标签:访问 分享图片 递增 多个 标识 osal 元数据 rar mes
在深入了解ZooKeeper的运作之前,让我们来看看ZooKeeper的基本概念。我们将在本章中讨论以下主题:
1、Architecture(架构)
2、Hierarchical namespace(层次命名空间)
3、Session(会话)
4、Watch(监视)
看看下面的图表。它描述了ZooKeeper的“客户端-服务器架构”。
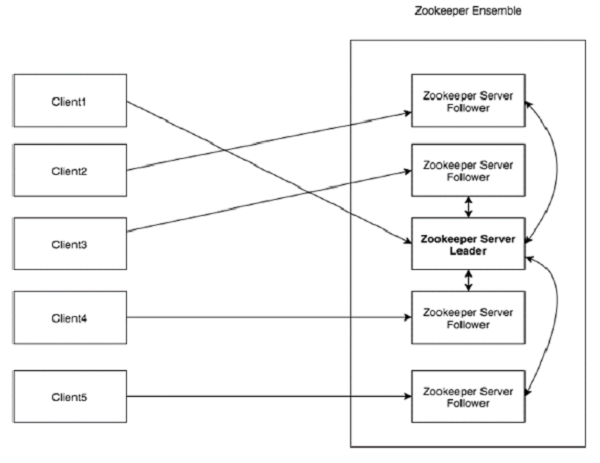
作为ZooKeeper架构的一部分的每个组件在下表中进行了说明。
| 部分 | 描述 |
|---|---|
| Client(客户端) |
客户端,分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。 类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。 |
| Server(服务器) | 服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。 |
| Ensemble | ZooKeeper服务器组。形成ensemble所需的最小节点数为3。 |
| Leader | 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。 |
| Follower | 跟随leader指令的服务器节点。 |
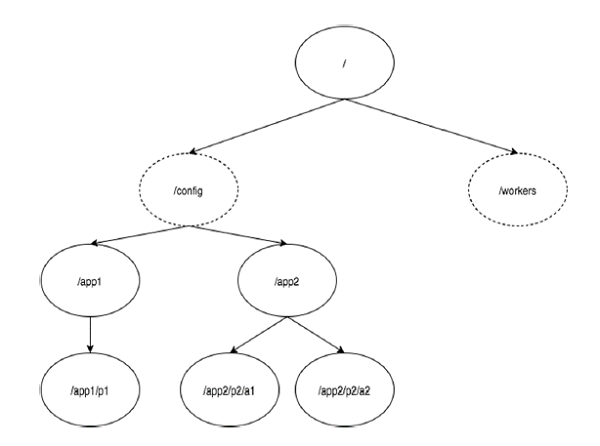
下图描述了用于内存表示的ZooKeeper文件系统的树结构。ZooKeeper节点称为 znode 。每个znode由一个名称标识,并用路径(/)序列分隔。
在图中,首先有一个由“/”分隔的znode。在根目录下,你有两个逻辑命名空间 config 和 workers 。
config 命名空间用于集中式配置管理,workers 命名空间用于命名。
在 config 命名空间下,每个znode最多可存储1MB的数据。这与UNIX文件系统相类似,但是在ZooKeeper中,父znode也可以存储数据。这种结构的主要目的是存储同步数据并描述znode的元数据。此结构称为 ZooKeeper数据模型。
ZooKeeper数据模型中的每个znode都维护着一个 stat 结构。一个stat仅提供一个znode的元数据。它由版本号,操作控制列表(ACL),时间戳和数据长度组成。
版本号 - 每个znode都有版本号,这意味着每当与znode相关联的数据发生变化时,其对应的版本号也会增加。当多个zookeeper客户端尝试在同一znode上执行操作时,版本号的使用就很重要。
操作控制列表(ACL) - ACL基本上是访问znode的认证机制。它管理所有znode读取和写入操作。
时间戳 - 时间戳表示创建和修改znode所经过的时间。它通常以毫秒为单位。ZooKeeper从“事务ID"(zxid)标识znode的每个更改。Zxid 是唯一的,并且为每个事务保留时间,以便你可以轻松地确定从一个请求到另一个请求所经过的时间。
数据长度 - 存储在znode中的数据总量是数据长度。你最多可以存储1MB的数据。
Znode被分为持久(persistent)节点,顺序(sequential)节点和临时(ephemeral)节点。
持久节点 - 即使在创建该特定znode的客户端断开连接后,持久节点仍然存在。默认情况下,除非另有说明,否则所有znode都是持久的。
临时节点 - 客户端活跃时,临时节点就是有效的。当客户端与ZooKeeper集合断开连接时,临时节点会自动删除。因此,只有临时节点不允许有子节点。如果临时节点被删除,则下一个合适的节点将填充其位置。临时节点在leader选举中起着重要作用。
顺序节点 - 顺序节点可以是持久的或临时的。当一个新的znode被创建为一个顺序节点时,ZooKeeper通过将10位的序列号附加到原始名称来设置znode的路径。例如,如果将具有路径 /myapp 的znode创建为顺序节点,则ZooKeeper会将路径更改为 /myapp0000000001 ,并将下一个序列号设置为0000000002。如果两个顺序节点是同时创建的,那么ZooKeeper不会对每个znode使用相同的数字。顺序节点在锁定和同步中起重要作用。
会话对于ZooKeeper的操作非常重要。会话中的请求按FIFO顺序执行。一旦客户端连接到服务器,将建立会话并向客户端分配会话ID 。
客户端以特定的时间间隔发送心跳以保持会话有效。如果ZooKeeper集合在超过服务器开启时指定的期间(会话超时)都没有从客户端接收到心跳,则它会判定客户端死机。
会话超时通常以毫秒为单位。当会话由于任何原因结束时,在该会话期间创建的临时节点也会被删除。
监视是一种简单的机制,用于向客户端通知ZooKeeper集合中的更改。客户端可以在读取特定znode时设置watch。watch会向注册的客户端发送有关znode任何更改的通知。
其中包含znode相关数据修改,或者znode的子项中的更改。
watches只触发一次。如果客户端想再次接收通知,则必须通过另一个读取操作来完成。当连接会话过期时,客户端将与服务器断开连接,相关的watches也将被删除。
一旦ZooKeeper集合启动,它将等待客户端连接。客户端将连接到ZooKeeper集合中的一个节点。它可以是leader或Follower节点。一旦客户端被连接,节点将向特定客户端分配会话ID并向该客户端发送确认。如果客户端没有收到确认,它将尝试连接ZooKeeper集合中的另一个节点。 一旦连接到节点,客户端将以有规律的间隔向节点发送心跳,以确保连接不会丢失。
如果客户端想要读取特定的znode,它将会向具有znode路径的节点发送读取请求,并且节点通过从其自己的数据库获取来返回所请求的znode。为此,在ZooKeeper集合中读取速度很快。
如果客户端想要将数据存储在ZooKeeper集合中,则会将znode路径和数据发送到服务器。连接的服务器将该请求转发给leader,然后leader将向所有的Follower重新发出写入请求。如果大部分节点成功响应,而写入请求成功,发送成功代码到客户端。 否则,写入请求失败。绝大多数节点被称为 Quorum 。
让我们分析在ZooKeeper集合中拥有不同数量的节点的效果。
单个节点,则当该节点故障时,ZooKeeper集合将故障。它将产生“单点故障",不建议在生产环境中使用。
两个节点,一个节点故障。不能称作大多数可用,因为两个中的一个不是多数。
三个节点,一个节点故障。大多数可用。因此,ZooKeeper集合在实际生产环境中必须至少有三个节点。
四个节点,两个节点故障。它将故障。对比与三个节点,多出的节点不起作用。因此,最好添加奇数的节点,例如3,5,7。
写入比读取代价大,因为所有节点都需要写入相同的数据。因此对于读写平衡的环境,拥有较少数量(例如3,5,7)的节点比拥有大量的节点要好。
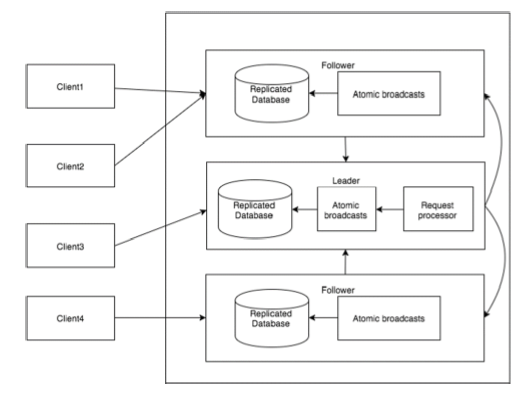
| 组件 | 描述 |
|---|---|
| 写入(write) | 写入过程由leader节点处理。leader将写入请求转发到所有znode,并等待znode的回复。如果一半的znode回复,则写入过程完成。 |
| 读取(read) | 读取由特定连接的znode在内部执行,不需要与集群进行交互。 |
| 复制数据库(replicated database) | 用于在zookeeper中存储数据。每个znode都有自己的数据库,由于ZooKeeper的一致性,每个znode拥有相同的数据。 |
| Leader | leader是负责处理写入请求的znode。 |
| Follower | Follower从客户端接收写入请求,并将它们转发到 leader znode。 |
| 请求处理器(request processor) | 只在leader节点中存在,用于管理来自Follower节点的写入请求。 |
| 原子广播(atomic broadcasts) |
zookeeper atomic broadcast 称为 ZAB协议。
协议中存在着三种状态,每个节点都属于以下三种中的一种:
在ZooKeeper的整个生命周期中每个节点都会在Looking、Following、Leading状态间不断转换:
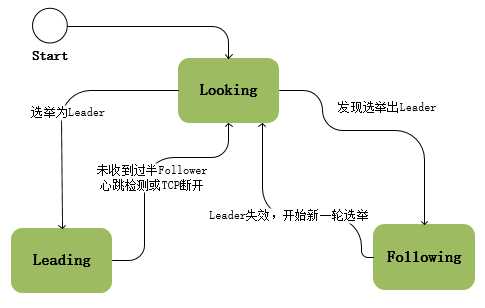
选举出Leader节点后ZAB进入原子广播阶段,这时Leader为和自己同步的每个节点Follower创建一个操作序列
ZAB协议定义了选举(election)、发现(discovery)、同步(sync)、广播(Broadcast)四个阶段;ZAB选举(election)时当Follower存在ZXID(事务ID)时判断所有Follower节点的事务日志,只有lastZXID的节点才有资格成为Leader,这种情况下选举出来的Leader总有最新的事务日志,基于这个原因ZoKeeper实现时把发现(discovery)与同步(sync)合并为恢复(recovery)阶段
(1)选举 Election
election阶段必须确保选出的Leader具有highestZXID,否则在Recovery阶段没法保证数据的一致性,Recovery阶段Leader要求Follower向自己同步数据没有Follower要求Leader保持数据同步,所有选举出来的Leader要具有最新的ZXID。
在选举的过程中会对每个Follower节点的ZXID进行对比只有highestZXID的Follower才可能当选Leader。
选举流程:
ZAB协议中使用ZXID作为事务编号,ZXID为64位数字,低32位为一个递增的计数器,每一个客户端的一个事务请求时Leader产生新的事务后该计数器都会加1,高32位为Leader周期epoch编号,当新选举出一个Leader节点时Leader会取出本地日志中最大事务Proposal的ZXID解析出对应的epoch把该值加1作为新的epoch,将低32位从0开始生成新的ZXID;ZAB使用epoch来区分不同的Leader周期。
(2)恢复 Recovery
在election阶段选举出来的Leader已经具有最新的ZXID,所有本阶段的主要工作是根据Leader的事务日志对Follower节点数据进行更新。
Leader:Leader生成新的ZXID与epoch,接收Follower发送过来的FOllOWERINFO(含有当前节点的LastZXID)然后往Follower发送NEWLEADER;Leader根据Follower发送过来的LastZXID根据数据更新策略向Follower发送更新指令。
同步策略:
Follower:往Leader发送FOLLOERINFO指令,Leader拒绝就转到Election阶段;接收Leader的NEWLEADER指令,如果该指令中epoch比当前Follower的epoch小那么Follower转到Election阶段;Follower还有主要工作是接收SNAP/DIFF/TRUNC指令同步数据与ZXID,同步成功后回复ACKNETLEADER,然后进入下一阶段;Follower将所有事务都同步完成后Leader会把该节点添加到可用Follower列表中。
SNAP与DIFF用于保证集群中Follower节点已经Committed的数据的一致性,TRUNC用于抛弃已经被处理但是没有Committed的数据。
(3)广播 Broadcast
客户端提交事务请求时Leader节点为每一个请求生成一个事务Proposal,将其发送给集群中所有的Follower节点,收到过半Follower的反馈后开始对事务进行提交,ZAB协议使用了原子广播协议;在ZAB协议中只需要得到过半的Follower节点反馈Ack就可以对事务进行提交,这也导致了Leader几点崩溃后可能会出现数据不一致的情况,ZAB使用了崩溃恢复来处理数字不一致问题;消息广播使用了TCP协议进行通讯所有保证了接受和发送事务的顺序性。广播消息时Leader节点为每个事务Proposal分配一个全局递增的ZXID(事务ID),每个事务Proposal都按照ZXID顺序来处理;
Leader节点为每一个Follower节点分配一个队列按事务ZXID顺序放入到队列中,且根据队列的规则FIFO来进行事务的发送。Follower节点收到事务Proposal后会将该事务以事务日志方式写入到本地磁盘中,成功后反馈Ack消息给Leader节点,Leader在接收到过半Follower节点的Ack反馈后就会进行事务的提交,以此同时向所有的Follower节点广播Commit消息,Follower节点收到Commit后开始对事务进行提交。
参考资料:
https://www.w3cschool.cn/zookeeper/zookeeper_fundamentals.html
http://www.solinx.co/archives/435
http://web.stanford.edu/class/cs347/reading/zab.pdf
http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
标签:访问 分享图片 递增 多个 标识 osal 元数据 rar mes
原文地址:https://www.cnblogs.com/maxiaodoubao/p/9949816.html