标签:方法安装 encoding tps xsl 载器 top ike RoCE mes
Scrapy——1
目录
Scrapy的安装
pip install Scrapy
Windows使用Scrapy需要很多的依赖环境,根据个人的电脑的情况而定,在cmd的安装下,缺少的环境会报错提示,在此网站下搜索下载,通过wheel方法安装即可。如果不懂wheel法安装的,可以参考我之前的随笔,方法雷同
通过如下代码安装依赖环境,最后也是通过pip install Scrapy进行安装
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
scrapy startproject project_name
scrapy genspider spider_name spider_url(scrapy genspider spider tanzhouedu.com)
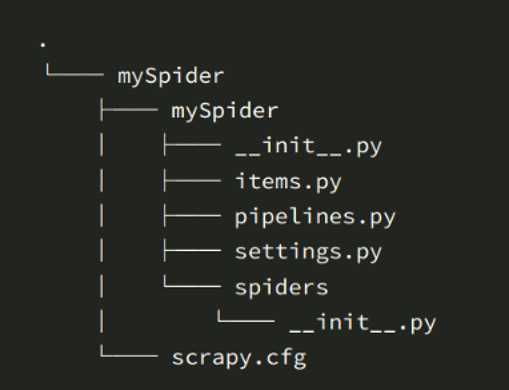
会相应生成如下文件
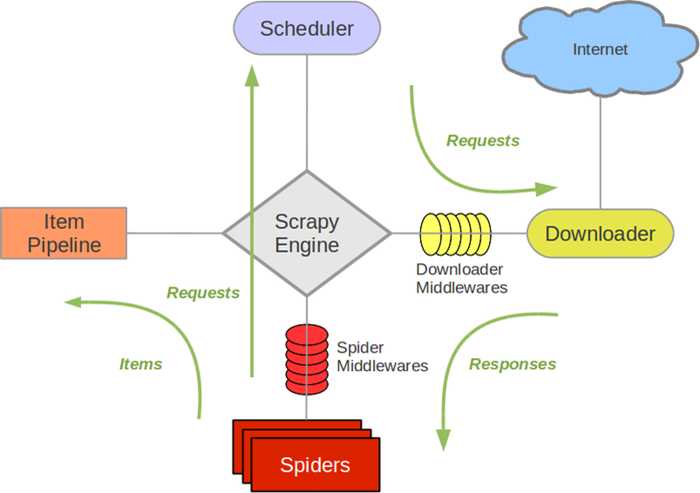
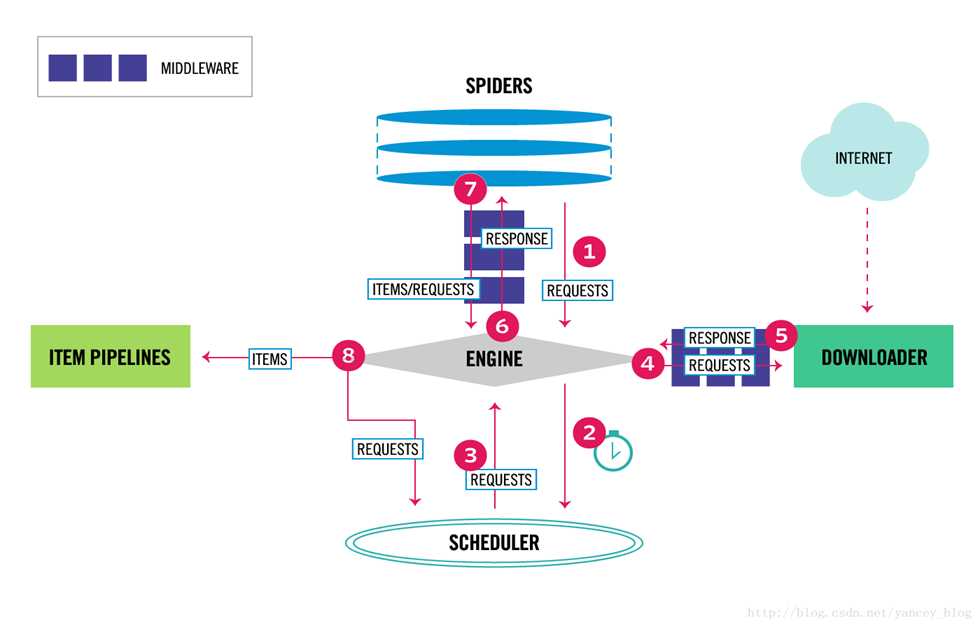
Scrapy知识点介绍
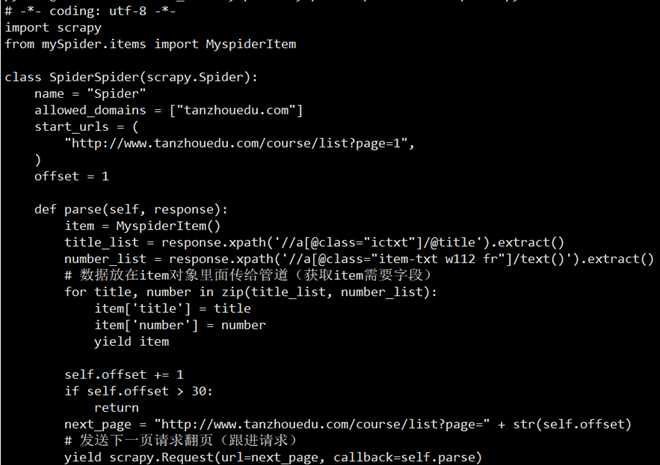

创建项目
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class BolezaixainItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() url = scrapy.Field() time = scrapy.Field()

# -*- coding: utf-8 -*- import scrapy from ..items import BolezaixainItem #导入本文件夹外的items文件 class BlogJobboleSpider(scrapy.Spider): name = ‘blog.jobbole‘ allowed_domains = [‘blog.jobbole.com/all-posts/‘] start_urls = [‘http://blog.jobbole.com/all-posts/‘] def parse(self, response): title = response.xpath(‘//div[@class="post-meta"]/p/a[1]/@title‘).extract() url = response.xpath(‘//div[@class="post-meta"]/p/a[1]/@href‘).extract() times = response.xpath(‘//div[@class="post floated-thumb"]/div[@class="post-meta"]/p[1]/text()‘).extract() time = [time.strip().replace(‘\r\n‘, ‘‘).replace(‘·‘, ‘‘) for time in times if ‘/‘ in time] for title, url, time in zip(title, url, time): blzx_items = BolezaixainItem() # 实例化管道 blzx_items[‘title‘] = title blzx_items[‘url‘] = url blzx_items[‘time‘] = time yield blzx_items # 翻页 next = response.xpath(‘//a[@class="next page-numbers"]/@href‘).extract_first() # next = http://blog.jobbole.com/all-posts/page/2/ yield scrapy.Request(url=next, callback=self.parse) # 回调
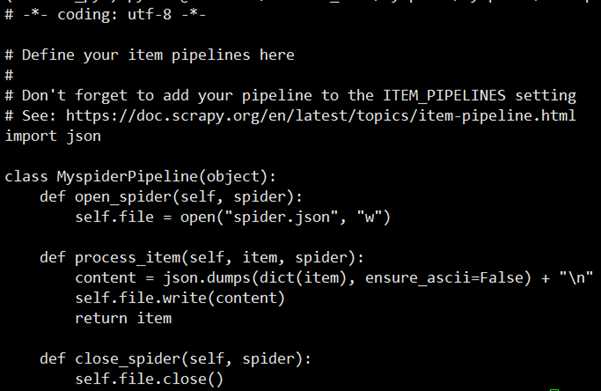
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql import json class BolezaixainPipeline(object): def __init__(self): pass print(‘======================‘) self.f = open(‘blzx.json‘, ‘w‘, encoding=‘utf-8‘) def open_spider(self, spider): pass def process_item(self, item, spider): s = json.dumps(dict(item), ensure_ascii=False) + ‘\n‘ self.f.write(s) return item def close_spider(self, spider): pass self.f.close()
时间,url, 标题
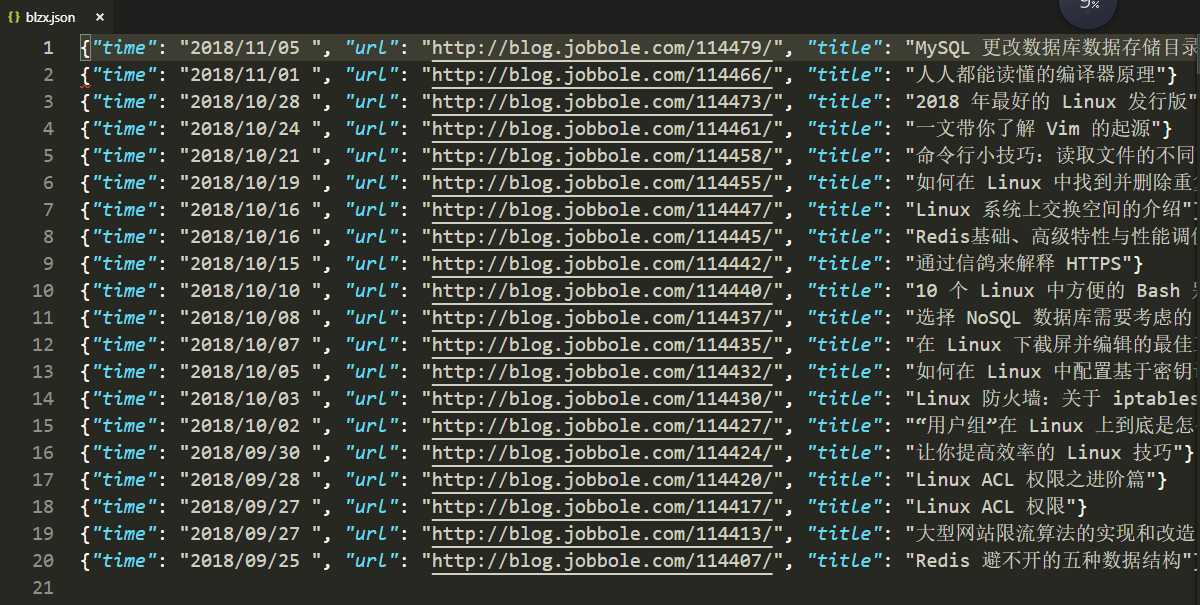
幸苦码字,转载请附链接
标签:方法安装 encoding tps xsl 载器 top ike RoCE mes
原文地址:https://www.cnblogs.com/pywjh/p/9939043.html