标签:类型 哈希表 表达式 情况 移除 red 两个指针 boolean ret
本次实验主要是关于树的应用, 涉及了二叉树、决策树、表达式树、二叉查找树、红黑树五种树的类型,是对最近学习内容第十章和第十一章的一个总结。
getRight操作用于返回根的右子树。当树为空时,抛出错误,当树不为空时,通过递归返回根的右子树。public LinkedBinaryTree2<T> getRight()
{
if(root == null) {
throw new EmptyCollectionException("BinaryTree");
}
LinkedBinaryTree2<T> result = new LinkedBinaryTree2<>();
result.root = root.getRight();
return result;
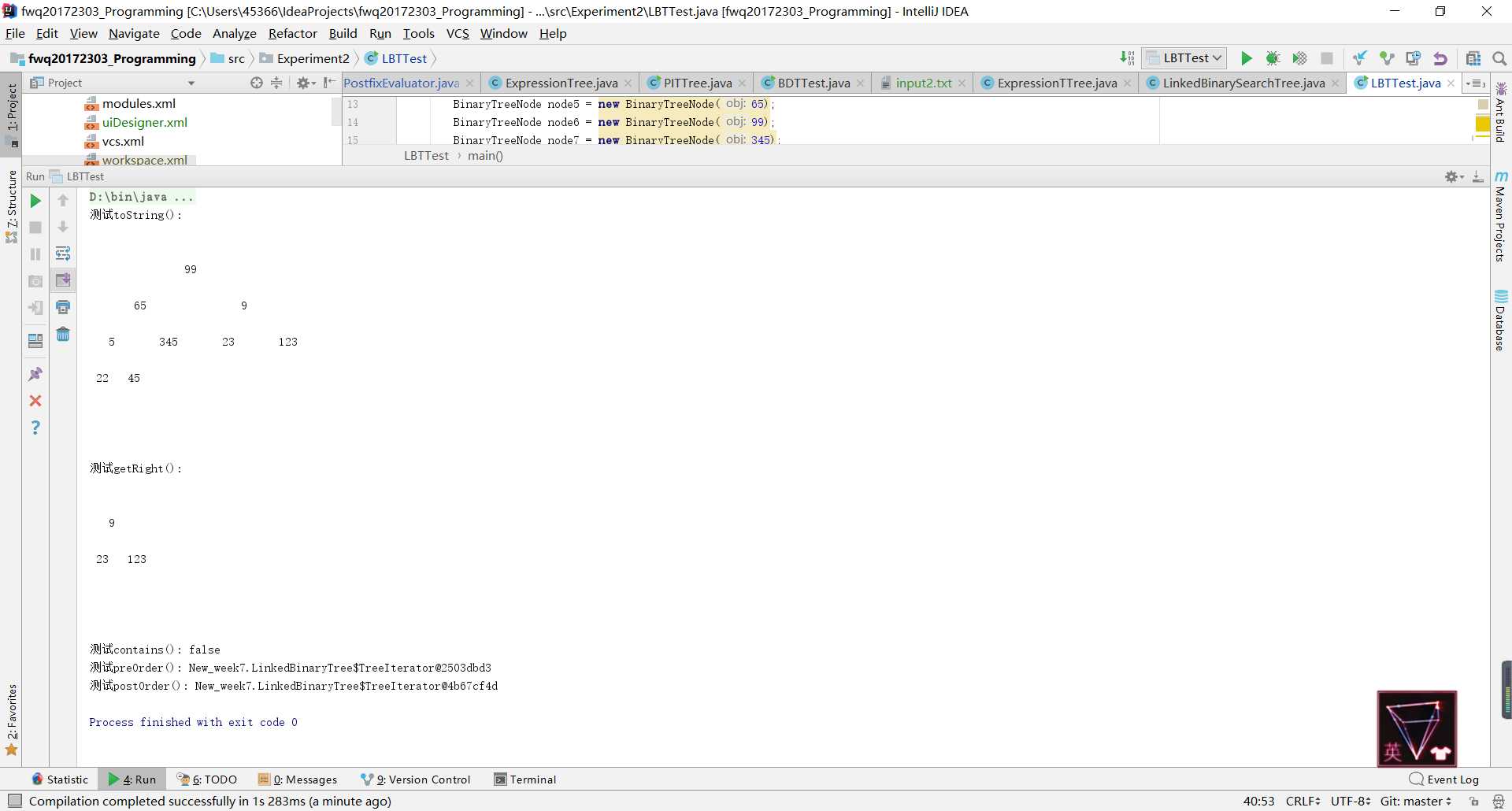
}contains操作的实现有两种方法:一种是直接借用find方法,另一种是重新写一个。
find方法,find方法的作用是在二叉树中找到指定目标元素,则返回对该元素的引用,所以当该元素的引用与查找的元素相同时返回true,否则返回false。public boolean contains(T targetElement)
{
if (find(targetElement) == targetElement){return true;}
else {return false;}
}public boolean contains(T targetElement)
{
BinaryTreeNode node = root;
BinaryTreeNode temp = root;
//找到的情况有三种:查找元素就是根,查找元素位于右子树,查找元素位于左子树。
//除了这三种情况下其余情况都找不到元素,因此初始设置为false
boolean result = false;
//当树为空时,返回false
if (node == null){
result = false;
}
//当查找元素就是根时,返回true
if (node.getElement().equals(targetElement)){
result = true;
}
//对右子树进行遍历(在右子树不为空的情况下)找到元素则返回true,否则对根的左子树进行遍历
while (node.right != null){
if (node.right.getElement().equals(targetElement)){
result = true;
break;
}
else {
node = node.right;
}
}
//对根的左子树进行遍历,找到元素则返回true,否则返回false
while (temp.left.getElement().equals(targetElement)){
if (temp.left.getElement().equals(targetElement)){
result = true;
break;
}
else {
temp = temp.left;
}
}
return result;
}toString方法我借用了ExpressionTree类中的PrintTree方法,具体内容曾在第七周博客中说过。preorder方法由于有inOrder方法的参考所以挺好写的,修改一下三条代码(三条代码分别代码访问根、访问右孩子和访问左孩子)的顺序即可,使用了递归。在输出时为了方便输出我重新写了一个ArrayUnorderedList类的公有方法,直接输出列表,要比用迭代器输出方便一些。public ArrayUnorderedList preOrder(){
ArrayUnorderedList<T> tempList = new ArrayUnorderedList<T>();
preOrder(root,tempList);
return tempList;
}
protected void preOrder(BinaryTreeNode<T> node,
ArrayUnorderedList<T> tempList)
{
if (node != null){
//从根节点开始,先访问左孩子,再访问右孩子
tempList.addToRear(node.getElement());
preOrder(node.getLeft(),tempList);
preOrder(node.getRight(),tempList);
}
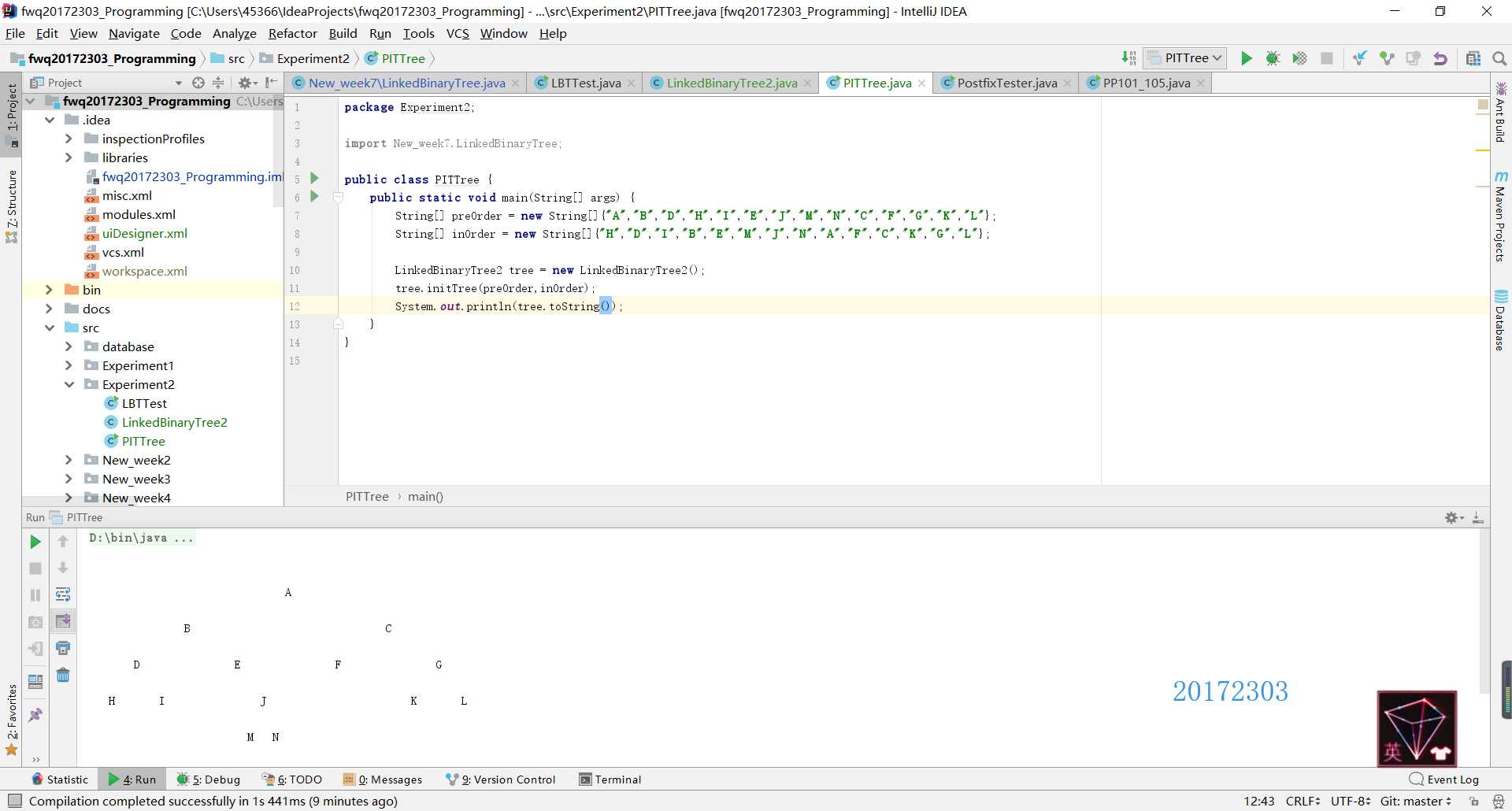
}postOrder方法与preorder方法类似,唯一的区别是后序遍历先访问左孩子,再访问右孩子,最后访问根结点,代码和上面差不多就不放了。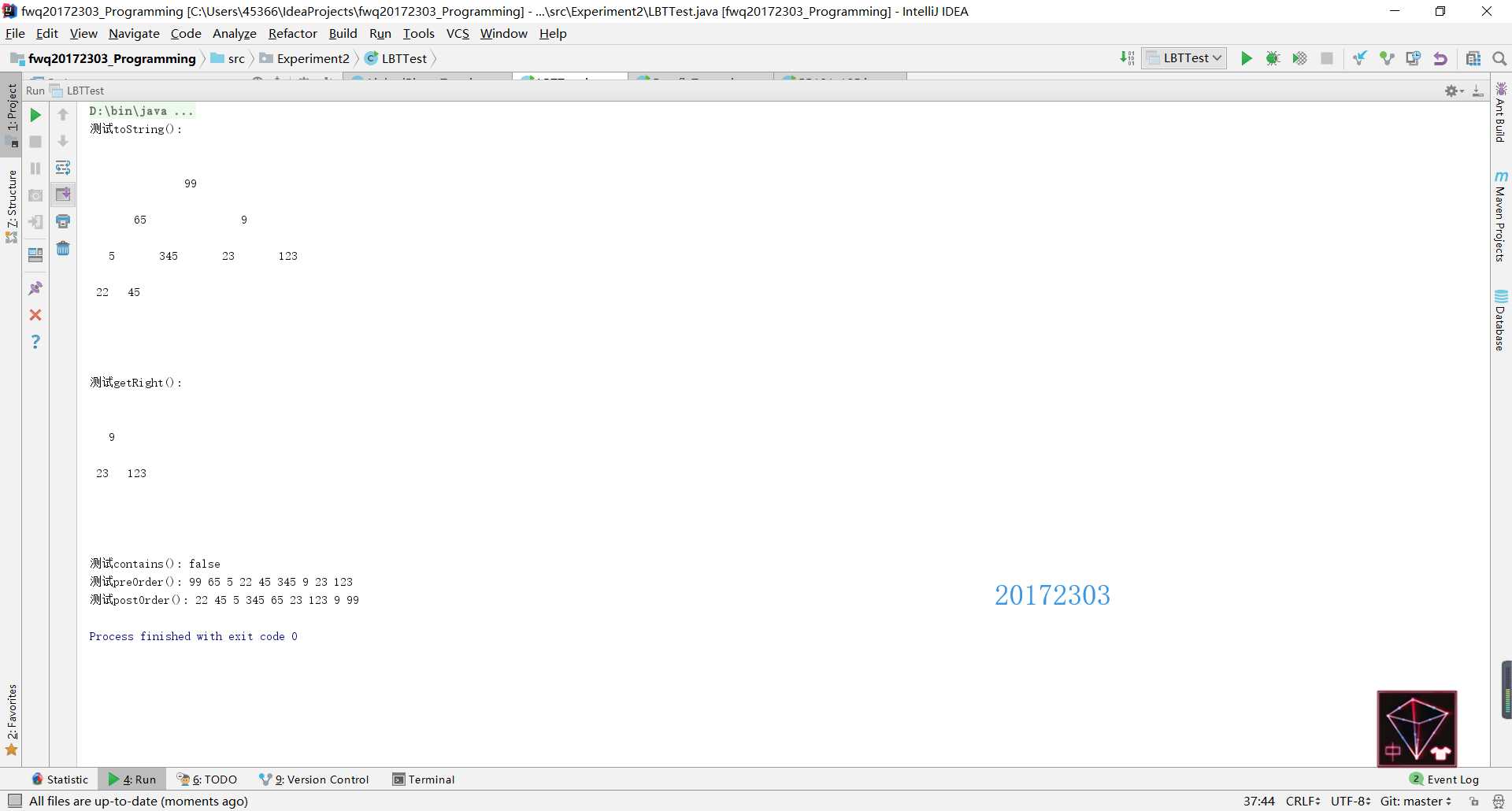
public void initTree(String[] preOrder,String[] inOrder){
BinaryTreeNode temp = initTree(preOrder,0,preOrder.length-1,inOrder,0,inOrder.length-1);
root = temp;
}
private BinaryTreeNode initTree(String[] preOrder,int prefirst,int prelast,String[] inOrder,int infirst,int inlast){
if(prefirst > prelast || infirst > inlast){
return null;
}
String rootData = preOrder[prefirst];
BinaryTreeNode head = new BinaryTreeNode(rootData);
//找到根结点
int rootIndex = findroot(inOrder,rootData,infirst,inlast);
//构建左子树
BinaryTreeNode left = initTree(preOrder,prefirst + 1,prefirst + rootIndex - infirst,inOrder,infirst,rootIndex-1);
//构建右子树
BinaryTreeNode right = initTree(preOrder,prefirst + rootIndex - infirst + 1,prelast,inOrder,rootIndex+1,inlast);
head.left = left;
head.right = right;
return head;
}
//寻找根结点在中序遍历数组中的位置
public int findroot(String[] a, String x, int first, int last){
for(int i = first;i<=last; i++){
if(a[i] == x){
return i;
}
}
return -1;
}
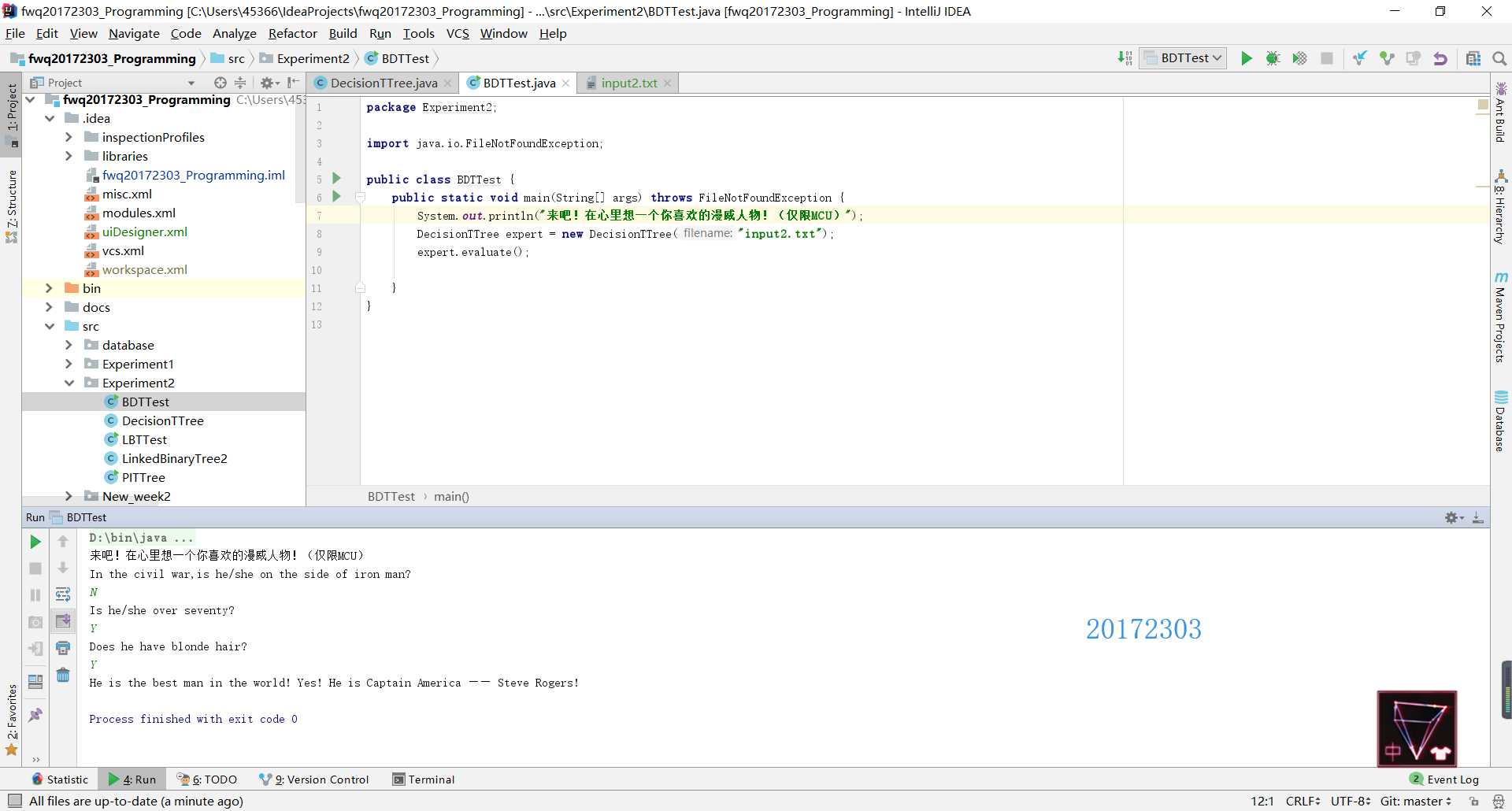
DecisionTree类的实现。
DecisionTree的构造函数从文件中读取字符串元素。存储在树结点中。然后创建新的结点,将之前定义的结点(或子树)作为内部结点的子结点。public DecisionTTree(String filename) throws FileNotFoundException
{
//读取字符串
File inputFile = new File(filename);
Scanner scan = new Scanner(inputFile);
int numberNodes = scan.nextInt();
scan.nextLine();
int root = 0, left, right;
//存储在根结点中
List<LinkedBinaryTree<String>> nodes = new ArrayList<LinkedBinaryTree<String>>();
for (int i = 0; i < numberNodes; i++) {
nodes.add(i,new LinkedBinaryTree<String>(scan.nextLine()));
}
//建立子树
while (scan.hasNext())
{
root = scan.nextInt();
left = scan.nextInt();
right = scan.nextInt();
scan.nextLine();
nodes.set(root, new LinkedBinaryTree<String>((nodes.get(root)).getRootElement(),
nodes.get(left), nodes.get(right)));
}
tree = nodes.get(root);
}evaluate方法从根结点开始处理,用current表示正在处理的结点。在循环中,如果用户的答案为N,则更新current使之指向左孩子,如果用户的答案为Y,则更新current使之指向右孩子,循环直至current为叶子结点时结束,结束后返回current的根结点的引用。public void evaluate()
{
LinkedBinaryTree<String> current = tree;
Scanner scan = new Scanner(System.in);
while (current.size() > 1)
{
System.out.println (current.getRootElement());
if (scan.nextLine().equalsIgnoreCase("N")) {
current = current.getLeft();
} else {
current = current.getRight();
}
}
System.out.println (current.getRootElement());
}
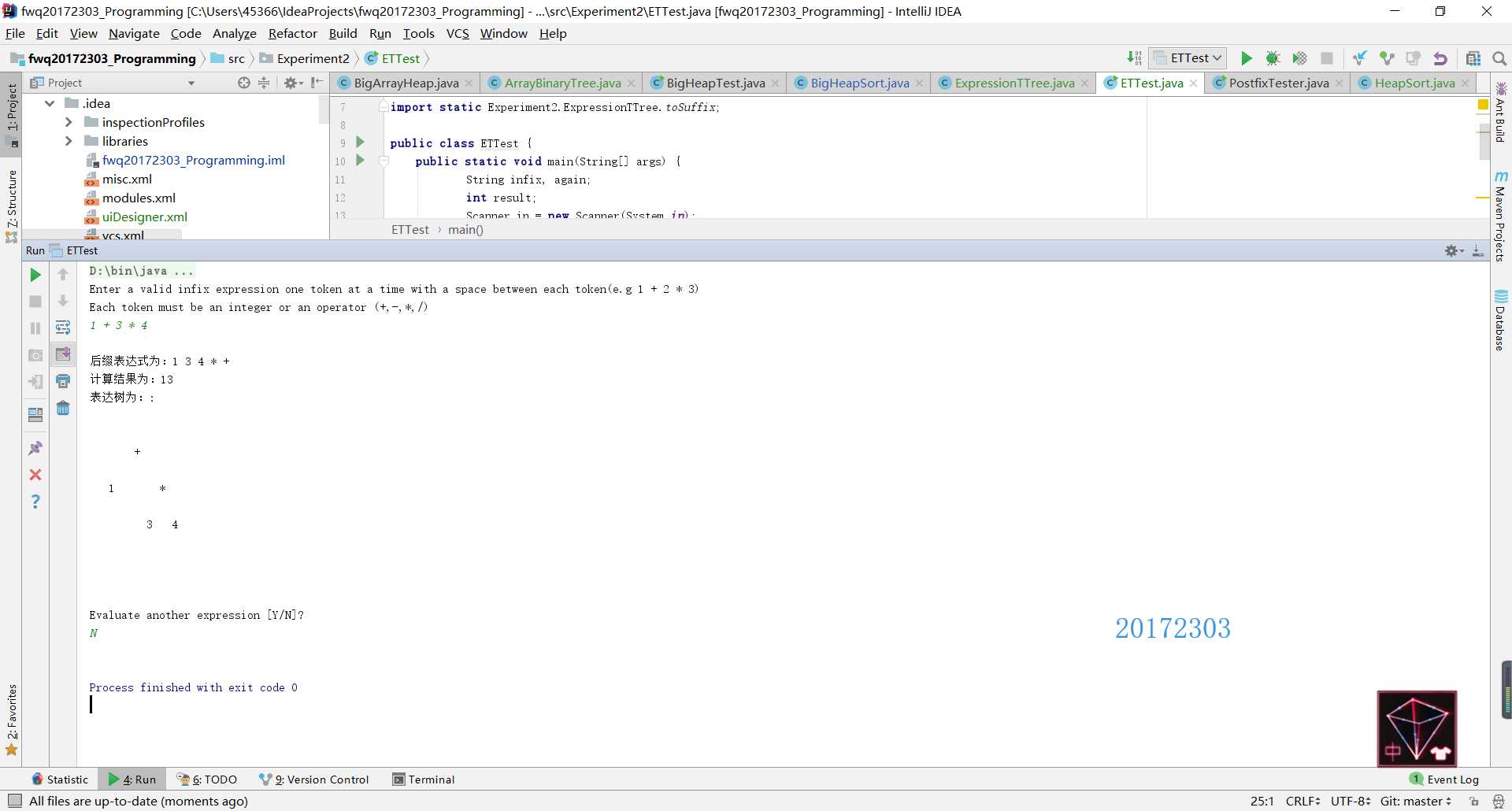
public static String toSuffix(String infix) {
String result = "";
//将字符串转换为数组
String[] array = infix.split("\\s+");
//存放操作数
Stack<LinkedBinaryTree> num = new Stack();
//存放操作符
Stack<LinkedBinaryTree> op = new Stack();
for (int a = 0; a < array.length; a++) {
//如果是操作数,开始循环
if (array[a].equals("+") || array[a].equals("-") || array[a].equals("*") || array[a].equals("/")) {
if (op.empty()) {
//如果栈是空的,将数组中的元素建立新树结点并压入操作符栈
op.push(new LinkedBinaryTree<>(array[a]));
} else {
//如果栈顶元素为+或-且数组的元素为*或/时,将元素建立新树结点并压入操作符栈
if ((op.peek().root.element).equals("+") || (op.peek().root.element).equals("-") && array[a].equals("*") || array[a].equals("/")) {
op.push(new LinkedBinaryTree(array[a]));
} else {
//将操作数栈中的两个元素作为左右孩子,操作符栈中的元素作为根建立新树
LinkedBinaryTree right = num.pop();
LinkedBinaryTree left = num.pop();
LinkedBinaryTree temp = new LinkedBinaryTree(op.pop().root.element, left, right);
//将树压入操作数栈,并将数组中的元素建立新树结点并压入操作符栈
num.push(temp);
op.push(new LinkedBinaryTree(array[a]));
}
}
} else {
//将数组元素建立新树结点并压入操作数栈
num.push(new LinkedBinaryTree<>(array[a]));
}
}
while (!op.empty()) {
LinkedBinaryTree right = num.pop();
LinkedBinaryTree left = num.pop();
LinkedBinaryTree temp = new LinkedBinaryTree(op.pop().root.element, left, right);
num.push(temp);
}
//输出后缀表达式
Iterator itr=num.pop().iteratorPostOrder();
while (itr.hasNext()){
result+=itr.next()+" ";
}
return result;
}
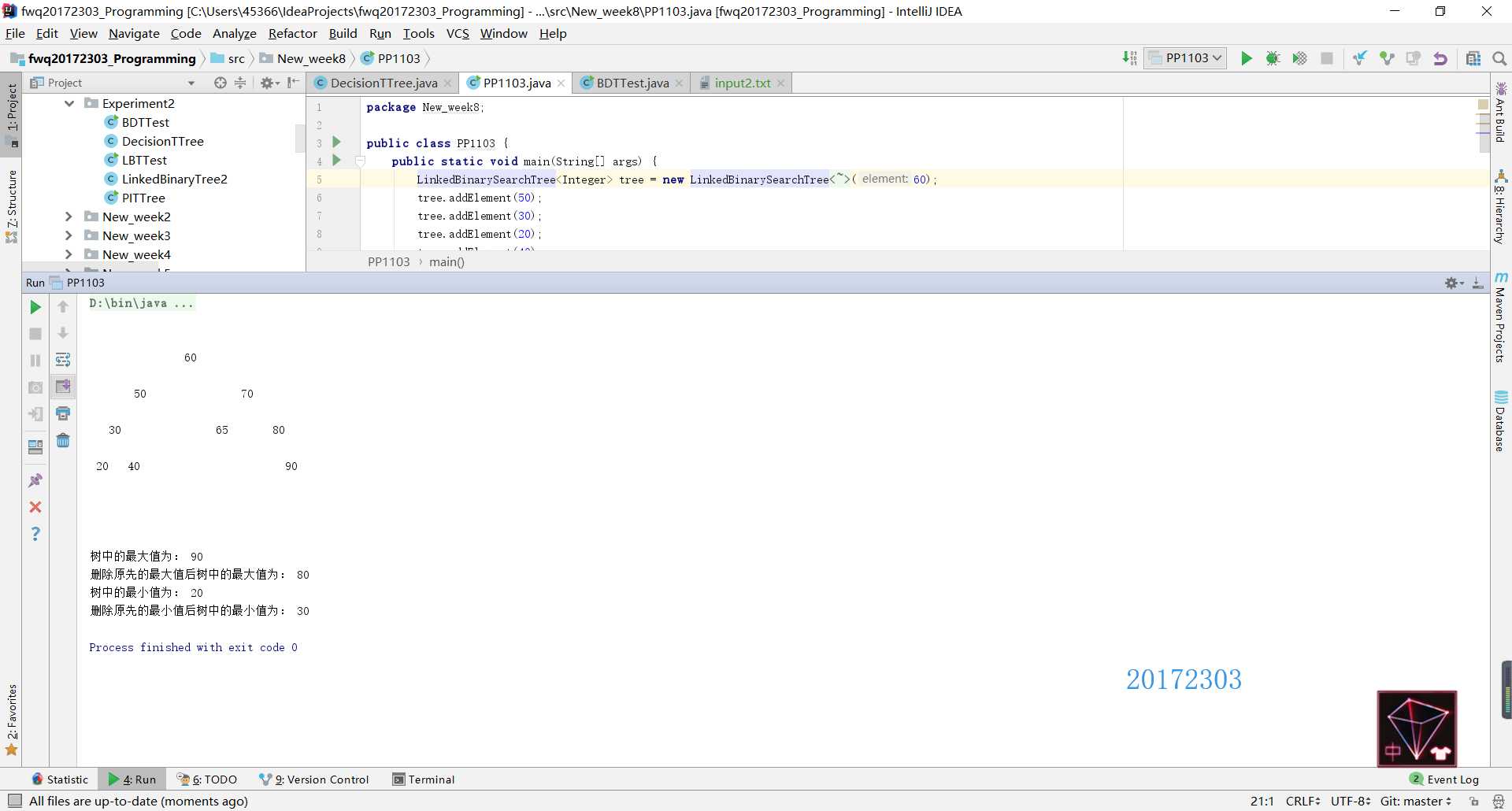
removeMin的实现方法,二叉查找树有一个特殊的性质就是最小的元素存储在树的左边,最大的元素存储在树的右边。因此实现removeMax方法只需要把removeMin方法中所有的left和right对调即可。二叉查找树的删除操作有三种情况,要依据这三种情况来实现代码,我在第七周博客教材内容总结中已经分析过了,就不在这里贴代码了。removeMin和removeMax后,其实findMin和findMax就很简单了,因为在实现删除操作时首先先要找到最大/最小值,因此只要把找到之后的步骤删掉,返回找到的最大值或最小值的元素即可。public T findMin() throws EmptyCollectionException
{
T result;
if (isEmpty()){
throw new EmptyCollectionException("LinkedBinarySearchTree");
}
else {
if (root.left == null){
result = root.element;
}
else {
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.left;
while (current.left != null){
parent = current;
current = current.left;
}
result = current.element;
}
}
return result;
}
public T findMax() throws EmptyCollectionException
{
T result;
if (isEmpty()){
throw new EmptyCollectionException("LinkedBinarySearchTree");
}
else {
if (root.right == null){
result = root.element;
}
else {
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.right;
while (current.right != null){
parent = current;
current = current.right;
}
result = current.element;
}
}
return result;
}
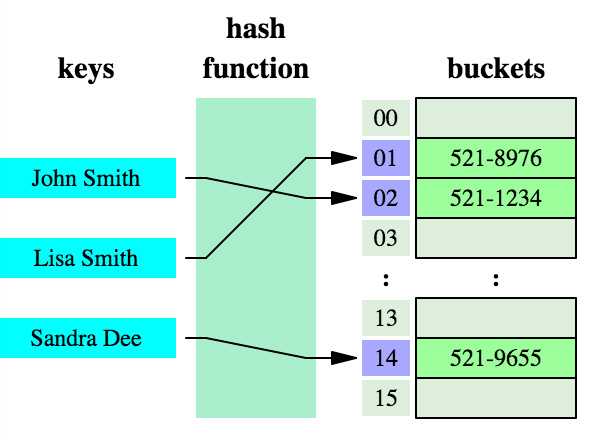
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }

public V get(Object key) {
//当key为空时,返回null
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
if (size == 0) {
return null;
}
//key为null的Entry用于放在table[0]中,但是在table[0]冲突链中的Entry的key不一定为null,因此,需要遍历冲突链,查找key是否存在
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
//首先定位到索引在table中的位置
//然后遍历冲突链,查找key是否存在
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
//当指定键key存在时,返回key的value。
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
//这里用了两个Entry对象,相当于两个指针,为的是防止出现链表指向为空,即冲突链断裂的情况
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
//当table[i]中存在冲突链时,开始遍历里面的元素
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e) //当冲突链只有一个Entry时
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//单个位置链表长度减小到6,将红黑树转化会链表
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* 插入key-value 键值对具体实现
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断 若hashmap内没有值 则重构hashmap
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 若指定位置hashcode 未被占用 则直接将该键值对插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 发生冲突时 解决方法
else {
Node<K,V> e; K k;
// 若地址相同 直接新值替换旧值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 若冲突位置已经是红黑树作为存储结构 则将该键值对插入红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 冲突位置不为红黑树 将该节点插入链表
else {
// 死循环
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 若此时链表内长度大于等于7 将链表转化为红黑树 并将节点插入
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 若带插入数据与存储数据有重复时 结束
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 若容量不足 则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
ArrayUnorderedList类的公有方法,将该无序列表直接输出(代码在节点一的过程中有)。后来实验结束后询问同学学会了将迭代器方法的遍历结果输出。//以后序遍历为例
String result = "";
Iterator itr = tree.iteratorPostOrder();
while (itr.hasNext()){
result += itr.next() + " ";
}
return result;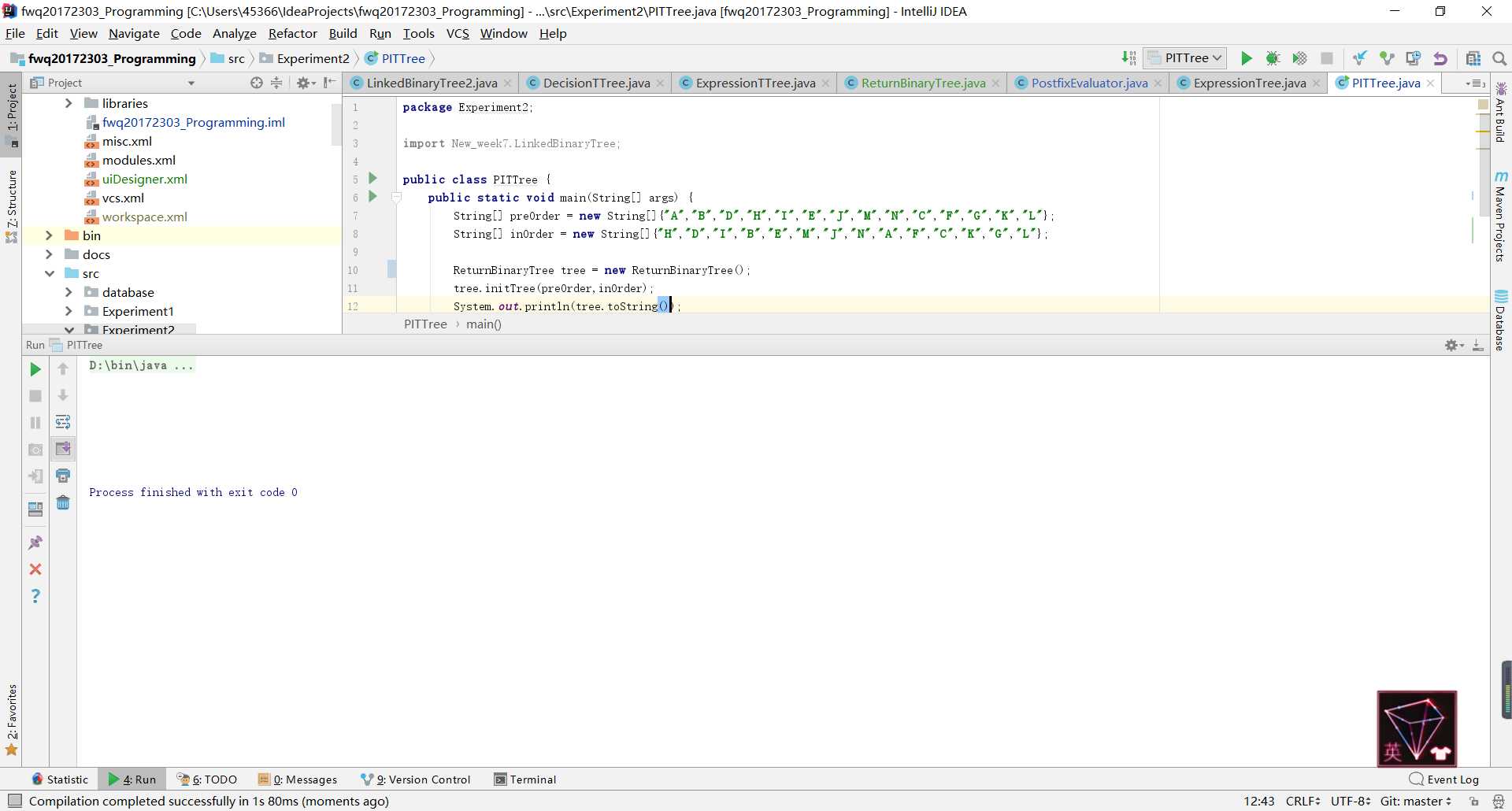
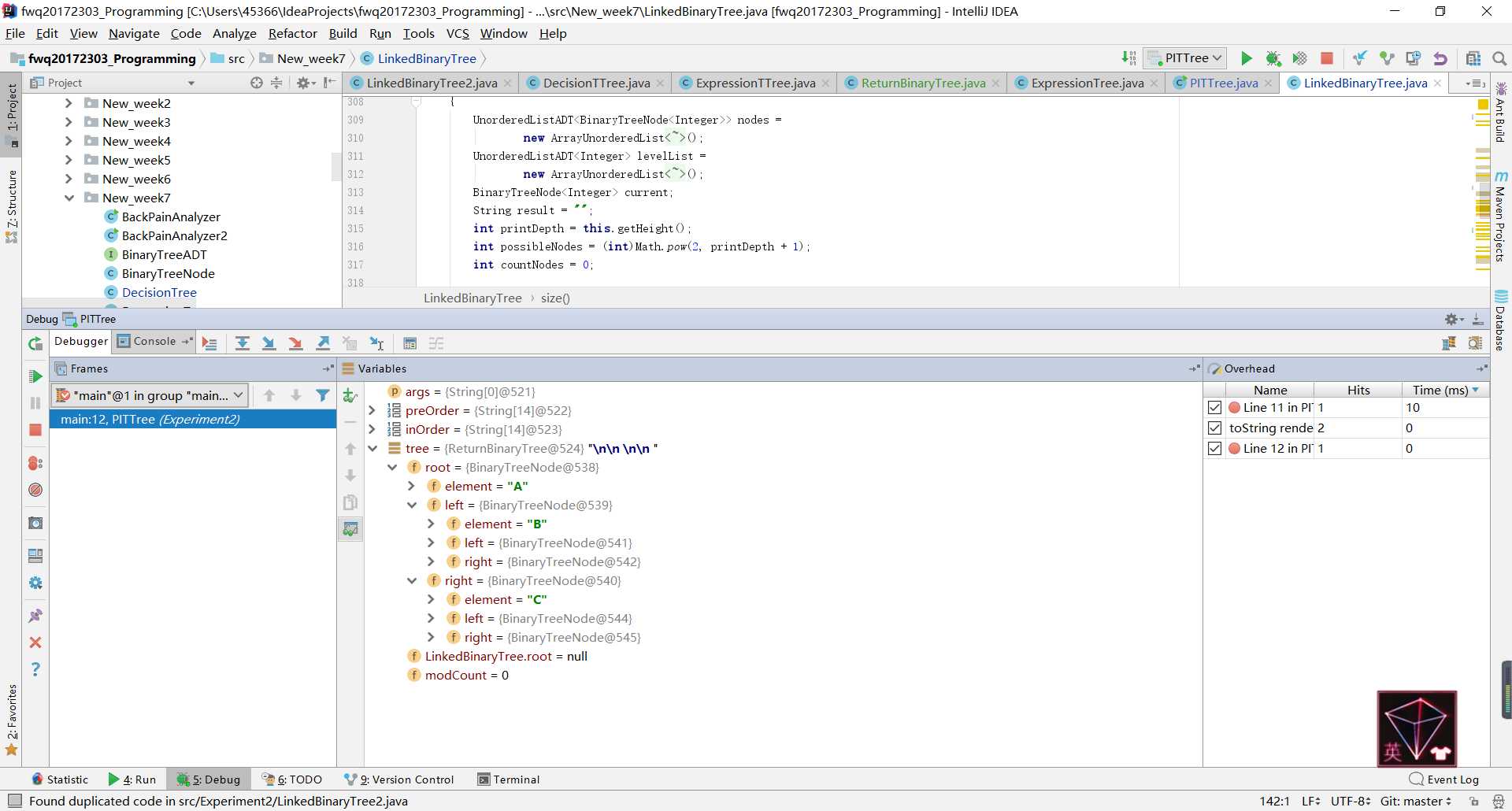
toString方法中,后来发现原因出在了root上,在toString方法中,root从一开始就是空的,并没有获取到我构造的树的根结点。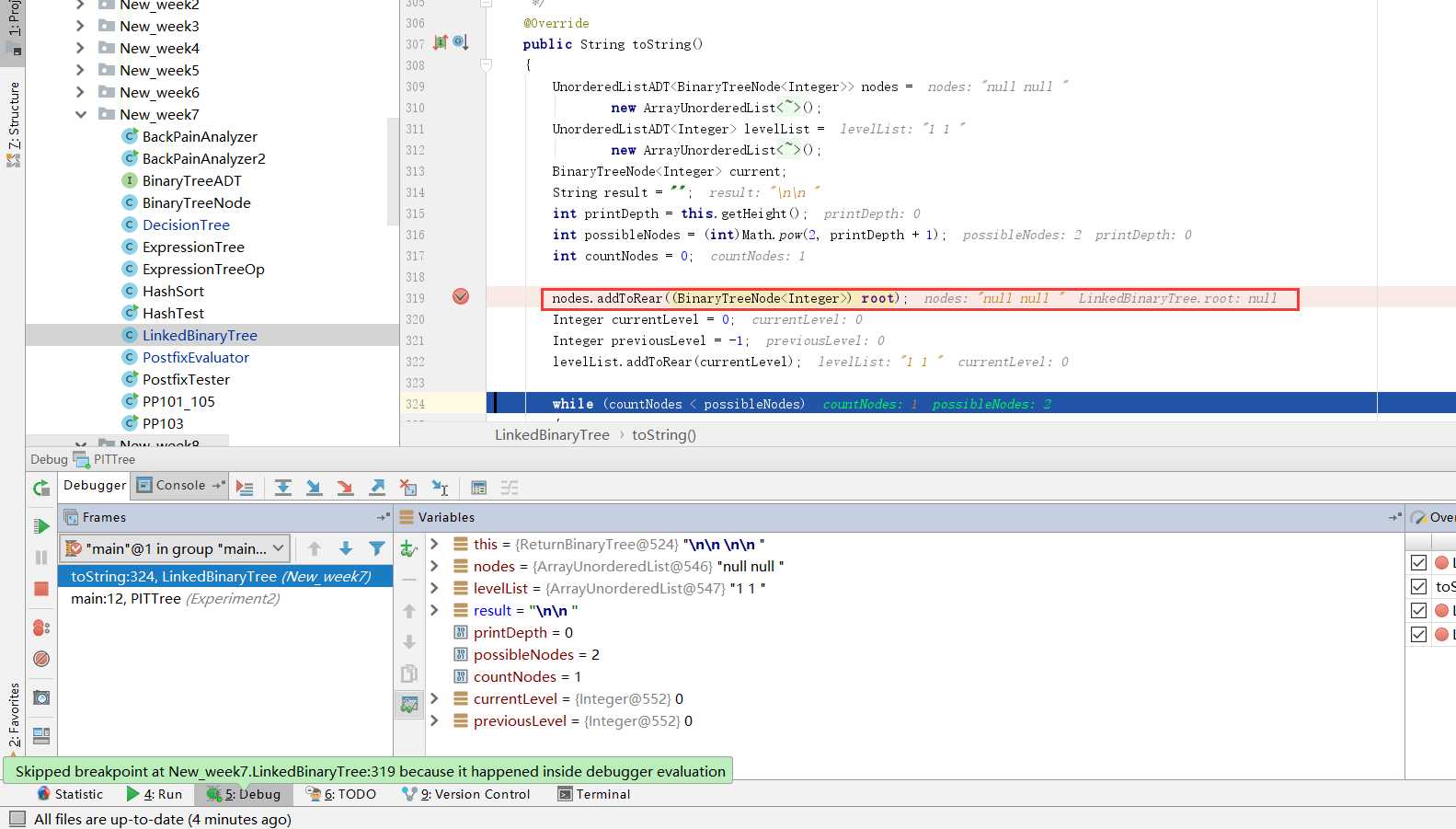
ReturnBinaryTree类中加入了一个获取根的方法,结果最后输出的是根的地址。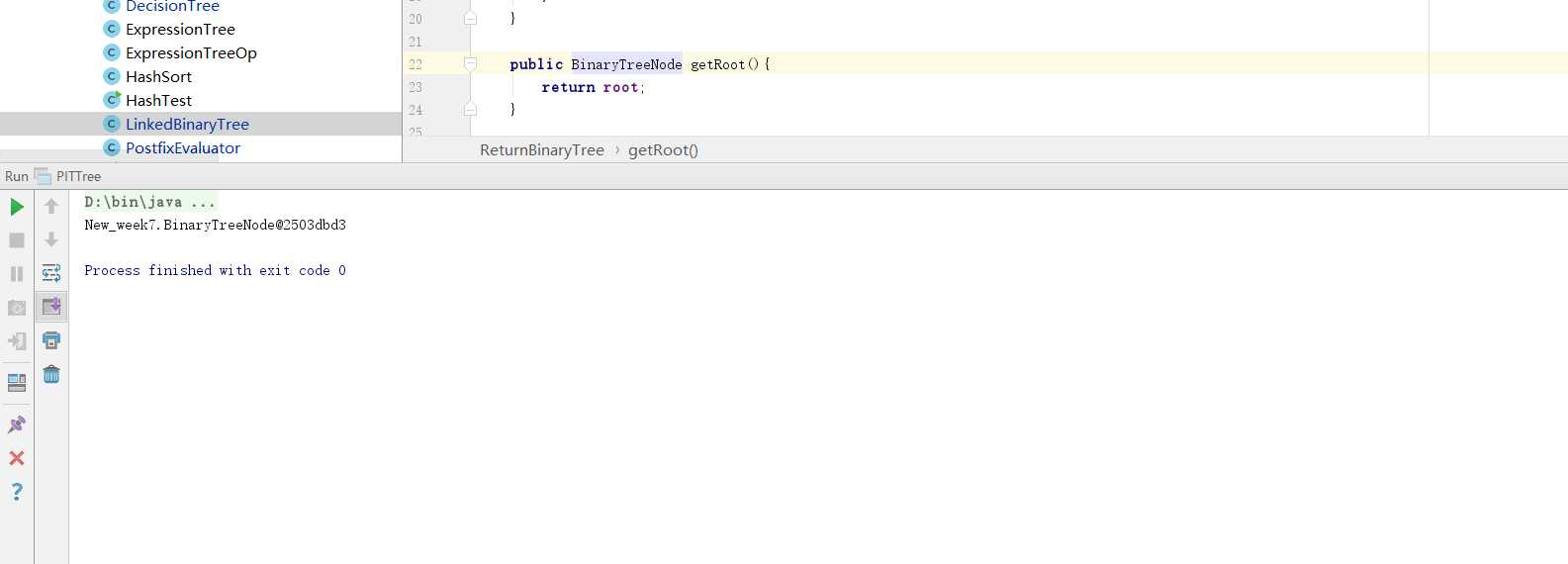
ReturnBinaryTree类中的方法放的toString所在的LinkedBinaryTree类中,因为此时它能够获取到构造的树的根节点,因此就能正常输出了。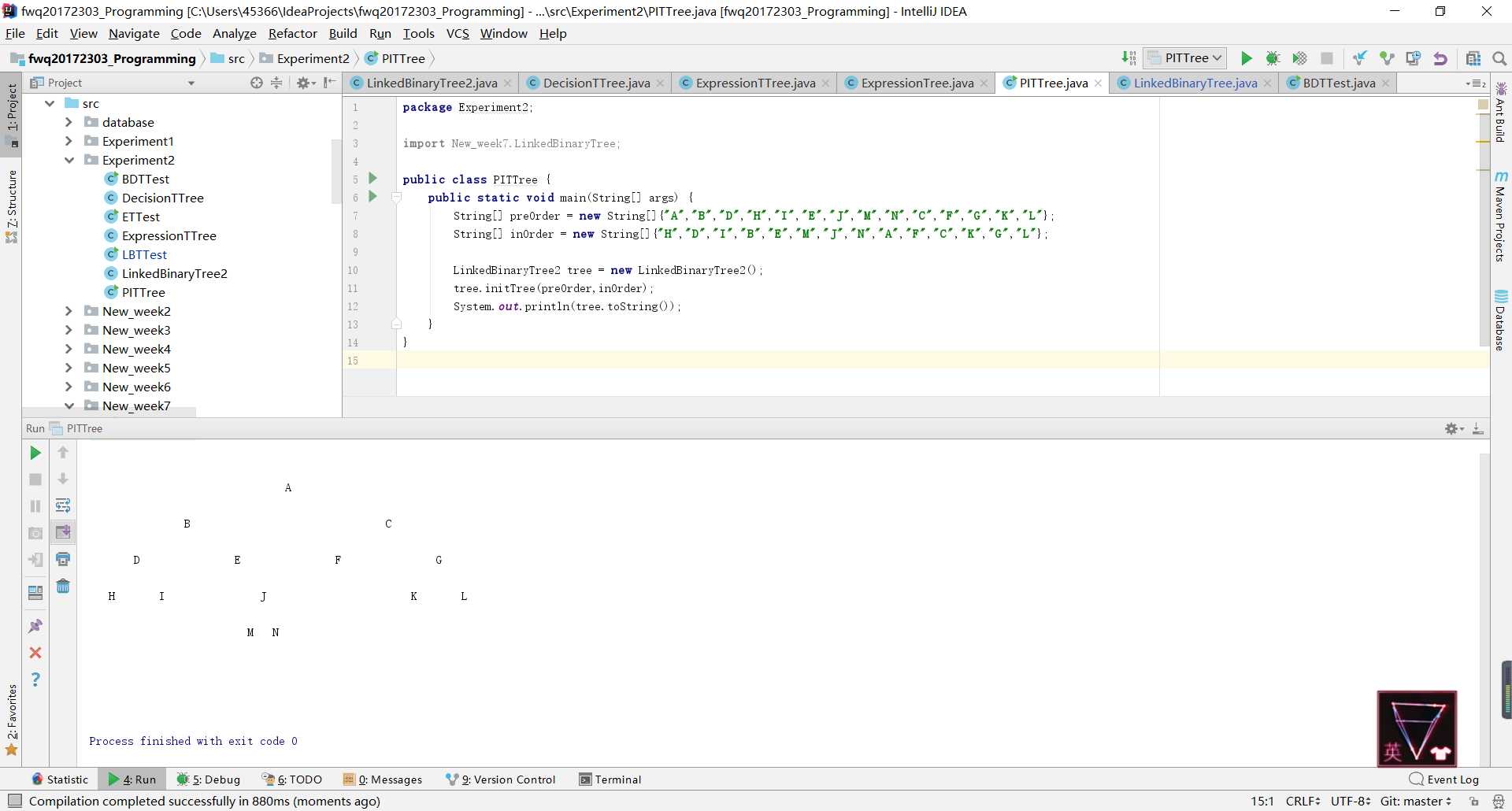
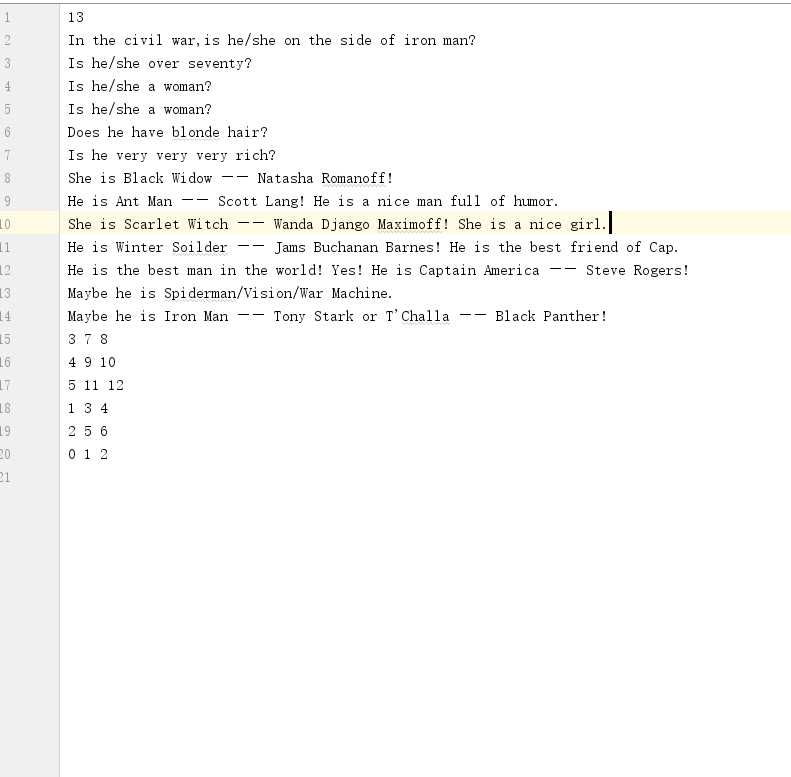
DecisionTree类来看,首先第一行的13代表了这颗决策树中的节点个数,所以在DecisionTree类中的int numberNodes = scan.nextInt();一句其实就是获取文件的第一行记录节点个数的值。接下来文件中按照层序遍历的顺序将二叉树中的元素一一列出来,最后文件中的几行数字其实代表了每个结点及其左右孩子的位置(仍然按照层序遍历的顺序),并且是从最后一层不是叶子结点的那一层的结点开始,比如[3,7,8]就代表了层序遍历中第3个元素的左孩子为第7个元素,右孩子为第8个元素。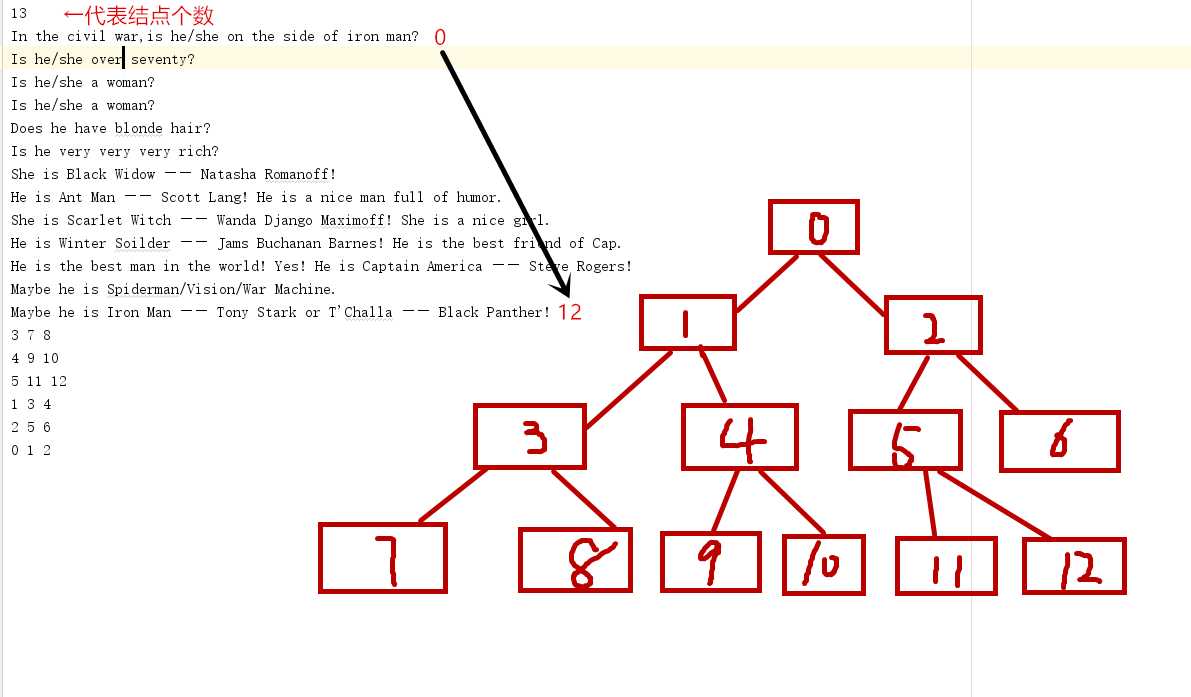

20172303 2018-2019-1 《程序设计与数据结构》实验二报告
标签:类型 哈希表 表达式 情况 移除 red 两个指针 boolean ret
原文地址:https://www.cnblogs.com/PFrame/p/9942394.html