标签:val 技术 小顶堆 小问题 添加元素 ast void 各级 isl
一、堆:具有两个附加属性的一颗二叉树
堆是二叉树的扩展,继承了二叉树的所有操作
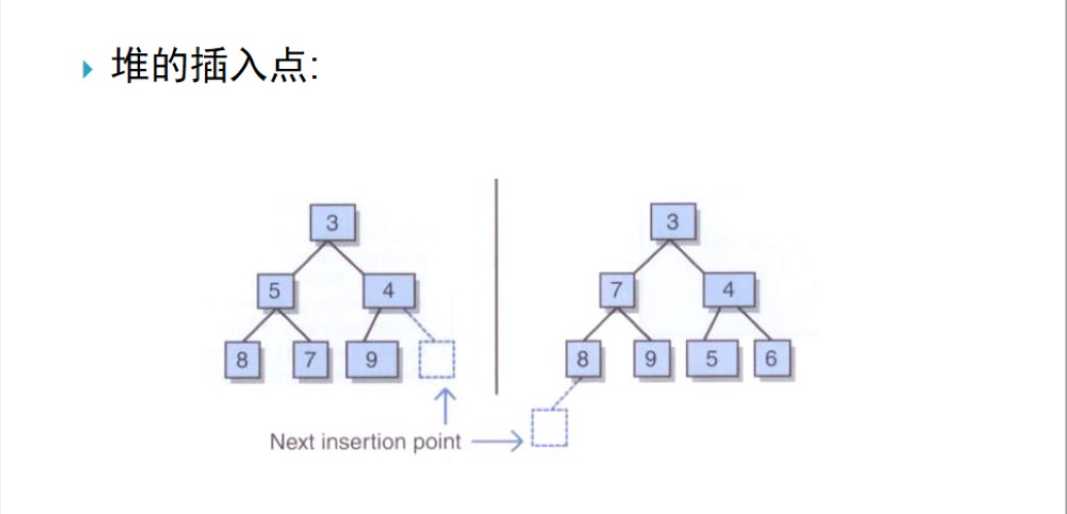
当新结点插入到正确位置之后,就要考虑到排序属性(即将堆调整为大顶堆或小顶堆)
当调整的类型是小顶堆时,做法如下(下图为调整过程):
只需将该新值和其双亲值进行比较,如果该新结点小于其双亲则将它们互换,我们沿着树向上继续这一过程,直至该新值要么是大于其双亲要么是位于该堆的根处
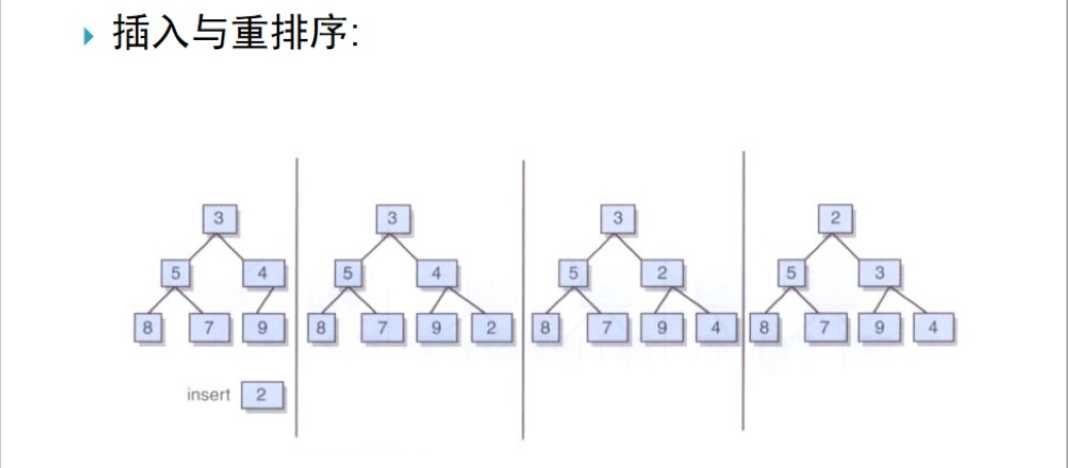
通常,在堆实现中,会对树中的最末一片叶子进行跟踪记录
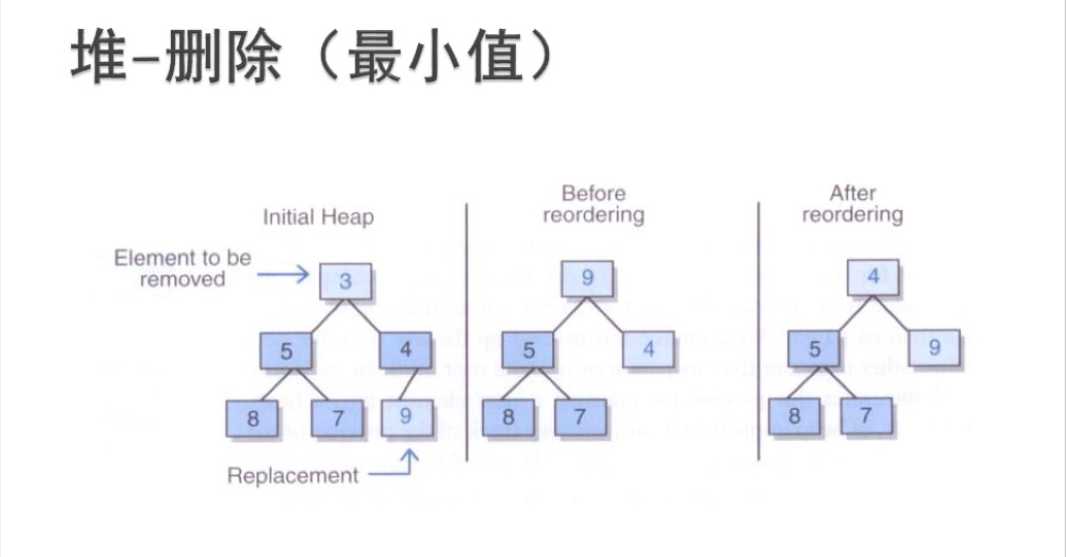
二、使用堆:优先级队列
三、用链表实现堆
* 在恰当位置处添加一个新元素
* 对堆进行重排序以维持其排序属性
* 将lastNode指针重新设定为指向新的最末结点* 用存储在最末结点处的元素替换存储在根处的元素
* 对堆进行重排序(如有必要)
* 返回初始的根元素链表实现的removeMin方法必须删除根元素,并用来自最末结点的元素替换它
四、用数组实现堆
优点:
堆的数组实现提供了一种比链表实现更为简洁的选择。
在链表实现中,我们需要上下将历树以确定树的最末一片叶子或下一个插入结点的双亲(链表实现中的许多复杂问题都与此有关)
这些困难在数组实现中就不存在了,因为通过查看存储在数组中的最末一个元素,我们就能够确定出该树中的最末结点
与链表实现堆的不同之处:
树的根位于位置0,对于每一结点n,n的左孩子将位于数组的2n+1位置处,n的右孩子将位于数组的2(n+1)位置处(反过来同样也是对的)
对于任何除了根之外的结点n,n的双亲位于(n-1)/2位置处,因为我们能够计算双亲和孩子的位置,所以与链表实现不同的是,数组实现不需要创建一个 Heap Node类
在恰当位置处添加新结点
对堆进行重排序以维持其排序属性
将count递增1跟数组实现一样,该方法必须首先检查空间的可用,需要时要进行扩容
数组实现的addElement操作与链表的相同(都为O(logn)),但数组实现的效率更高
用存储在最末元素处的元素替换存储在根处的元素
必要时对堆进行重排序
返回初始的根元素链表实现和数组实现的removeMin操作的复杂度都为O(logn)
五、使用堆:堆排序
使用堆来对某个数字列表进行排序:
将列表的每一元素添加到堆中,然后次一个地将它们从根中删除,
在最小堆的情形下,排序结果将是该列表以升序排列;
在最大堆的情形下,排序结果将是该列表以降序排列
堆排序的复杂度分析:
由于添加和删除操作的复杂度都为O(log n),因此可以得出堆排序的复杂度也是O(log n),但是,这些操作的复杂度为O(log n)指的是在含有n个元素的列表中添加和删除一个元素。
对任一给定的结点,插入到堆的复杂度都是O(log n),因此n个结点的复杂度将是 O(n log n),
删除一个结点的复杂度为O(log n),因此对n个结点的复杂度为 O(n log n)
对于堆的排序算法,我们需要执行addElement和 removeElement两个操作n次,即列表中每个元素一次。因此,最终的复杂度为2 x n x logn,即 O(n log n)
首先,先从数组和链表本身来看:
一个常见的编程问题: 遍历同样大小的数组和链表, 哪个比较快?
如果按照教科书上的算法分析方法,你会得出结论,这2者一样快, 因为时间复杂度都是 O(n)
但是在实践中, 这2者却有极大的差异:
通过下面的分析你会发现, 其实数组比链表要快很多
首先介绍一个概念:memory hierarchy (存储层次结构),电脑中存在多种不同的存储器,如下表

各级别的存储器速度差异非常大,CPU寄存器速度是内存速度的100倍! 这就是为什么CPU产商发明了CPU缓存。 而这个CPU缓存,就是数组和链表的区别的关键所在。
CPU缓存会把一片连续的内存空间读入, 因为数组结构是连续的内存地址,所以数组全部或者部分元素被连续存在CPU缓存里面, 平均读取每个元素的时间只要3个CPU时钟周期。
而链表的节点是分散在堆空间里面的,这时候CPU缓存帮不上忙,只能是去读取内存,平均读取时间需要100个CPU时钟周期。
这样算下来,数组访问的速度比链表快33倍!这里只是介绍概念,具体的数字因CPU而异)
【参考资料】
从cpu和内存来理解为什么数组比链表查询快
第一个PrioritizedObject类:
PrioritizedObject对象表示优先队列中的一个节点,包含一个可比较的对象、到达顺序和优先级值
代码如下:
public T getElement()
{
return element;//返回节点值
}
public int getPriority()
{
return priority;//返回节点优先级
}
public int getArrivalOrder()
{
return arrivalOrder;//返回到节点的距离顺序
}
PrioritizedObject最重要的方法是优先级的比较:
代码如下:
public int compareTo(PrioritizedObject obj) //如果此对象的优先级高于给定对象,则返回1,否则返回-1
{
int result;
if (priority > obj.getPriority())
result = 1;
else if (priority < obj.getPriority())
result = -1;
else if (arrivalOrder > obj.getArrivalOrder())
result = 1;
else
result = -1;
return result;
}先比较元素的优先级,高的先输出;
如果优先级一样,再根据先进先出的方式把距离节点近的先输出
---------------------------------------------------------------------------------------------------------------------------------
第二个就是PriorityQueue类:
首先是添加操作:
public void addElement(T object, int priority)
{
PrioritizedObject<T> obj = new PrioritizedObject<T>(object, priority);
super.addElement(obj);
}声明PrioritizedObject变量之后,即确定了添加元素及其优先级
这里就直接调用了堆的addElement方法,完成添加功能
然后是删除操作:直接调用堆的删除最小值的方法,因为最小的元素是在堆顶处的,即队列的头部
public T removeNext() //从优先级队列中删除下一个最高优先级元素并返回对它的引用
{
PrioritizedObject<T> obj = (PrioritizedObject<T>)super.removeMin();
return obj.getElement();
}感觉很奇怪,但是仔细想了一下:
队列只要满足队尾加元素,队头删除元素就行了,对队列中的元素顺序没有要求,只要在下次删除元素前,按照优先级把元素排好就行了把
(就像医院排队挂号一样:要考虑到军人这一优先级的存在,要先于其他人输出)
这一题就不用考虑到优先这一条件了
然后第二个问题,能用队列来实现堆吗?
这个问题。。。先留在这里。。。哈哈哈哈哈。。。我再想想
现在用堆来实现队列
正如上面教材问题里总结的:
在明白了优先级队列的实现思路后,只要把其类里的形参Priority删掉即可,即去掉优先级比较的这一操作
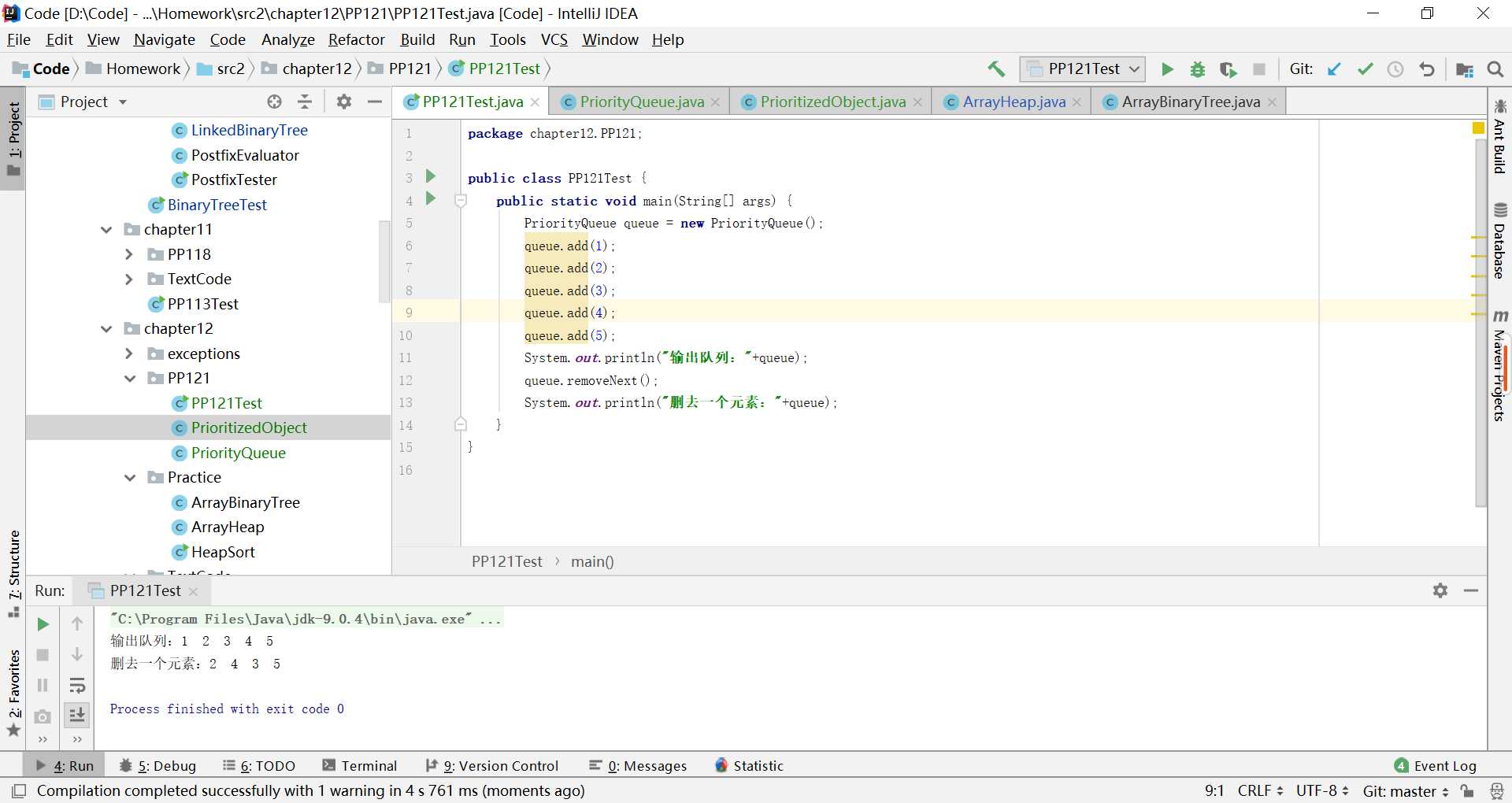
测试结果如下:
【参考资料】
百度百科
优先级队列和队列有什么区别?
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 4/4 | |
| 第二周 | 560/560 | 1/2 | 6/10 | |
| 第三周 | 415/975 | 1/3 | 6/16 | |
| 第四周 | 1055/2030 | 1/4 | 14/30 | |
| 第五周 | 1051/3083 | 1/5 | 8/38 | |
| 第六周 | 785/3868 | 1/6 | 16/54 | |
| 第七周 | 733/4601 | 1/7 | 20/74 | |
| 第八周 | 2108/6709 | 1/8 | 20/74 |
标签:val 技术 小顶堆 小问题 添加元素 ast void 各级 isl
原文地址:https://www.cnblogs.com/zhouyajie/p/9922617.html