标签:div 报警 报错 空间 etl use where job 效率
因为公司需要使用greenplum,而官方的datax版本在导数据到greenplum时,速度是非常慢的(严格说是datax导数据到postgresql,在导入到GP时,数据走的是master,一条一条insert的,当然是慢)。
所以,这里采用了别人开发好的支持GP 的datax版本:https://github.com/HashDataInc/DataX
首先来说一下GP,GP作为一种数据仓库工具,是比较特殊的,因为一般的etl工具在往GP中导数据普遍是比较慢的。
GP底层就是多个postgresql数据库组成的postgresql集群,由一个master来管理,当然可以有一个standby的master。而一般的etl工具在向GP导数据时,会走master,再由master来分发,效率极其低下。
要用好GP,就需要顺应GP。用GP最喜欢的导入方式去导数据,比如 通过使用copy命令,通过使用gpfdist工具,当然阿里有相应的收费软件也支持快速导入。
本次使用的datax版本,其实是封装了GP的copy方式。
mysql导数据到GP:
{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"*"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://*******:3306/*********?characterEncoding=utf8"
],
"table":[
"********"
]
}
],
"password":"******",
"username":"dev",
"where":""
}
},
"writer":{
"name":"gpdbwriter",
"parameter":{
"column":[
"*"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://*********:5432/**",
"table":[
"**********"
]
}
],
"password":"******",
"postSql":[],
"preSql":[
"**********"
],
"segment_reject_limit":0,
"username":"admin"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
通过测试,1715万条数据355秒
而如果是mysql导入到hdfs,通过测试,1715万条数据211秒
可以看到,使用该版本的datax,导入还是非常快的。
坑:
在往hdfs上导数据时,需要提前将hdfs的目录路径建好,如果路径不存在,会报任务失败。
最大的一个坑下面一个。事情是这样的:
我需要测试一下sqlserver导数据到GP。然而,公司的测试环境中没有sqlserver,所以我在本机中装了一个。
当时装的是sqlserver2005,具体的job的json文件如下:
{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"*"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://*********:3306/******?characterEncoding=utf8"
],
"table":[
"******"
]
}
],
"password":"****************",
"username":"dev",
"where":""
}
},
"writer":{
"name":"sqlserverwriter",
"parameter":{
"column":[
"*"
],
"connection":[
{
"jdbcUrl":"jdbc:sqlserver://**********:1433;DatabaseName=sjtb",
"table":[
"*********"
]
}
],
"password":"**",
"username":"sa"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
在job执行的过程中,出现如下问题:
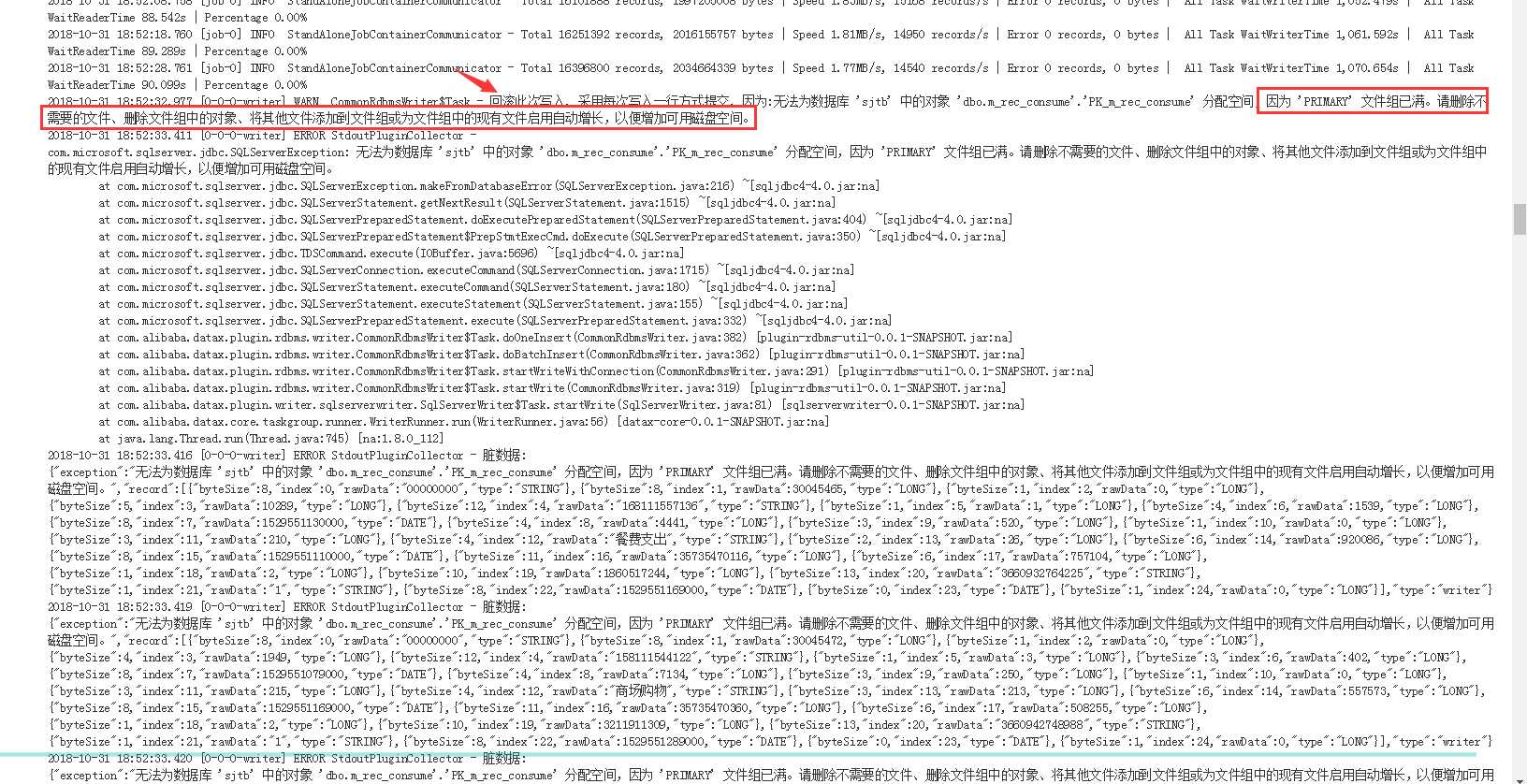
当时我的磁盘空间还有200多个G,所以该问题大概的原因是SQL数据库日志文件满了导致的。结果却让人很意外:

当任务有57万条数据失败时,整个job任然显示success,这样就不会触发邮件报警。这个本身应该是sqlserverver2005的一个限制,需要更换sqlserver的版本到2008就可以了,但是,我们也需要datax做点什么来防止这种情况下任务依旧成功
这里需要配置的是datax的errorlimit
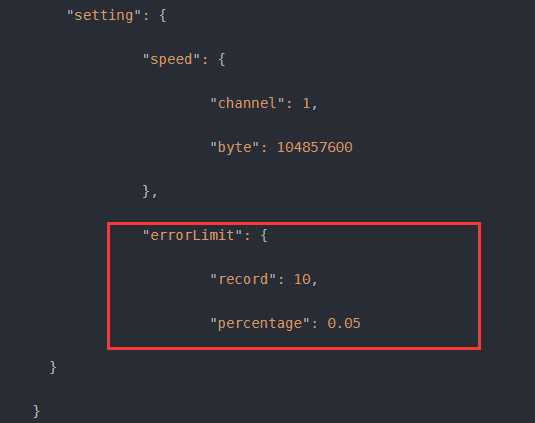
job.setting.errorLimit(脏数据控制)
Job支持用户对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值),当Job传输过程出现的脏数据大于用户指定的数量/百分比,DataX Job报错退出。
上图中的配置的意思是当脏数据大于10条,或者脏数据比例达到0.05%,任务就会报错
标签:div 报警 报错 空间 etl use where job 效率
原文地址:https://www.cnblogs.com/tianyafu/p/9945603.html