标签:and 固定 准确率 自己 字符 etl 数据 初始 github
书籍源码:https://github.com/hzy46/Deep-Learning-21-Examples
CNN的发展已经很多了,ImageNet引发的一系列方法,LeNet,GoogLeNet,VGGNet,ResNet每个方法都有很多版本的衍生,tensorflow中带有封装好各方法和网络的函数,只要喂食自己的训练集就可以完成自己的模型,感觉超方便!!!激动!!!因为虽然原理流程了解了,但是要写出来真的。。。。好难,臣妾做不到啊~~~~~~~~
START~~~~
首先了解下微调的概念: 以VGG为例
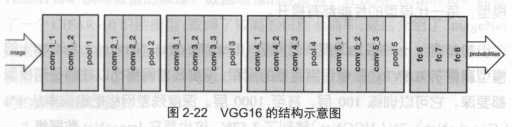
他的结构是卷积+全连接,卷积层分为5个部分共13层,conv1~conv5。还有三层全连接,即fc6,fc7,fc8。总共16层,因此被称为VGG16。
a.如果要将VGG16的结构用于一个新的数据集,首先要去掉fc8,因为fc8原本的输出是1000类的概率。需要改为符合自身训练集的输出类别数。
b.训练的时候,网络的参数的初始值并不是随机化生成的,而是采用VGG16在ImageNet上已经训练好的参数作为训练的初始值。因为已经训练过的VGG16中的参数已经包含了大量有用的卷积过滤器,这样做不仅节约大量训练时间,而且有助于分类器性能的提高。
载入VGG16的参数后,即可开始训练。此时需要指定训练层数的范围。一般而言,可以选择以下几种:
这种训练方法就是对神经网络做微调。
书中提供了卫星图像数据集,有6个类别,分别是森林(wood),水域(water),岩石(rock),农田(wetland),冰川(glacier),城市区域(urban)
保存结构为data_prepare/pic,再下层有两个文件夹train和validation,各文件夹下有6个文件夹,放的是该类别下的图片。
python data_convert.py -t pic/ --train-shards 2 --validation-shards 2 --num-threads 2 --dataset-name satellite
参数解释:
-t pic/ :表示转换pic文件夹下的数据,该文件夹必须与上面的文件结构保持一致
--train-shards 2 :把训练集分成两块,即最后的训练数据就是两个tfrecord格式的文件。若数据集更大,可以分更多数据块
--validation-shards 2 :把验证集分成两块
--num-thread 2 :用两个线程来产生数据。注意线程数必须要能整除train-shards和validation-shards,来保证每个线程处理的数据块是相同的。
--dataset-name :给生成的数据集起个名字,即表示最后生成文件的开头是satellite_train和satellite_validation
运行上述命令后,就可以在 pic 文件夹中找到 5 个新生成的文件 ,分别是:
Google 公司公布的一个图像分类工具包,它不仅定义了一些方便的接口,还提供了很多 ImageNet 数据集上常用的网络结构和预训练模型 。
截至2017年7月,Slim 提供包括 VGG16、VGG19、Inception V1 ~ V4、ResNet 50、ResNet 101、MobileNet 在内大多数常用模型的结构以及预训练模型,更多的模型还会被持续添加进来。
源码地址: https://github.com/tensorflow/models/tree/master/research/slim
可以通过执行 git clone https://github.corn/tensorflow/models.git 来获取
THE END~~~~
21个项目玩转深度学习:基于TensorFlow的实践详解03—打造自己的图像识别模型
标签:and 固定 准确率 自己 字符 etl 数据 初始 github
原文地址:https://www.cnblogs.com/helloworld0604/p/9936520.html