OpenStack,我们会发现很多非常好的云平台设计模式。
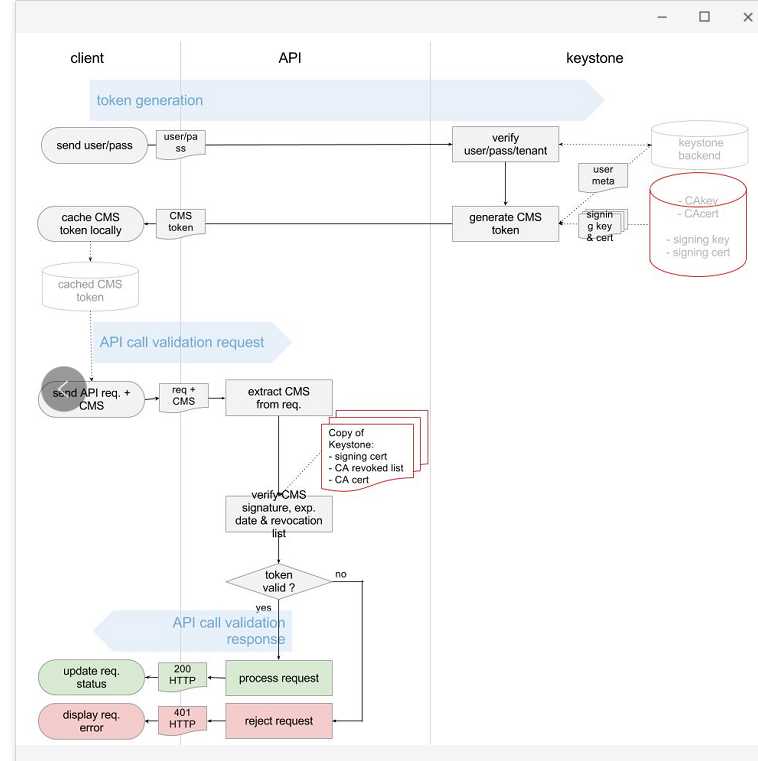
第一:基于PKI Token的认证模式
如果我们要实现一个Restful API,希望有个统一的认证中心的话,Keystone的三角形工作模式是常用的。
当我们要访问一个资源,通过用户名密码或者AK/SK登录之后,如果认证通过,接下来对于资源的访问,不应该总带着用户名密码,而是登录的时候形成一个Token,然后访问资源的时候带着Token,服务端通过Token去认证中心进行验证即可。
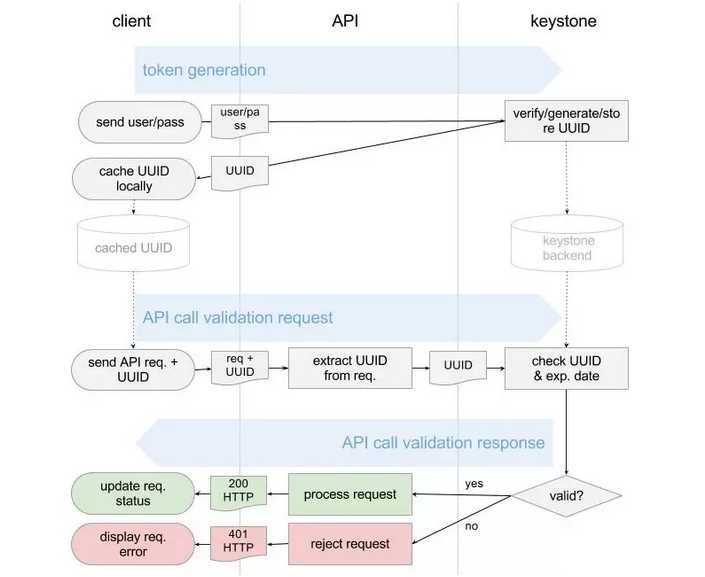
如果每次验证都去认证中心,效率比较差,后来就有了PKI Token,也即Token解密出来是一个有详细租户信息的字符串,这样本地就可以进行认证和鉴权。
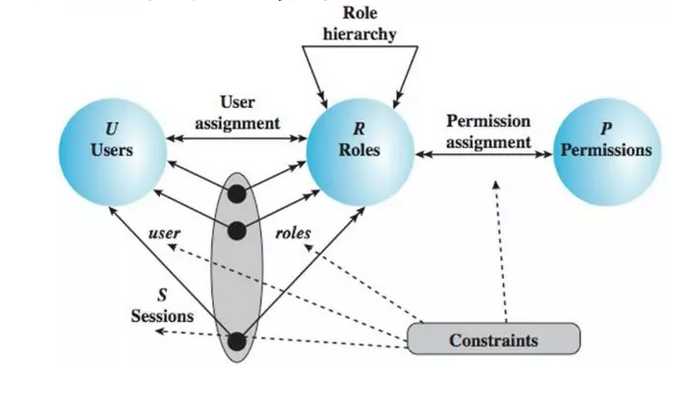
第二:基于Role Based Access Control的鉴权模式
对于权限控制,我们学会比较通用的Role Based Access Control的权限控制模式, 形成“用户-角色-权限”的授权模型。在这种模型中,用户与角色之间,角色与权限之间,一般者是多对多的关系,可以非常灵活的控制权限。
第三:基于Quota的配额管理
可以通过设置计算,网络,存储的quota,设置某个租户自己可以自主操作的资源量。
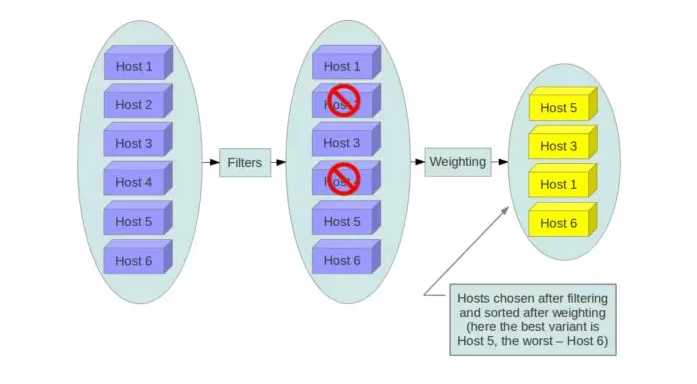
第四:基于预选和优选两阶段的Scheduler机制
当需要从一个资源池里面,选择一个节点,使用这个节点上的资源的时候,一个通用的Scheduler机制是:
首先进行预选,也即通过Filter,将不满足条件的过滤掉。
然后进行优选,也即对于过滤后,满足条件的候选人,通过计算权重,选择其中最优的。
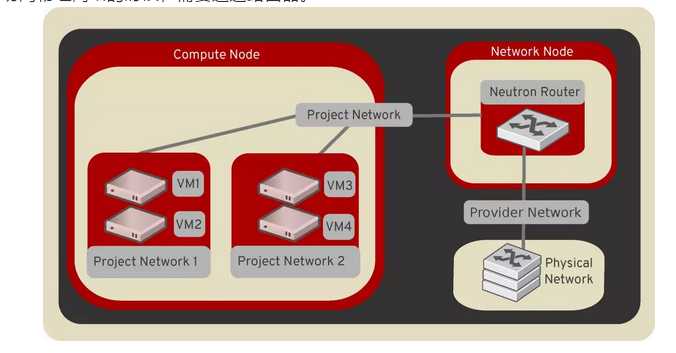
第五:基于独立虚拟子网的网络模式
为了每个租户可以独立操作,因而虚拟网络应该是独立于物理网络的,这样不同的租户可以进行独立的网络规划而互不影响,也不影响物理网络,当需要跨租户访问,或者要访问物理网络的时候,需要通过路由器。
第六:基于Copy on Write的镜像机制
有时候我们在虚拟机里面做了一些操作以后,希望能够把这个时候的镜像保存下来,好随时恢复到这个时间点,一个最最简单的方法就是完全复制一份,但是由于镜像太大了,这样效率很差。因而采取Copy on write的机制,当打镜像的时刻,并没有新的存储消耗,而是当写入新的东西的时候,将原来的数据找一个地方复制保存下来,这就是Copy on Write。
对于Openstack,有一种镜像qcow2就是采取的这样的机制。
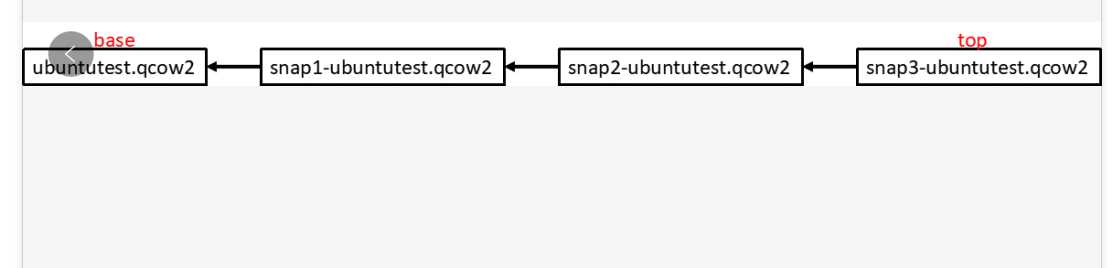
这样镜像就像分层一样,一层一层的罗上去。
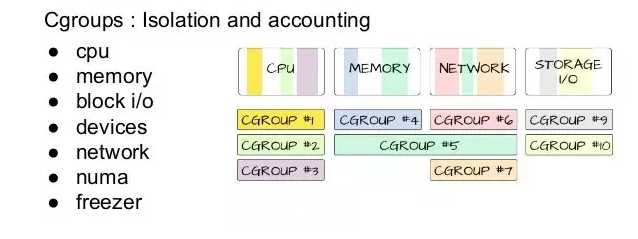
第七:基于namespace和cgroup的隔离和Qos机制
在OpenStack里面,网络节点的路由器是由network namespace来隔离的。
KVM的占用的CPU和内存,使用Cgroup来隔离的。
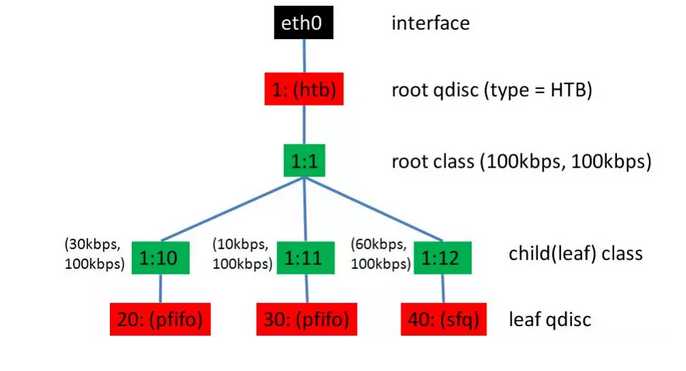
网络的QoS使用TC来隔离的。
第八:基于iptables的安全机制
有时候,我们希望网络中的节点之间不能相互访问,作为最简单的防火墙,iptables起到了很重要的作用,以后实现ACL机制的,都可以考虑使用iptables。
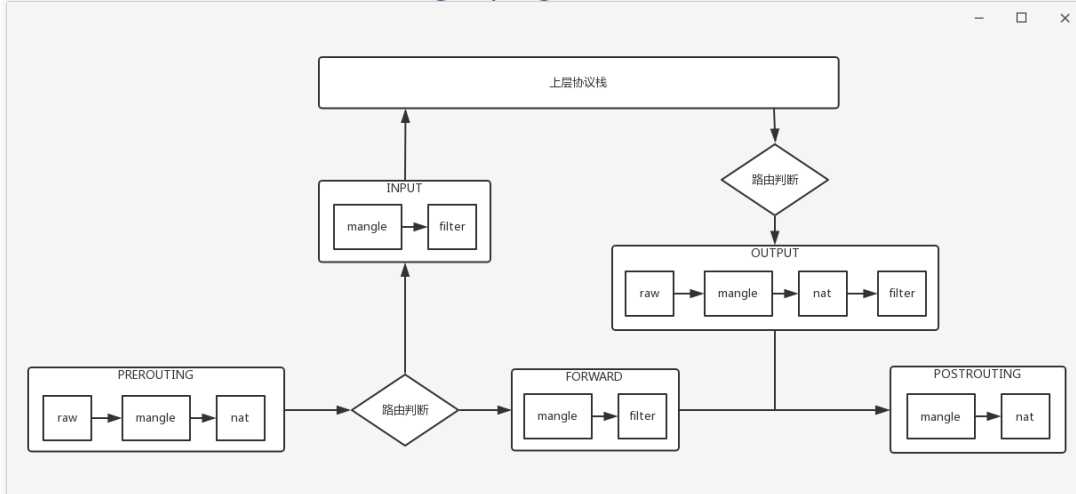
九、基于Mesos和Kubernetes了解容器平台
搭建完毕虚拟化层和云平台层,接下来就是容器层了。
Docker有几个核心技术,一个是镜像,一个是运行时,运行时又分看起来隔离的namespace和用起来隔离的cgroup。
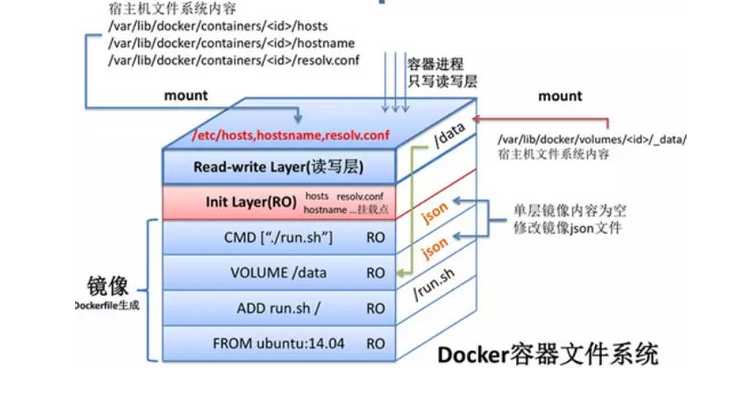
Docker的镜像也是一种Copy on Write的镜像格式,下面的层级是只读的,所有的写入都在最上层。
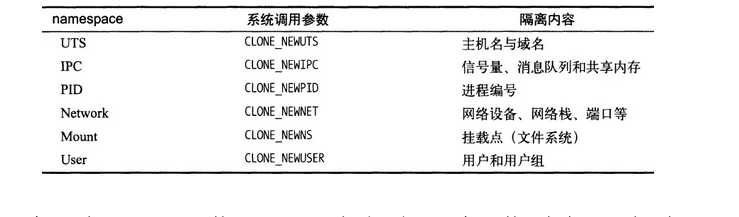
对于运行时,Docker使用的namespace除了network namespace外,还有很多,如下表格所示。
Docker对于cgroup的使用是在运行Docker的时候,在路径/sys/fs/cgroup/cpu/docker/下面控制容器运行使用的资源。
可见容器并没有使用更新的技术,而是一种新型的交付方式,也即应用的交付应该是一容器镜像的方式交付,容器一旦启动起来,就不应该进入容器做各种修改,这就是不可改变基础设施。
由于容器的镜像不包含操作系统内核,因而小的多,可以进行跨环境的迁移和弹性伸缩。
我写下了下面的文章,总结了几点容器的正确使用姿势。
有了容器之后,接下来就是容器平台的选型,其实swarm, mesos, kubernetes各有优势,也可以在不同的阶段,选择使用不同的容器平台。
Docker, Kubernetes, DCOS 不谈信仰谈技术
容器平台选型的十大模式:Docker、DC/OS、K8S谁与当先?
基于Mesos的DCOS更像是一个数据中心管理平台,而非仅仅容器管理平台,他可以兼容Kubernetes的编排,同时也能跑各种大数据应用。
在容器领域,基于Kubernetes的容器编排已经成为事实标准。
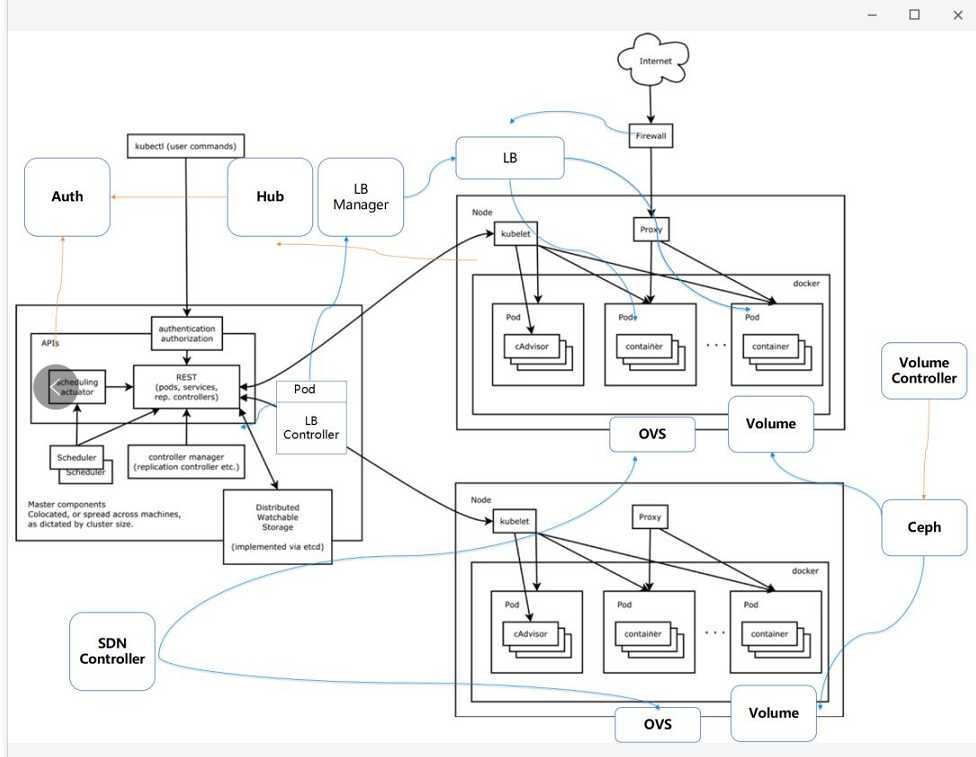
当我们深入分析Kubernetes管理容器模式的时候,我们也能看到熟悉的面孔。
在Kubernetes里面,租户之间靠namespace进行隔离,这个不是Docker的namespace,而是Kubernetes的概念。
API Server的鉴权,也是基于Role Based Access Control模式。
Kubernetes对于namespace,也有Quota配置,使用ResourceQuota。
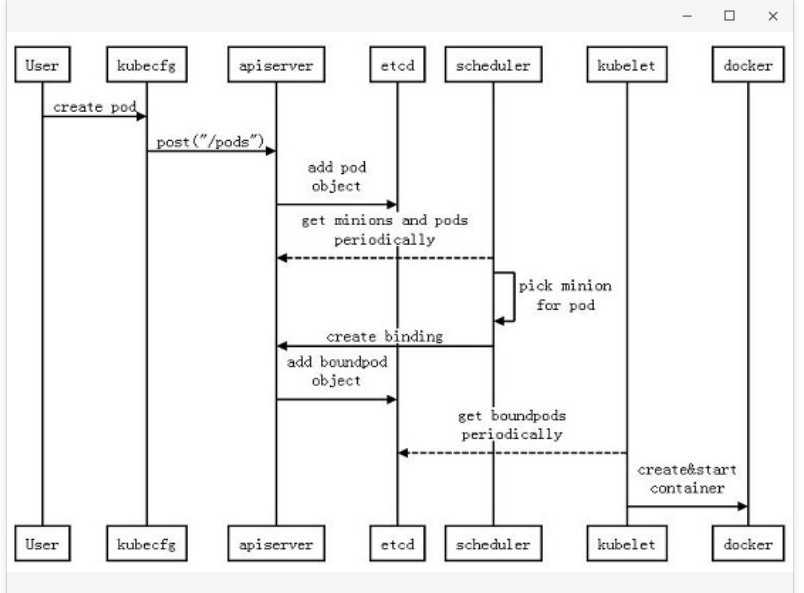
当Kubernetes想选择一个节点运行pod的时候,选择的过程也是通过预选和优选两个阶段。
预选(Filtering)
PodFitsResources满足资源
PodSelectorMatches符合标签
PodFitsHost符合节点名称
优选(Weighting)
LeastRequestedPriority资源消耗最小
BalancedResourceAllocation资源使用最均衡
Kubernetes规定了以下的网络模型定义。
所有的容器都可以在不使用NAT的情况下同别的容器通信
所有的节点都可以在不使用NAT的情况下同所有的容器通信
容器的地址和别人看到的地址一样
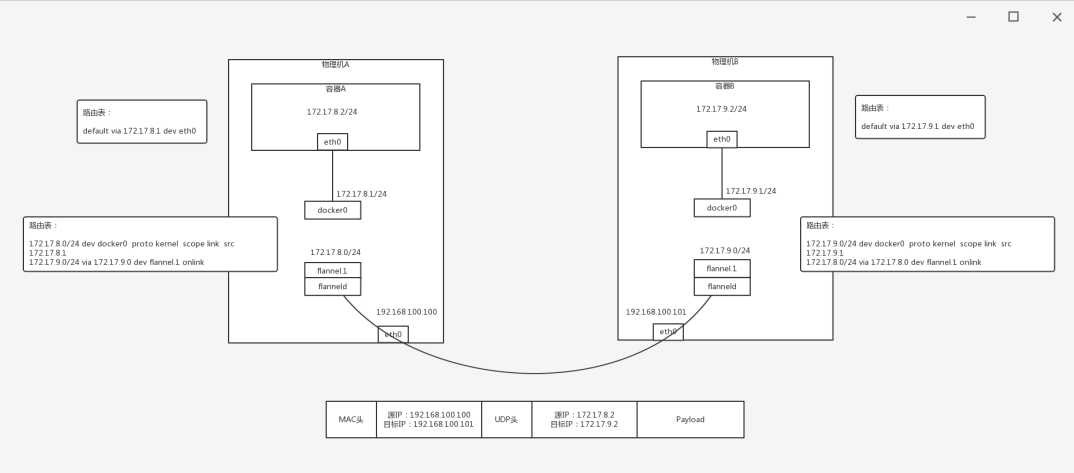
也即容器平台应该有自己的私有子网,常用的有Flannel, Calico, Openvswitch都是可以的。
既可以使用Overlay的方式,如图flannel.
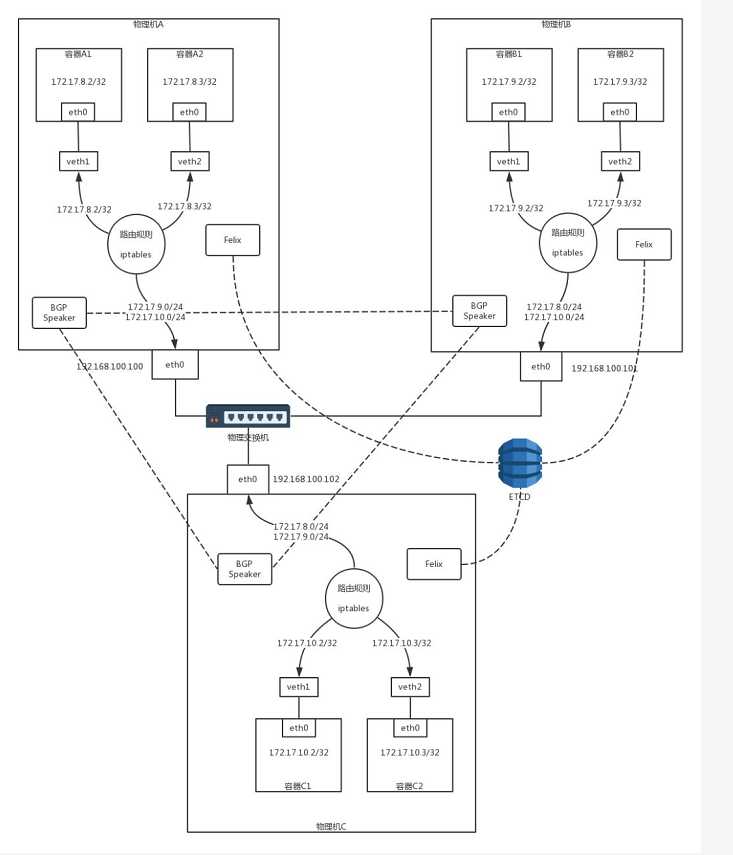
也可以使用BGP的方式,如图Calico
十、基于Hadoop和Spark了解大数据平台
对于数据架构的部分,其实经历了三个过程,分别是Hadoop Map-Reduce 1.0,基于Yarn的Map-Reduce 2.0, 还有Spark。
如下图是Map-Reduce 1.0的过程。
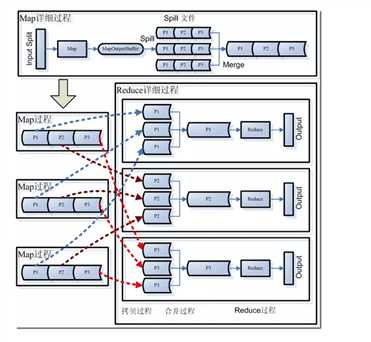
Map-Reduce的过程将一个大任务,split称为多个Map Task,分散到多台机器并行处理,将处理的结果保存到本地,第二个阶段,Reduce Task将中间结果拷贝过来,将结果集中处理,取得最终结果。
在Map-Reduce 1.0的时候,跑任务的方式只有这一种,为了应对复杂的场景,将任务的调度和资源的调度分成两层。其中资源的调用由Yarn进行,Yarn不管是Map还是Reduce,只要向他请求,他就找到空闲的资源分配给他。
每个任务启动的时候,专门启动一个Application Master,管理任务的调度,他是知道Map和Reduce的。这就是Map-Reduce 2.0如下图。
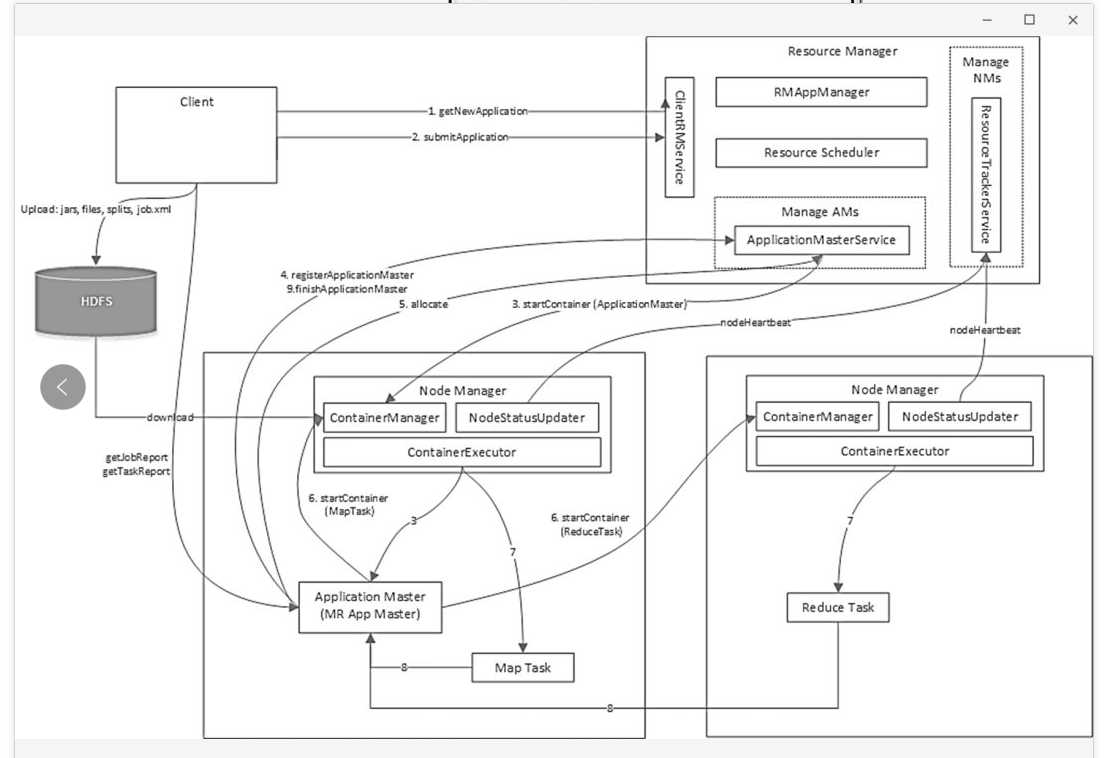
这里Yarn相当于外包公司的老板,所有的员工都是worker,都是他的资源,外包公司的老板是不清楚接的每一个项目的。
Application Master相当于接的每个项目的项目经理,他是知道项目的具体情况的,他在执行项目的时候,如果需要员工干活,需要向外包公司老板申请。
Yarn是个通用的调度平台,能够跑Map-Reduce 2,就能跑Spark。
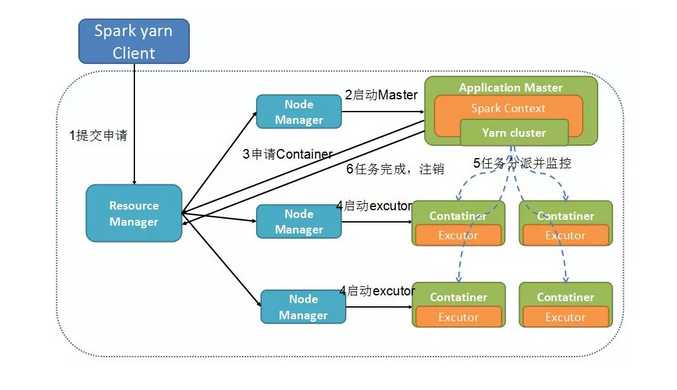
Spark也是创建Spark自己的Application Master,用于调度任务。
Spark之所以比较快,是因为前期规划做的好,不是像Map-Reduce一样,每一次分配任务和聚合任务都要写一次硬盘,而是将任务分成多个阶段,将所有在一个Map都做了的合成一个阶段,这样中间不用落盘,但是到了需要合并的地方,还是需要落盘的。
对于Hadoop和Spark的基本原理,我写了下面的文章。
真正写Map-Reduce程序的时候,有很多的方法论,这里我总结了几个,供您参考。
十一、基于Lucene和ElasticSearch了解搜索引擎
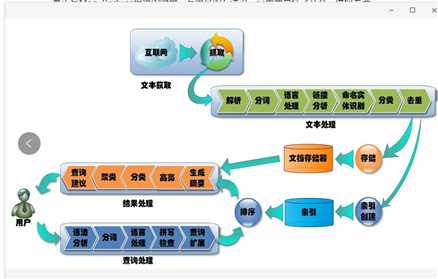
当大数据将收集好的数据处理完毕之后,一般会保存在两个地方,一个是正向索引,可以用Hbase,Cassandra等文档存储,一个是反向索引,方便搜索,就会保存在基于Lucene的ElasticSearch里面。
对于Lucene,在职业生涯的早期,写过一个《Lucene 原理与代码分析完整版》有500多页。
对于搜索引擎的通用原理,写了下面的文章。
十二、基于SpringCloud了解微服务
最后到了应用架构,也即微服务。
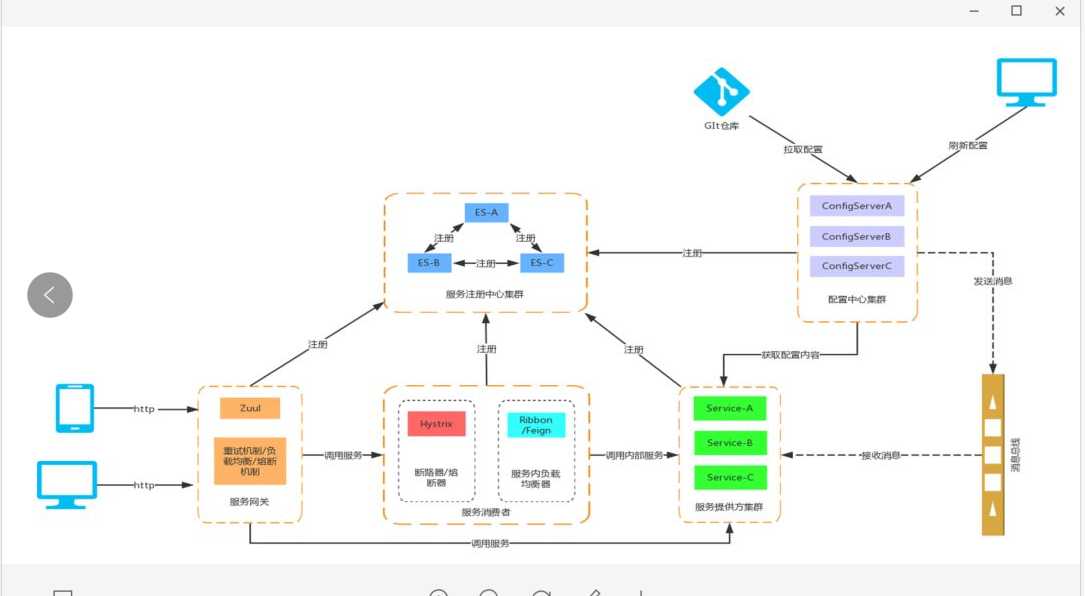
接下来细说微服务架构设计中不得不知的十大要点。
设计要点一:负载均衡 + API 网关
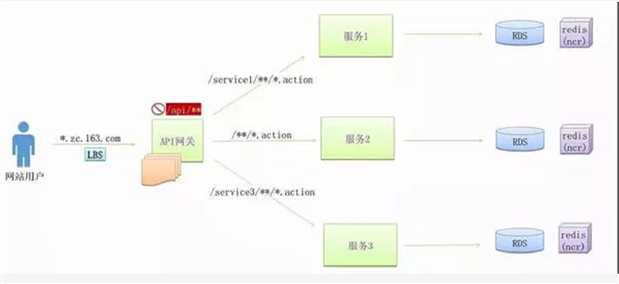
在实施微服务的过程中,不免要面临服务的聚合与拆分。
当后端服务的拆分相对比较频繁的时候,作为手机 App 来讲,往往需要一个统一的入口,将不同的请求路由到不同的服务,无论后面如何拆分与聚合,对于手机端来讲都是透明的。
有了 API 网关以后,简单的数据聚合可以在网关层完成,这样就不用在手机 App 端完成,从而手机 App 耗电量较小,用户体验较好。
有了统一的 API 网关,还可以进行统一的认证和鉴权,尽管服务之间的相互调用比较复杂,接口也会比较多。
API 网关往往只暴露必须的对外接口,并且对接口进行统一的认证和鉴权,使得内部的服务相互访问的时候,不用再进行认证和鉴权,效率会比较高。
有了统一的 API 网关,可以在这一层设定一定的策略,进行 A/B 测试,蓝绿发布,预发环境导流等等。
API 网关往往是无状态的,可以横向扩展,从而不会成为性能瓶颈。
设计要点二:无状态化与独立有状态集群
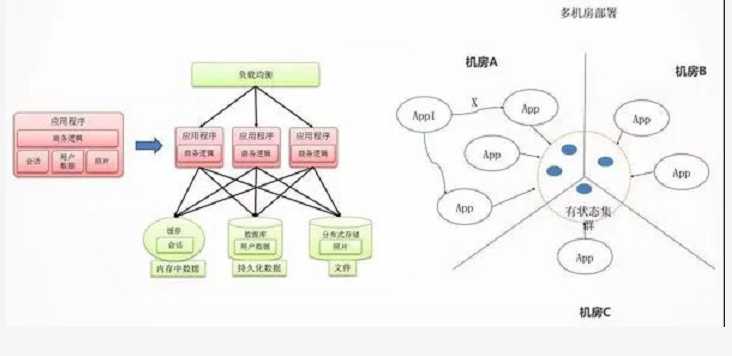
影响应用迁移和横向扩展的重要因素就是应用的状态。无状态服务,是要把这个状态往外移,将 Session 数据,文件数据,结构化数据保存在后端统一的存储中,从而应用仅仅包含商务逻辑。
状态是不可避免的,例如 ZooKeeper,DB,Cache 等,把这些所有有状态的东西收敛在一个非常集中的集群里面。
整个业务就分两部分,一个是无状态的部分,一个是有状态的部分。
无状态的部分能实现两点:
跨机房随意地部署,也即迁移性。
弹性伸缩,很容易地进行扩容。
有状态的部分,如 ZooKeeper,DB,Cache 有自己的高可用机制,要利用到它们自己高可用的机制来实现这个状态的集群。
虽说无状态化,但是当前处理的数据,还是会在内存里面的,当前的进程挂掉数据,肯定也是有一部分丢失的。
为了实现这一点,服务要有重试的机制,接口要有幂等的机制,通过服务发现机制,重新调用一次后端服务的另一个实例就可以了。
设计要点三:数据库的横向扩展
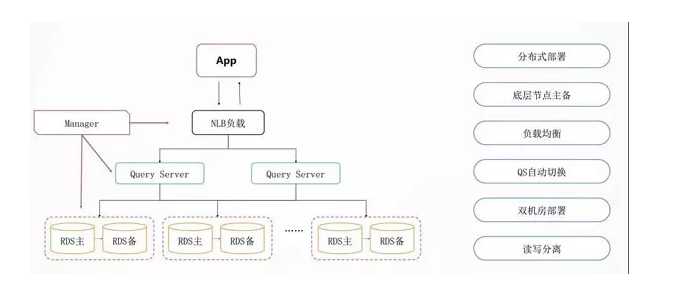
数据库是保存状态,是最重要的也是最容易出现瓶颈的。有了分布式数据库可以使数据库的性能随着节点增加线性地增加。
分布式数据库最最下面是 RDS,是主备的,通过 MySQL 的内核开发能力,我们能够实现主备切换数据零丢失。
所以数据落在这个 RDS 里面,是非常放心的,哪怕是挂了一个节点,切换完了以后,你的数据也是不会丢的。
再往上就是横向怎么承载大的吞吐量的问题,上面有一个负载均衡 NLB,用 LVS,HAProxy,Keepalived,下面接了一层 Query Server。
Query Server 是可以根据监控数据进行横向扩展的,如果出现了故障,可以随时进行替换的修复,对于业务层是没有任何感知的。
另外一个就是双机房的部署,DDB 开发了一个数据运河 NDC 的组件,可以使得不同的 DDB 之间在不同的机房里面进行同步。
这时候不但在一个数据中心里面是分布式的,在多个数据中心里面也会有一个类似双活的一个备份,高可用性有非常好的保证。
设计要点四:缓存
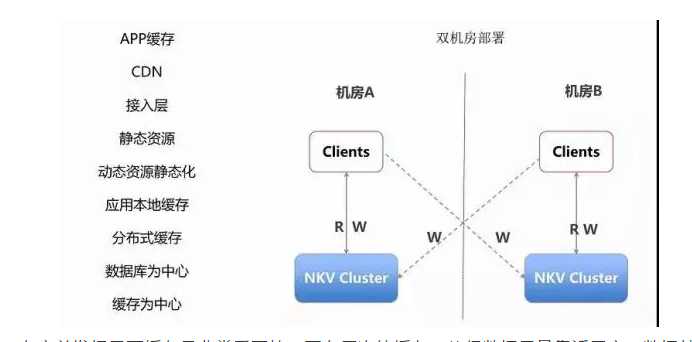
在高并发场景下缓存是非常重要的。要有层次的缓存,使得数据尽量靠近用户。数据越靠近用户能承载的并发量也越大,响应时间越短。
在手机客户端 App 上就应该有一层缓存,不是所有的数据都每时每刻从后端拿,而是只拿重要的,关键的,时常变化的数据。
尤其对于静态数据,可以过一段时间去取一次,而且也没必要到数据中心去取,可以通过 CDN,将数据缓存在距离客户端最近的节点上,进行就近下载。
有时候 CDN 里面没有,还是要回到数据中心去下载,称为回源,在数据中心的最外层,我们称为接入层,可以设置一层缓存,将大部分的请求拦截,从而不会对后台的数据库造成压力。
如果是动态数据,还是需要访问应用,通过应用中的商务逻辑生成,或者去数据库读取,为了减轻数据库的压力,应用可以使用本地的缓存,也可以使用分布式缓存。
如 Memcached 或者 Redis,使得大部分请求读取缓存即可,不必访问数据库。
当然动态数据还可以做一定的静态化,也即降级成静态数据,从而减少后端的压力。
设计要点五:服务拆分与服务发现
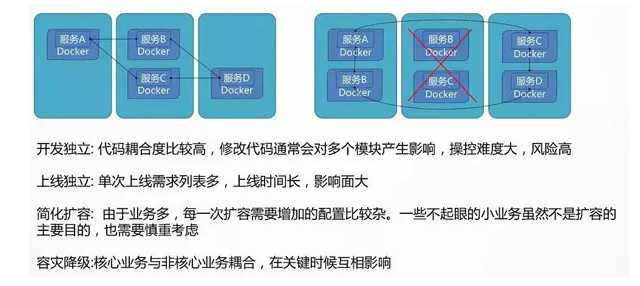
当系统扛不住,应用变化快的时候,往往要考虑将比较大的服务拆分为一系列小的服务。
这样第一个好处就是开发比较独立,当非常多的人在维护同一个代码仓库的时候,往往对代码的修改就会相互影响。
常常会出现我没改什么测试就不通过了,而且代码提交的时候,经常会出现冲突,需要进行代码合并,大大降低了开发的效率。
另一个好处就是上线独立,物流模块对接了一家新的快递公司,需要连同下单一起上线,这是非常不合理的行为。
我没改还要我重启,我没改还让我发布,我没改还要我开会,都是应该拆分的时机。
再就是高并发时段的扩容,往往只有最关键的下单和支付流程是核心,只要将关键的交易链路进行扩容即可,如果这时候附带很多其他的服务,扩容既是不经济的,也是很有风险的。
另外的容灾和降级,在大促的时候,可能需要牺牲一部分的边角功能,但是如果所有的代码耦合在一起,很难将边角的部分功能进行降级。
当然拆分完毕以后,应用之间的关系就更加复杂了,因而需要服务发现的机制,来管理应用相互的关系,实现自动的修复,自动的关联,自动的负载均衡,自动的容错切换。
设计要点六:服务编排与弹性伸缩

当服务拆分了,进程就会非常的多,因而需要服务编排来管理服务之间的依赖关系,以及将服务的部署代码化,也就是我们常说的基础设施即代码。
这样对于服务的发布,更新,回滚,扩容,缩容,都可以通过修改编排文件来实现,从而增加了可追溯性,易管理性,和自动化的能力。
既然编排文件也可以用代码仓库进行管理,就可以实现一百个服务中,更新其中五个服务,只要修改编排文件中的五个服务的配置就可以。
当编排文件提交的时候,代码仓库自动触发自动部署升级脚本,从而更新线上的环境。
当发现新的环境有问题时,当然希望将这五个服务原子性地回滚,如果没有编排文件,需要人工记录这次升级了哪五个服务。
有了编排文件,只要在代码仓库里面 Revert,就回滚到上一个版本了。所有的操作在代码仓库里都是可以看到的。
设计要点七:统一配置中心
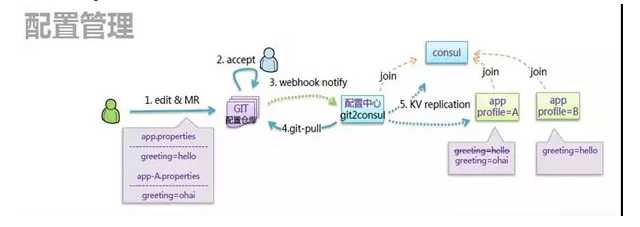
服务拆分以后,服务的数量非常多,如果所有的配置都以配置文件的方式放在应用本地的话,非常难以管理。
可以想象当有几百上千个进程中有一个配置出现了问题,是很难将它找出来的,因而需要有统一的配置中心,来管理所有的配置,进行统一的配置下发。
在微服务中,配置往往分为以下几类:
一类是几乎不变的配置,这种配置可以直接打在容器镜像里面。
第二类是启动时就会确定的配置,这种配置往往通过环境变量,在容器启动的时候传进去。
第三类就是统一的配置,需要通过配置中心进行下发。例如在大促的情况下,有些功能需要降级,哪些功能可以降级,哪些功能不能降级,都可以在配置文件中统一配置。
设计要点八:统一日志中心
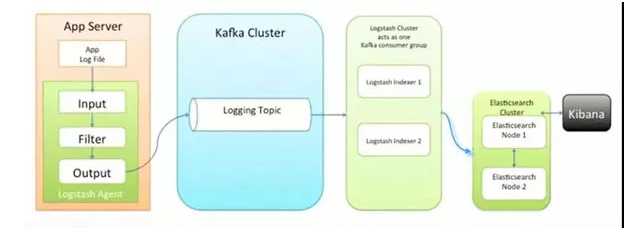
同样是进程数目非常多的时候,很难对成千上百个容器,一个一个登录进去查看日志,所以需要统一的日志中心来收集日志。
为了使收集到的日志容易分析,对于日志的规范,需要有一定的要求,当所有的服务都遵守统一的日志规范的时候,在日志中心就可以对一个交易流程进行统一的追溯。
例如在最后的日志搜索引擎中,搜索交易号,就能够看到在哪个过程出现了错误或者异常。
设计要点九:熔断,限流,降级
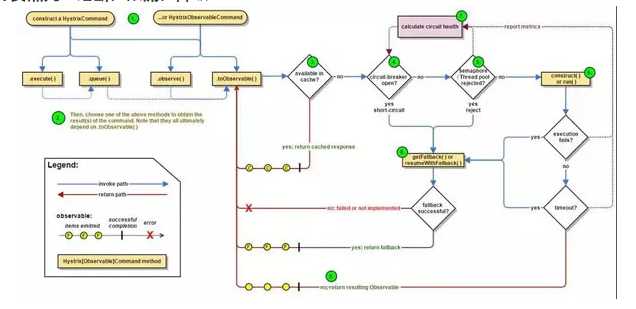
服务要有熔断,限流,降级的能力,当一个服务调用另一个服务,出现超时的时候,应及时返回,而非阻塞在那个地方,从而影响其他用户的交易,可以返回默认的托底数据。
当一个服务发现被调用的服务,因为过于繁忙,线程池满,连接池满,或者总是出错,则应该及时熔断,防止因为下一个服务的错误或繁忙,导致本服务的不正常,从而逐渐往前传导,导致整个应用的雪崩。
当发现整个系统的确负载过高的时候,可以选择降级某些功能或某些调用,保证最重要的交易流程的通过,以及最重要的资源全部用于保证最核心的流程。
还有一种手段就是限流,当既设置了熔断策略,又设置了降级策略,通过全链路的压力测试,应该能够知道整个系统的支撑能力。
因而就需要制定限流策略,保证系统在测试过的支撑能力范围内进行服务,超出支撑能力范围的,可拒绝服务。
当你下单的时候,系统弹出对话框说 “系统忙,请重试”,并不代表系统挂了,而是说明系统是正常工作的,只不过限流策略起到了作用。
设计要点十:全方位的监控

当系统非常复杂的时候,要有统一的监控,主要有两个方面,一个是是否健康,一个是性能瓶颈在哪里。
当系统出现异常的时候,监控系统可以配合告警系统,及时地发现,通知,干预,从而保障系统的顺利运行。
当压力测试的时候,往往会遭遇瓶颈,也需要有全方位的监控来找出瓶颈点,同时能够保留现场,从而可以追溯和分析,进行全方位的优化。
我会将微服务相关的文章更加细化的写出来。
有关微服务和容器之间的结合,写了下面的文章。
最后。
小弟参加GIAC年度新人评选,马了这么多字,能帮忙投个票吗?请点击原文连接。
刘超 网易云技术架构部总监
长期致力于云计算开源技术的分享,布道和落地,将网易内部最佳实践服务客户与行业。
技术分享:出版《Lucene应用开发解密》,极客时间专栏《趣谈网络协议》,个人公众号《刘超的通俗云计算》文章Kubernetes及微服务系列18篇,Mesos系列30篇,KVM系列25篇,Openvswitch系列31篇,OpenStack系列24篇,Hadoop系列10篇。公众号文章《终于有人把云计算,大数据,人工智能讲明白了》累积10万+
大会布道:InfoQ架构师峰会明星讲师,作为邀请讲师在QCon,LC3,SACC,GIAC,CEUC,SoftCon,NJSD等超过10场大型技术峰会分享网易的最佳实践
行业落地:将网易的容器和微服务产品在银行,证券,物流,视频监控,智能制造等多个行业落地。
标签:生成 定义 路径 界面 笔记本电脑 pager 微观经济学 soc 压力
原文地址:https://www.cnblogs.com/wuchangsoft/p/9924640.html