标签:开发 sha 实现 [] glibc 分享 getch 动态内存 忘记
-----------------------C语言内存管理----------------------
内存组成
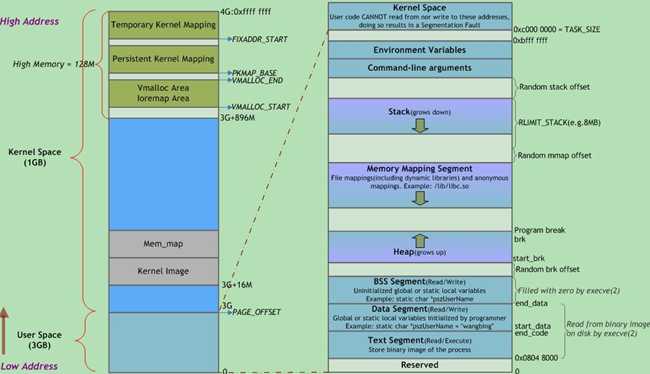
我们现在把这个模型进行简化,简化如下:
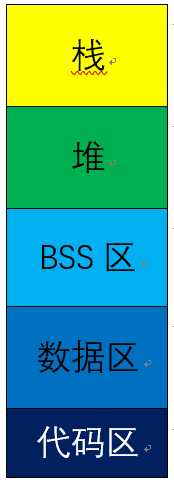
代码段、数据段、BSS段在程序编译期间由编译器分配空间,在程序启动时加载,由于未初始化的全局变量存放在BSS段,已初始化的全局变量存放在数据段,所以程序中可以减少的使用全局变量以节省程序编译和启动时间;栈和堆在程序运行中由系统分配空间。下面简单介绍一下各个组成部分具体含义,重点介绍堆、栈。
栈的作用
栈又称堆栈,由编译器自动分配释放,行为类似数据结构中的栈(先进后出)。堆栈主要有三个用途:
1)为函数内部声明的非静态局部变量(C语言中称“自动变量”)提供存储空间。
2) 记录函数调用过程相关的维护性信息,称为栈帧(Stack Frame)或过程活动记录(Procedure Activation Record)。它包括函数返回地址,不适合装入寄存器的函数参数及一些寄存器值的保存。除递归调用外,堆栈并非必需。因为编译时可获知局部变量,参数和返回地址所需空间,并将其分配于BSS段。
3) 临时存储区,用于暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。此时若栈的大小低于堆栈最大值RLIMIT_STACK(通常是8M),则栈会动态增长,程序继续运行。映射的栈区扩展到所需大小后,不再收缩。
Linux中ulimit -s命令可查看和设置堆栈最大值,当程序使用的堆栈超过该值时, 发生栈溢出(Stack Overflow),程序收到一个段错误(Segmentation Fault)。注意,调高堆栈容量可能会增加内存开销和启动时间。
Linux中ulimit -s命令可查看和设置堆栈最大值,当程序使用的堆栈超过该值时, 发生栈溢出(Stack Overflow),程序收到一个段错误(Segmentation Fault)。注意,调高堆栈容量可能会增加内存开销和启动时间。
误区:栈空间是向下增长的(由高地址向低地址扩展,所以定义的变量,先定义的变量的地址值比后定义的地址值要大),其实这完全是编译器的自由。
|
#include <stdio.h>
int main(int argc, const char * argv[]) {
int a = 100; int b = 100;
printf("address of a: 0x%p\n", &a); printf("address of b: 0x%p\n", &b);
getchar();
return 0; } |
比如上面这一段代码,在VS2017和gcc5.4编译器里体现的就不一样,大家可以去试一下。
用于存放进程运行时动态分配的内存段,可动态扩张或缩减。堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。当进程调用malloc(C)/new(C++)等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用free(C)/delete(C++)等函数释放内存时,被释放的内存从堆中剔除(缩减) 。
内存碎片产生的原因:
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统会自动回收。
产生的问题:
使用堆时经常出现两种问题:1) 释放或改写仍在使用的内存(“内存破坏”);2)未释放不再使用的内存(“内存泄漏”)。当释放次数少于申请次数时,可能已造成内存泄漏。泄漏的内存往往比忘记释放的数据结构更大,因为所分配的内存通常会圆整为下个大于申请数量的2的幂次(如申请212B,会圆整为256B)。
通常存放程序中以下符号:
1)未初始化的全局变量和静态局部变量
2)初始值为0的全局变量和静态局部变量(依赖于编译器实现)
3)未定义且初值不为0的符号(该初值即common block的大小)
C语言中,未显式初始化的静态分配变量被初始化为0(算术类型)或空指针(指针类型)。由于程序加载时,BSS会被操作系统清零,所以未赋初值或初值为0的全局变量都在BSS中。BSS段仅为未初始化的静态分配变量预留位置,在目标文件中并不占据空间,这样可减少目标文件体积。但程序运行时需为变量分配内存空间,故目标文件必须记录所有未初始化的静态分配变量大小总和(通过start_bss和end_bss地址写入机器代码)。当加载器(loader)加载程序时,将为BSS段分配的内存初始化为0。在嵌入式软件中,进入main()函数之前BSS段被C运行时系统映射到初始化为全零的内存(效率较高)。
注意,尽管均放置于BSS段,但初值为0的全局变量是强符号,而未初始化的全局变量是弱符号。若其他地方已定义同名的强符号(初值可能非0),则弱符号与之链接时不会引起重定义错误,但运行时的初值可能并非期望值(会被强符号覆盖)。因此,定义全局变量时,若只有本文件使用,则尽量使用static关键字修饰;否则需要为全局变量定义赋初值(哪怕0值),保证该变量为强符号,以便链接时发现变量名冲突,而不是被未知值覆盖。
数据段通常用于存放程序中已初始化且初值不为0的全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。
数据段保存在目标文件中(在嵌入式系统里一般固化在镜像文件中),其内容由程序初始化。例如,对于全局变量int gVar = 10,必须在目标文件数据段中保存10这个数据,然后在程序加载时复制到相应的内存。
数据段与BSS段的区别如下:
1)BSS段不占用物理文件尺寸,但占用内存空间;数据段占用物理文件,也占用内存空间。对于大型数组如int ar0[10000] = {1, 2, 3, ...}和int ar1[10000],ar1放在BSS段,只记录共有10000*4个字节需要初始化为0,而不是像ar0那样记录每个数据1、2、3...,此时BSS为目标文件所节省的磁盘空间相当可观。
2)当程序读取数据段的数据时,系统会出发缺页故障,从而分配相应的物理内存;当程序读取BSS段的数据时,内核会将其转到一个全零页面,不会发生缺页故障,也不会为其分配相应的物理内存。
代码段也称正文段或文本段,通常用于存放程序执行代码(即CPU执行的机器指令)。一般C语言执行语句都编译成机器代码保存在代码段。通常代码段是可共享的,因此频繁执行的程序只需要在内存中拥有一份拷贝即可。代码段通常属于只读,以防止其他程序意外地修改其指令(对该段的写操作将导致段错误)。某些架构也允许代码段为可写,即允许修改程序。
很多人说C很强大,那是因为C语言提供了指针,让你可以操作你想操作的内存,但是我要说这一高级特性是C语言的伟大,也是一把双刃剑,很多程序员很痛恨指针和对内存的操作,甚至到了恐惧。其实C语言不太那么适合做业务开发,因为它需要程序员做很多一些与业务无关的代码,影响了开发效率。
真正的勇士是敢于直面惨淡的人生,C程序员也没有办法逃避不使用,下面这些坑才是实战的重点:
1)内存分配未成功,却使用了它;
|
动态分配内存分配有可能会失败。常用解决办法是,在使用内存之前检查指针是否为NULL。如果指针p是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。如果是用malloc或new来申请内存,应该用if(NULL==p) 或if(p!=NULL)进行防错处理 |
2)内存分配虽然成功了,但是尚未初始化,就使用了它;
|
犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。 |
3)内存分配成功,也初始化了,但是操作越界了;
|
例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界,同时要牢记数组的下标是(0<= index < length)的,for和while里的比较永远用“< length”。 |
4)忘记释放内存,造成内存泄漏;
|
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误(new/delete同理) |
5)释放内存了内存却继续使用它;
|
(1)程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。 (2)函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。 (3)使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。 |
所以建议大家牢记以下规则:
1)用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
2)不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
3) 避免数组或指针的下标越界,特别要当心发生“多1”或者“少1”操作。
4) 动态内存的申请与释放必须配对,防止内存泄漏。
5)用free或delete释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。
上文中提到的内存管理是指操作系统对应用程序本身在系统内存中的布局,“常见的内存错误”指的是应用程序对堆和栈上的内存操作方面的,该节要讨论的是我们对堆内存(也可以称为动态申请内存的管理,new/delete和malloc/free)。
glibc使用ptmalloc管理内存的,ptmalloc比起jemalloc和tcmalloc在效率和管理上存在弊端,尤其在多线程环境下和频繁操作内存时建议使用jemalloc和tcmalloc。Github和mysql使用了tcmalloc后性能优化了30%,这些产品都是从malloc入手来提高性能的。
使用C++开发时,尽量采用智能指针,这是因为智能指针实现了简单的垃圾回收机制,但是不建议采用auto_ptr和unique_ptr,这是因为他们采用所有权模型设计的,比如:
|
#include <iostream> #include <string> #include <memory> using namespace std;
int main() { auto_ptr<string> films[5] ={ auto_ptr<string> (new string("Fowl Balls")), auto_ptr<string> (new string("Duck Walks")), auto_ptr<string> (new string("Chicken Runs")), auto_ptr<string> (new string("Turkey Errors")), auto_ptr<string> (new string("Goose Eggs")) }; auto_ptr<string> pwin; pwin = films[2]; //此时所有权从films[2]转让给pwin,ilms[2]不再引用该字符串从而变成空指针 return 0; } |
因此auto_ptr和unique_ptr不能用户容器去保存,在此建议使用share_ptr。
实现类似于nginx的内存池(nginx是一个连接对应一个内存池,连接释放后释放内存池),或者ZMQ的无锁内存池技术,一直常驻于内存。
当然,我们在服务器开发方面,除了使用类似nginx或者ZMQ实现的内存管理方式外,还可以有一些基础性的组件,这些可以到github上去下载直接使用,这些都是实现对消息的缓存,也是线程安全的。
标签:开发 sha 实现 [] glibc 分享 getch 动态内存 忘记
原文地址:https://www.cnblogs.com/wangkeqin/p/9925622.html