标签:else mac har 最小 find 图片 不同类 表示 atl
KNN:k近邻算法-在训练样本中找到与待测样本距离相近的N个样本,并用这N个样本中所属概率最大的类别作为待测样本的类别。
算法步骤:
1、对训练中的样本数据的不同属性进行归一化处理。
2、计算待测样本到训练样本集中的距离。(欧拉距离或曼哈顿距离);
3、找到N个距离最小的样本属于不同类别的概率。
4、取最大的概率作为待测样本的类别。
例子1: 相亲
相亲考虑的条件:
1) 每年飞行公里
2) 每周打的游戏时长
3)每周消耗的ice cream
态度用1,2,3表示:1表示little like 2表示much like 3表示pass
数据集路径https://github.com/pbharrin/machinelearninginaction
matlab 代码:大神请给优化。。。。。
clc,clear;
%1)加载数据
TEST = load(‘datingTestSet2.txt‘);
r1 = find(TEST(:,4) == 1);
r2 = find(TEST(:,4) == 2);
r3 = find(TEST(:,4) == 3);
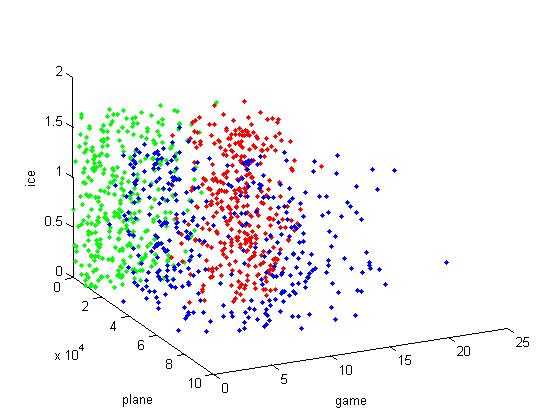
% 1)绘制原始数据
plot3(TEST(r1,1),TEST(r1,2),TEST(r1,3),‘.b‘);
hold on
plot3(TEST(r2,1),TEST(r2,2),TEST(r2,3),‘.g‘);
hold on
plot3(TEST(r3,1),TEST(r3,2),TEST(r3,3),‘.r‘);
xlabel(‘plane‘);
ylabel(‘game‘);
zlabel(‘ice‘);
%对不同属性的数据归一化处理
maxr1 = max(TEST(:,1))
minr1 = min(TEST(:,1));
maxr2 = max(TEST(:,2))
minr2 = min(TEST(:,2));
maxr3 = max(TEST(:,3));
minr3 = min(TEST(:,3));
length = size(TEST(:,1))
TESTB = zeros(length,3);
TESTB(:,1) = (TEST(:,1) - minr1) ./ (maxr1 - minr1);
TESTB(:,2) = (TEST(:,2) - minr2) ./ (maxr2 - minr2);
TESTB(:,3) = (TEST(:,3) - minr3) ./ (maxr3 - minr3);
% 待测数据
DATA = [1000,10,0.5];
DATA(1,1) = (DATA(1,1)- minr1) / (maxr1- minr1);
DATA(1,2) = (DATA(1,2)- minr2) / (maxr2- minr2);
DATA(1,3) = (DATA(1,3)- minr3) / (maxr3- minr3);
% 计算距离 N =5
data = repmat(DATA,[length,1]);
dis = TESTB -data;
dis = dis .* dis;
dis = dis * [1;1;1];
sortData = sort(dis);
ndata = sortData(5,1);
list = find(dis <= ndata);
result = TEST(list,4);
a1 = find(result == 1)
a2 = find(result == 2)
a3 = find(result == 3)
if(size(a1,1) > size(a2,1))
if(size(a1,1)>size(a3,1))
disp(‘ little like‘);
else
disp(‘pass‘);
end
else
if(size(a2,1)>size(a3,1))
disp(‘ much like‘);
else
disp(‘pass‘);
end
end
标签:else mac har 最小 find 图片 不同类 表示 atl
原文地址:https://www.cnblogs.com/kabe/p/9946542.html