标签:blog 硬件 iptables track style cat 命令行 卸载 全分布
Hadoop:hadoop2.5.2 64位
JDK: JDK 1.8.0_91
如果没有足够的权限,可以切换用户为root
三台机器统一增加以下host配置:

2)将id_dsa.pub(公钥)追加到授权key中:
3)将认证文件复制到另外两台DataNode节点上:
scp ~/.ssh/authorized_keys 172.16.1.157:~/.ssh/
3)测试:
查看目前安装openjdk信息:rpm -qa|grep java

卸载以上三个文件(需要root权限,登录root权限卸载)
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e --nodeps tzdata-java-2013g-1.el6.noarch





每台节点都要安装
上传
到用户
目录下。
(5)修改slaves文件,添加datanode节点hostname到slaves文件中
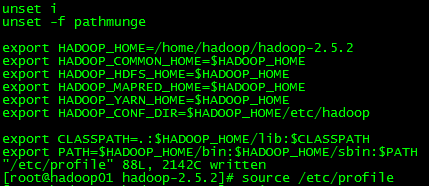
如果已经配置了JAVA_HOME环境变量,hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面配置就是:
export JAVA_HOME=${JAVA_HOME}如果没有配置JAVA_HOME环境变量,需要分别在hadoop-env.sh和yarn-env.sh中
手动添加JAVA_HOME export JAVA_HOME= /home/hadoop/jdk1.8


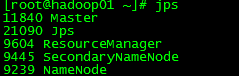

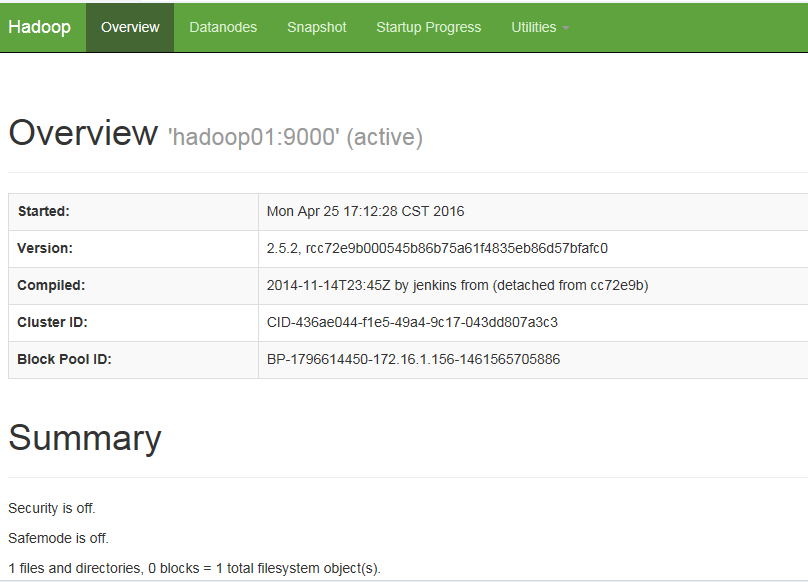
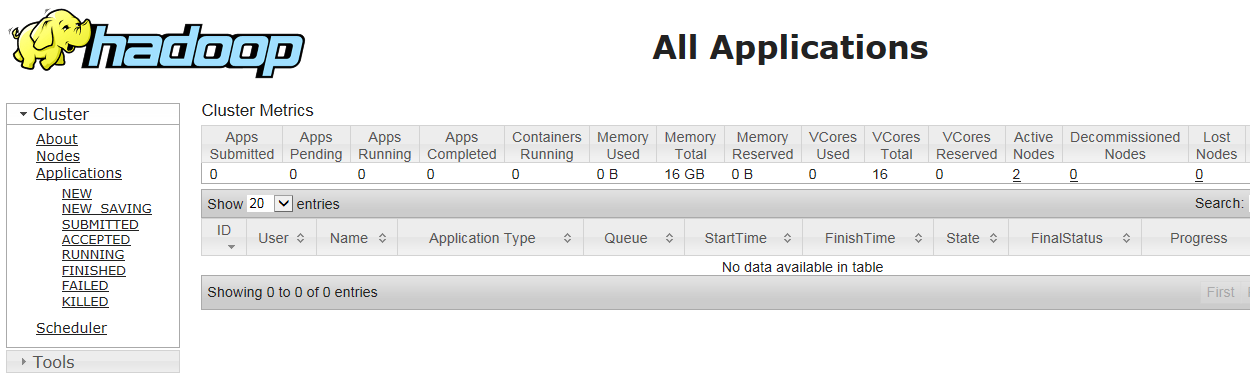

vi wordcount.txt
输入内容为:
hello you
hello me
hello everyone
2)建立目录
hadoop fs -mkdir /data/wordcount
hadoop fs –mkdir /output/
3)上传文件
hadoop fs -put wordcount.txt/data/wordcount/
4)执行wordcount程序
hadoop jar usr/local/program/Hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /data/wordcount /output/wordcount/
5)查看结果
hadoop fs -text /output/wordcount/part-r-00000
标签:blog 硬件 iptables track style cat 命令行 卸载 全分布
原文地址:https://www.cnblogs.com/dtstack/p/9957238.html