标签:类别 深度学习 哈尔滨 判断 课程 img image 方式 迭代
在介绍具体算法之前,先了解一下线性判别函数的基本概念。
\(\mathbf { a } = \left( w _ { 0 } , w _ { 1 } , W _ { 2 } \dots , W _ { d } \right) ^ { t }\),是增广的权矢量。
在学习该增广形式的时候,我曾思考过,既然可以将将线性函数转化为两个向量的点乘,那在深度学习中(以pytorch为例),设计线性层(nn.Linear)时为什么还要令参数bias=True,直接不需要偏置,在输入向量中拼接一个维度(值为1)岂不是更加方便。答案当然是否定,我仔细思考后发现,如果这么做的话,对于每一个输入对会有一个独立的bias,因为新拼接的“1”值会随着反向传播进行迭代更新(每个输入的更新结果不同),此时bias便失去了意义,不再是与线性函数函数绑定,而是变成了输入的一个特征。
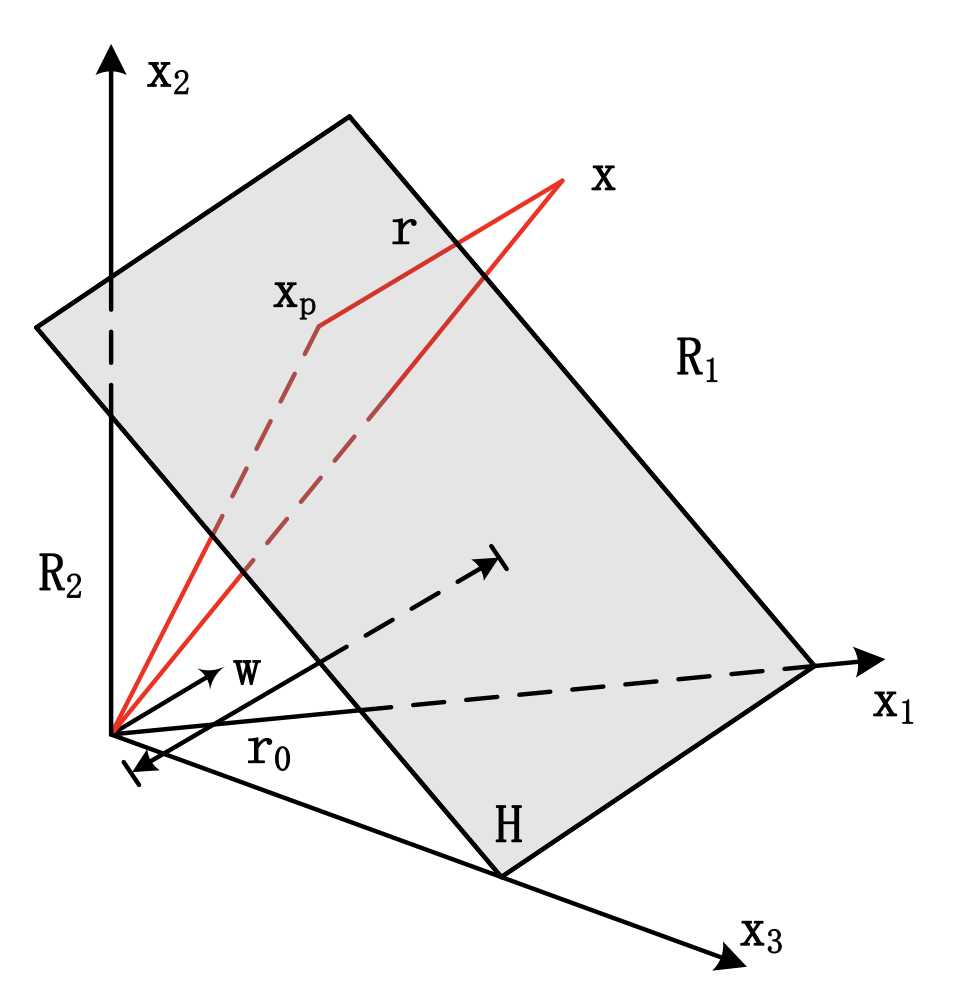
该界面有几个特点:
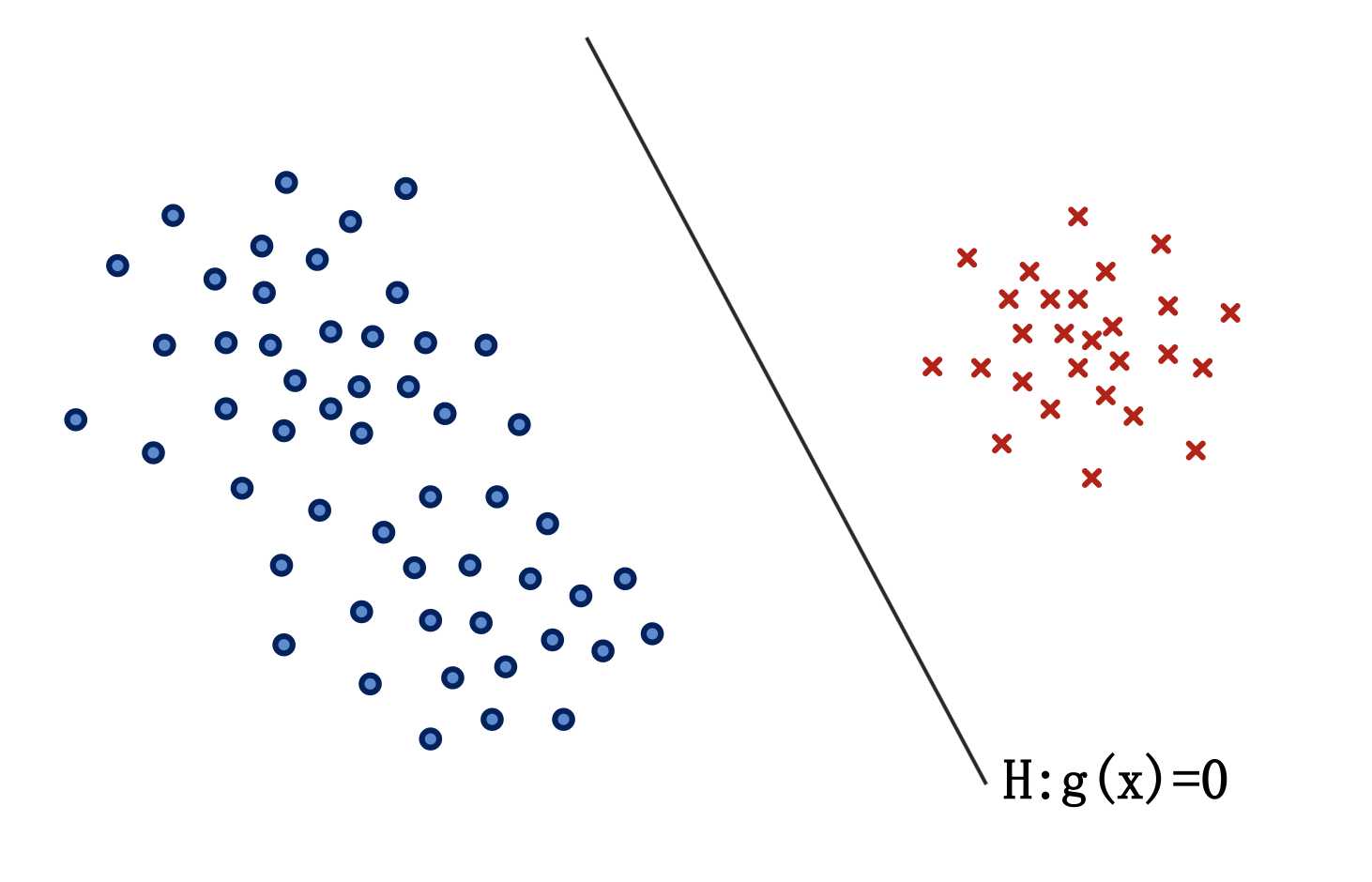
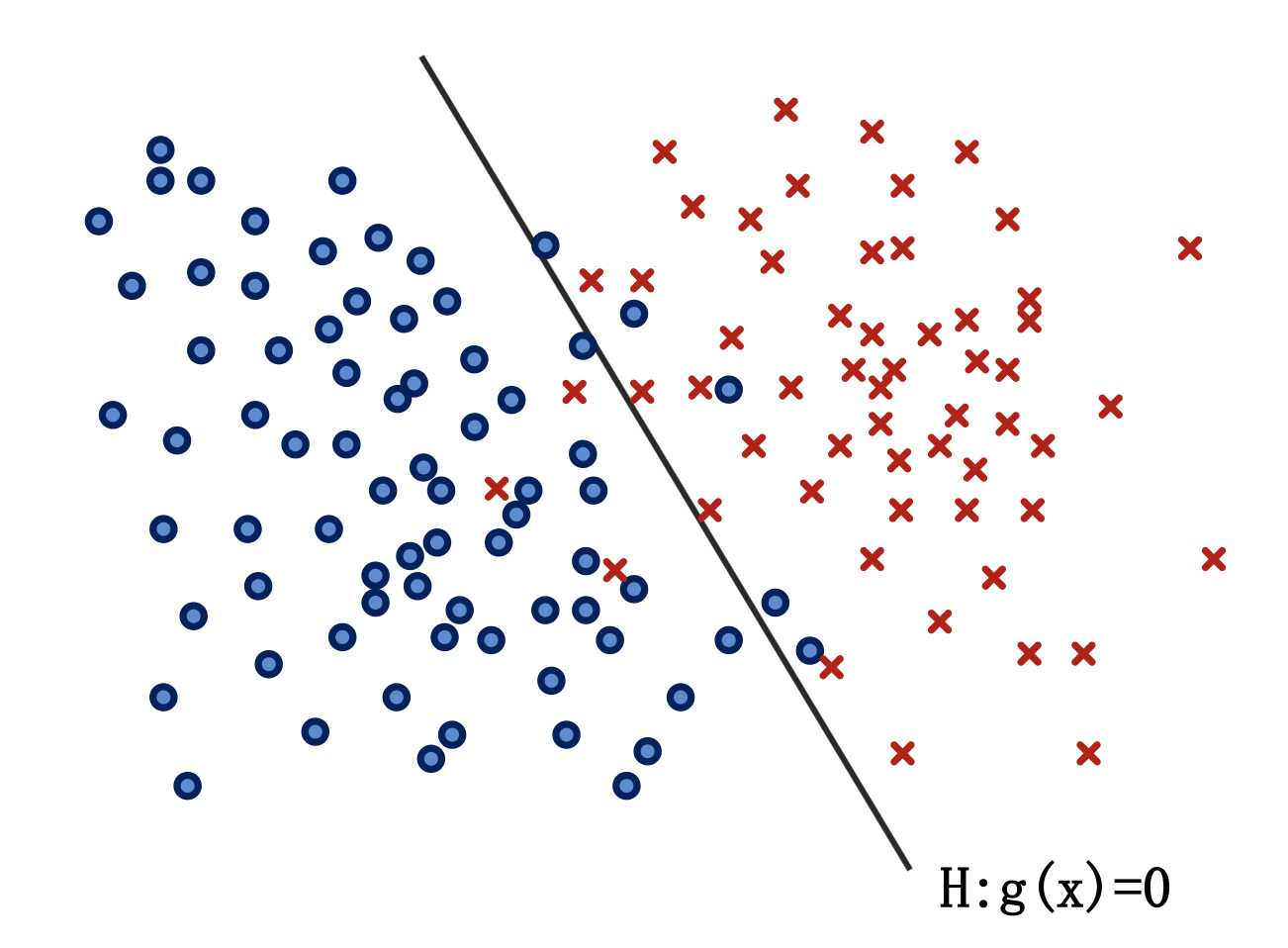
1.线性分类界面\(H\)是\(d\)维空间中的一个超平面;
2.分类界面将\(d\)维空间分成两部分,\(R_1\),\(R_2\)分别属于两个类别;
3.判别函数的权矢量\(w\)是一个垂直于分类界面\(H\)的矢量,其方向指向区域\(R_1\) ;
4.偏置\(w_0\)与原点到分类界面\(H\)的距离\(r_0\)有关:
\[r _ { 0 } = \frac { w _ { 0 } } { \| \mathbf { w } \| }\]
判别函数的规范化i形式:
\[\left\{ \begin{array} { c l } { \mathbf { a } ^ { t } \mathbf { y } _ { i } > 0 , } & { \mathbf { y } _ { i } \in \omega _ { 1 } } \\ { - \mathbf { a } ^ { t } \mathbf { y } _ { i } > 0 , } & { \mathbf { y } _ { i } \in \omega _ { 2 } } \end{array} \right.\]
- 在之后的感知器算法于LMSE算法中,均依据规范化的形式进行介绍,规范化后会使得目标函数形式比较简单。
- 规范化是在输入数据上进行,将属于第二个类别的数据乘上\(-1\)即可。
- 需要注意,因为本节内容是在函数的增广形式下进行介绍,因此在规范化之前需要对于每个类别的数据都拼接一个特征“1”。
哈尔滨工业大学计算机学院-模式识别-课程总结(三)-线性判别函数
标签:类别 深度学习 哈尔滨 判断 课程 img image 方式 迭代
原文地址:https://www.cnblogs.com/szxspark/p/9928370.html