标签:com 去掉注释 复制 输入 mod 情况 切换 ado bubuko
以下是本次搭建说使用的服务器
| IP | 节点名称 | 说明 |
| 192.168.172.130 | master | 主服务器 |
| 192.168.172.131 | slave1 | 从服务器1 |
| 192.168.172.132 | slave2 | 从服务器2 |
1、分别 在三台服务器上新增用户、组
groupadd hadoop useradd -d /home/hadoop -g hadoop -s /bin/bash -m hadoop visudo #在文中root行下添加hadoop行 root ALL=(ALL:ALL) ALL hadoop ALL=(ALL) ALL
vi /etc/hosts #追加如下内容 192.168.172.130 master 192.168.172.131 slave1 192.168.172.132 slave2
vi /etc/hostname #master服务器将内容修改为如下内容 hadoop_master.localdomain #slave1服务器将内容修改为如下内容 hadoop_slave1.localdomain #slave2服务器将内容修改为如下内容 hadoop_slave2.localdomain
#重启服务器 reboot
vim /etc/ssh/sshd_config #找到以下内容,并去掉注释符“#” RSAAuthentication yes PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys
重启sshd服务
/sbin/service sshd restart
本机生成公钥和私钥
本机切换成需要免密码登陆的账户,然后运行以下命令:
ssh-keygen -t rsa
运行后默认会在该账号的home目录下生成~/.ssh/id_rsa: 私钥和~/.ssh/id_rsa.pub:公钥两个文件。
将公钥导入本机认证文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将公钥导入到目标(将远程登录到的服务器)服务器的特定账号(将以该账号登录远程服务器)的认证文件
scp ~/.ssh/id_rsa.pub xxx@目标主机ip或主机名:/home/xxx/id_rsa.pub
然后以相应账号登录到远程服务器,再运行以下命令导入公钥到认证文件
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //将所有服务器的id_rsa.pub相互导入服务器
修改远程服务器相应账号下的.ssh文件夹和authorized_keys文件的权限
chmod 700 ~/.ssh
chmod 710 ~/.ssh/authorized_keys
测试是否配置成功
在 master 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh slave1 ssh slave2
在 slave1 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh master ssh slave2
在 slave2 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh master ssh slave1
若上面操作始终提示需要输入密码,尝试修改hadoop用户组再重复上面操作
usermod -G root hadoop
mkdir -p /usr/local/java
下载jdk1.8版本,并将其解压到/usr/local/java目录下
tar -zxf jdk-8u65-linux-x64.tar.gz -C /usr/local/java/
配置环境变量
vi /etc/profile #在配置文件的最后添加如下配置 #JAVA JAVA_HOME=/usr/local/java/jdk1.8.0_65 #自己解压后的jdk目录名称 JRE_JOME=/usr/local/java/jdk1.8.0_65/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_JOME CLASS_PATH PATH
保存退出后,执行以下命令刷新环境变量
source /etc/profile
进行测试是否成功
java -version
cd /usr/local/ sudo wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.1.1/hadoop-3.1.1.tar.gz
#解压配置环境变量
tar -zxf hadoop-3.1.1.tar.gz -C /usr/local/hadoop/
配置hadoop环境变量
vi /etc/profile #在配置文件最后一行添加如下配置 #HADOOP export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
运行如下命令刷新环境变量
source /etc/profile
进行测试是否成功
hadoop version
配置Hadoop3.1.1
#在/usr/local/hadoop目录下创建目录 cd /usr/local/hadoop/ mkdir tmp mkdir var mkdir dfs mkdir dfs/name mkdir dfs/data
进入hadoop的配置文件目录下,修改配置文件
cd /usr/local/hadoop/hadoop-3.1.1/etc/hadoop vi workers
#删除localhost,添加从节点主机名,例如我这里是:
slave1
slave2
vi hadoop-env.sh 在# JAVA_HOME=/usr/java/testing hdfs dfs -ls一行下面添加如下代码 export JAVA_HOME=/usr/local/java/jdk1.8.0_65 export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1 export HDFS_NAMENODE_USER=hadoop export HDFS_DATANODE_USER=hadoop export HDFS_SECONDARYNAMENODE_USER=hadoop export YARN_RESOURCEMANAGER_USER=hadoop export YARN_NODEMANAGER_USER=hadoop
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/core-site.xml
内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.172.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
内容如下:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
<description>
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
<description>
Comma separated list of paths on the localfilesystem of a DataNode where it should store itsblocks.
</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.172.130:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.172.130:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
在命令行下输入如下命令,并将返回的地址复制,在配置下面的yarn-site.xml时会用到。
hadoop classpath
将上面命令获取的到结果复制一下,下面会用到
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/yarn-site.xml
内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
</configuration>
以下命令一条一条执行
scp -r /usr/local/java slave1:/usr/local/java scp -r /usr/local/hadoop slave1:/usr/local/hadoop scp -r /etc/profile slave1:/etc/ scp -r /usr/local/java slave2:/usr/local/java scp -r /usr/local/hadoop slave2:/usr/local/hadoop scp -r /etc/profile slave2:/etc/
上面的所有命令都执行完之后,分别在slave1、slave2刷新环境变量
source /etc/profile
hdfs namenode -format
start-all.sh
启动完之后在master、slave1、slave2上执行如下命令,查看启动情况
jps
在浏览器查看启动情况:http://192.168.172.130:8088/cluster
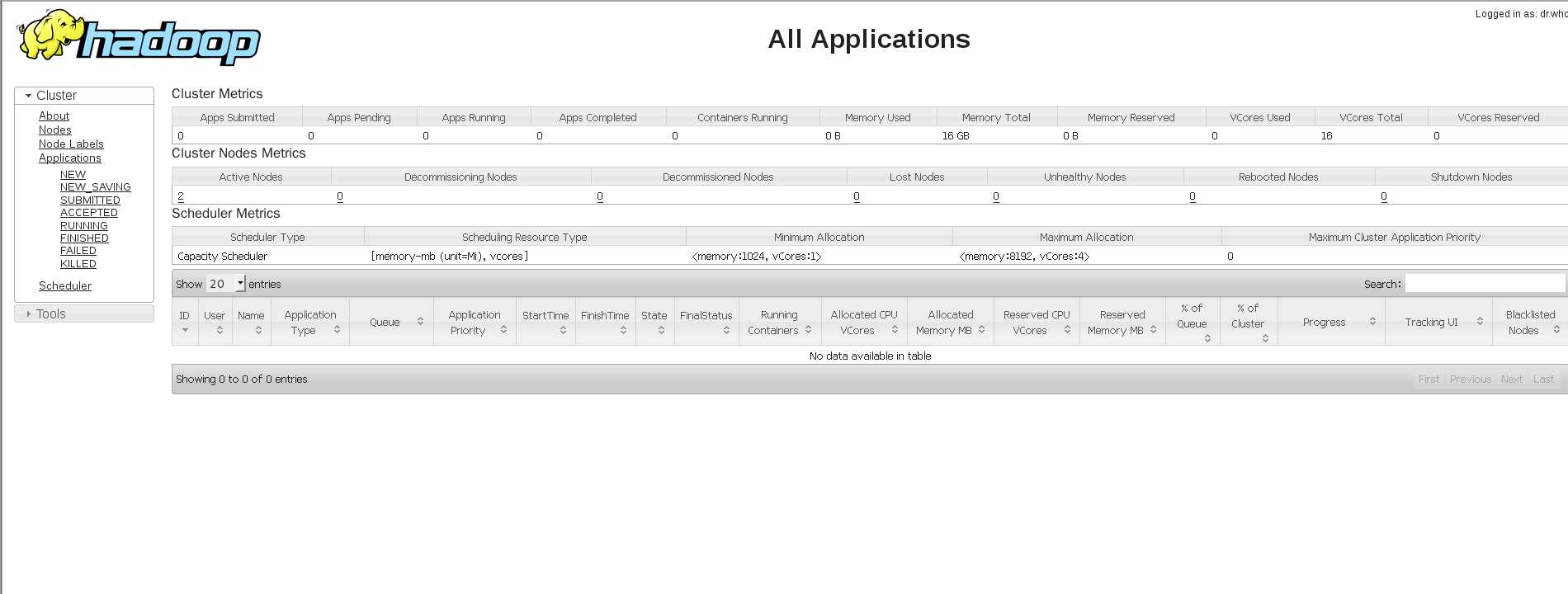
或者 http://192.168.172.130:50070/dfshealth.html#tab-overview
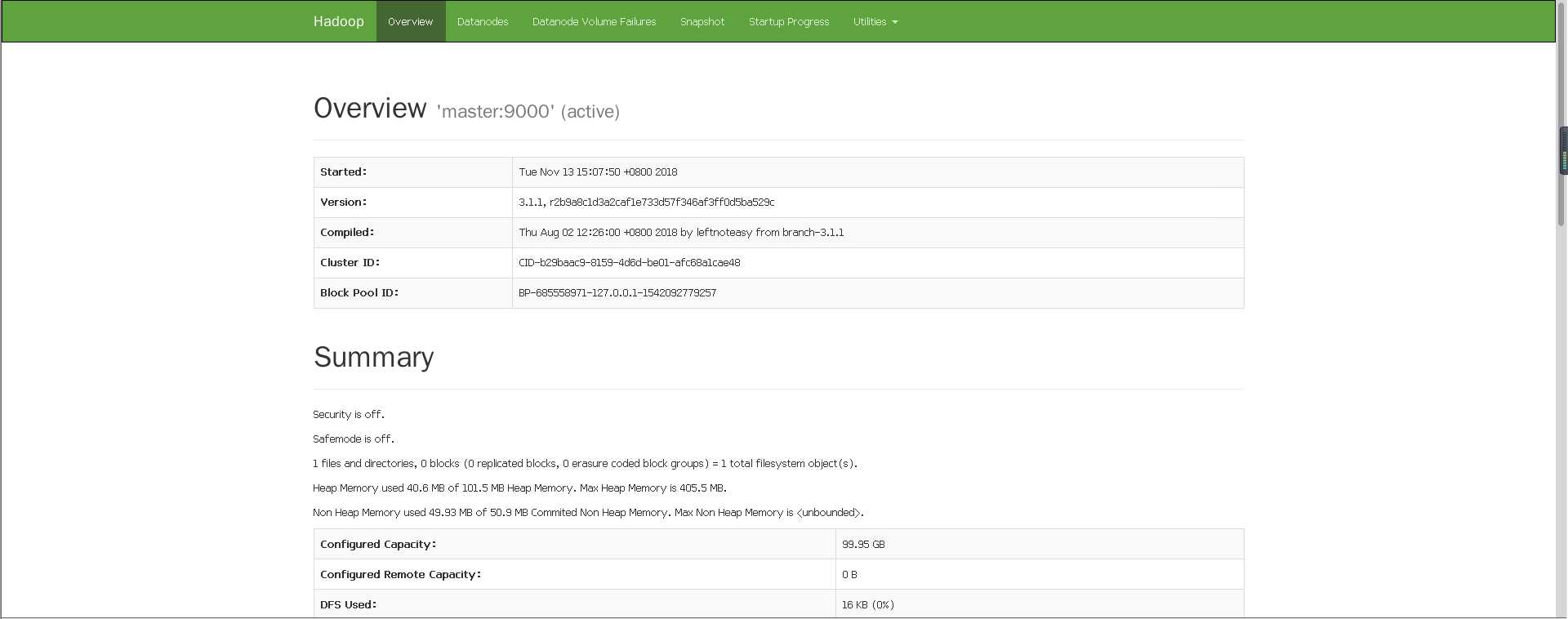
标签:com 去掉注释 复制 输入 mod 情况 切换 ado bubuko
原文地址:https://www.cnblogs.com/cz-xjw/p/9952959.html