标签:状态 ring local 问题: 怎么 mount either mep links
概要本文中我们将讨论如何借助Kafka实现分布式消息管理,使用事件溯源(Event Sourcing)模式实现原子化数据处理,使用CQRS模式(Command-Query Responsibility Segregation )实现查询职责分离,使用消费者群组解决单点故障问题,理解分布式协调框架Zookeeper的运行机制。整个应用的代码实现使用Go语言描述。
第一部分 引子、环境准备、整体设计及实现
第二部分 消息消费者及其集群化
第三部分 测试驱动开发、Docker部署和持续集成
第一部分 引子、环境准备、整体设计及实现
为什么需要微服务
微服务本身并不算什么新概念,它要解决的问题在软件工程历史中早已经有人提出:解耦、扩展性、灵活性,解决“烂架构”膨胀后带来的复杂度问题。
Conway‘s law(康威定律)
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization‘s communication structure.(任何组织在设计一套系统(广义概念上的系统)时,所交付的设计方案在结构上都与该组织的通信结构保持一致)
-- Melvyn Conway, 1967
基于Kafka构建事件溯源模式的微服务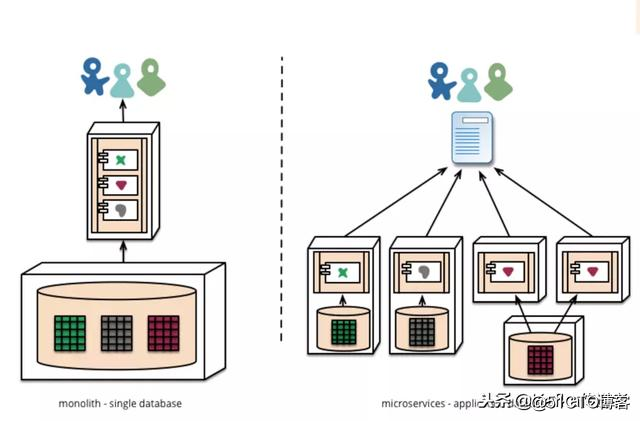
为了赶进度加程序员就像用水去灭油锅里的火一样,原因在于:沟通成本 = n(n-1)/2,沟通成本随着项目或者组织的人员增加呈指数级增长。很多项目在经过一段时间的发展之后,都会有不少恐龙级代码,无人敢挑战。比如一个类的规模就多达数千行,核心方法近千行,大量重复代码,每次调整都以失败告终。庞大的系统规模导致团队新成员接手困难,项目组人员增加导致的代码冲突问题,系统复杂度的增加导致的不确定上线风险、引入新技术困难等。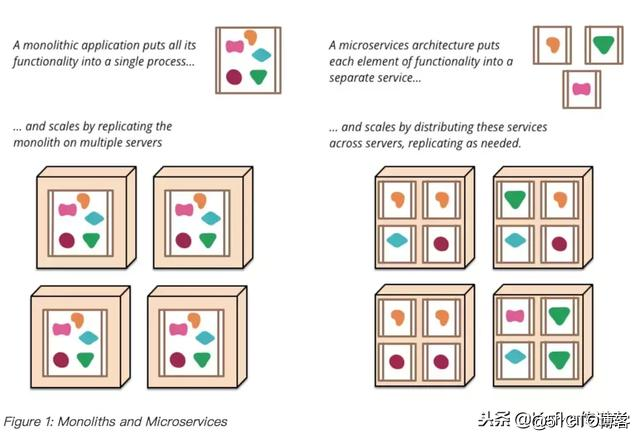
微服务 (Microservices)是解决这些困难的众多方案之一。它本质上是一种软件架构风格,它是以专注于单一责任与功能的小型功能区块 (Small Building Blocks) 为基础,利用模组化的方式组合出复杂的大型应用程序,各功能区块使用与语言无关 (Language-Independent/Language agnostic) 的 API 集相互通讯。
Event Sourcing(事件溯源)
真正构建一个微服务是非常具有挑战性的。其中一个最重要的挑战就是原子化————如何处理分布式数据,如何设计服务的粒度。例如,常见的客户、工单场景,如果拆分成两个服务,查询都变成了一个难题:
select * from order o, customer c
where o.customer_id = c.id
and o.gross_amount > 50000
and o.status = ‘PAID‘
and c.country = ‘INDONESIA‘;在DDD领域(Domain-Driven Design,领域驱动设计)有一种架构风格被广泛应用,即CQRS (Command Query Responsibility Seperation,命令查询职责分离)。CQRS最核心的概念是Command、Event,“将数据(Data)看做是事实(Fact)。每个事实都是过去的痕迹,虽然这种过去可以遗忘,但却无法改变。” 这一思想直接发展了Event Source,即将这些事件的发生过程记录下来,使得我们可以追溯业务流程。CQRS对设计者的影响,是将领域逻辑,尤其是业务流程,皆看做是一种领域对象状态迁移的过程。这一点与REST将HTTP应用协议看做是应用状态迁移的引擎,有着异曲同工之妙。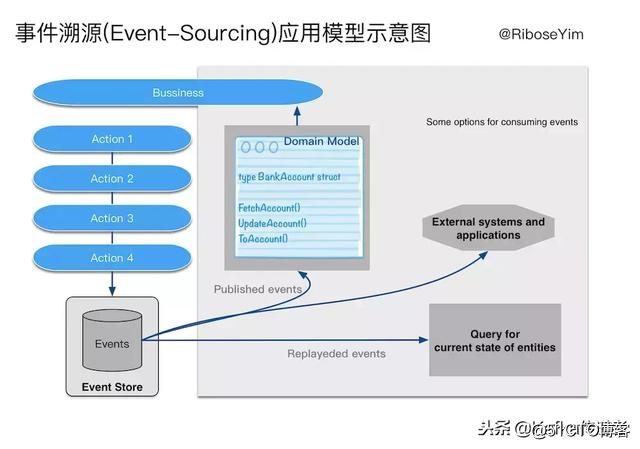
实现方案
Kafka in a Nutshell
Apache Kafka是由Apache软件基金会开发的一个开源消息中间件项目,由Scala写成。Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。Kafka使用Zookeeper作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。同时借助Zookeeper,kafka能够生产者、消费者和broker在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
Kafka Core Words
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。Topic相当于数据库中的Table,行数据以log的形式存储,非常类似Git中commit log。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。
Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition.
Producer:消息生产者,负责发布消息到Kafka broker
Consumer:消息消费者,向Kafka broker读取消息的客户端。
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定则属于默认的group)。
整体设计
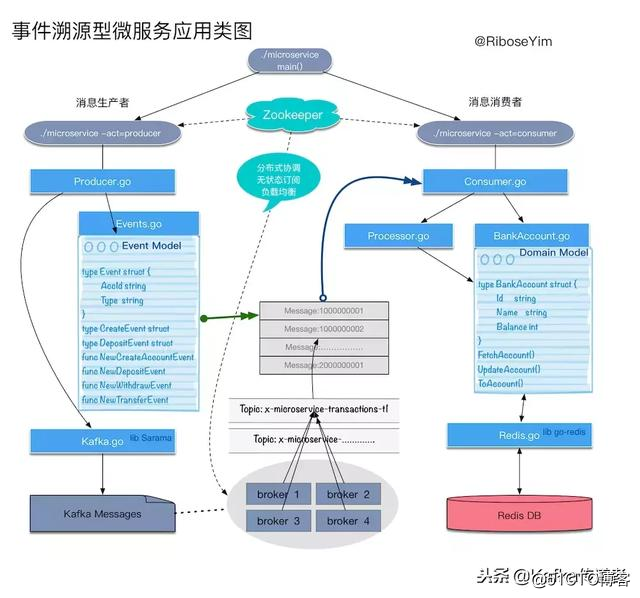
案例:假设一个银行账户系统。经过一段时间的经营发展,该行客户数量和交易规模都有了巨大的增长,系统内部变得异常复杂,每一个部分都变得沉重不堪。我们尝试对他的业务单元进行解耦,例如将余额计算逻辑从原有的核心系统拆分出来。根据银行账户业务特点,我们设计一个生产者——负责根据业务事件触发生成一个事件,所有事件基于Kafka存储,再设计一个消费者——负责从Kafka抓去未处理事件,通过调用业务逻辑处理单元完成后续持久化操作。这样一个账户的所有业务操作都可以有完整的快照历史,符合金融业务Audit(审计)的需要。而且通过使用事件,我们可以很方便地重建数据。
业务事件列表:
CreateEvent:开户
DepositEvent:存款
WithdrawEvent:取款
TransferEvent:转账
领域模型:账户(Account)
holder‘s name:持有人名称
balance:余额
registration date:开户日期
......
领域模型:事件(Event)
name:事件名称
ID:序号
......
环境准备
第一步,启动ZooKeeper:
$ wget http://mirror.bit.edu.cn/apache/kafka/0.10.1.0/kafka_2.10-0.10.1.0.tgz
$ tar -xvf kafka_2.10-0.10.1.0.tgz
$ cd kafka_2.10-0.10.1.0
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ netstat -an | grep 2181
tcp46 0 0 *.2181 *.* LISTEN 第二步,启动Kafka
$ bin/kafka-server-start.sh config/server.properties
[2017-06-13 14:03:08,168] INFO New leader is 0 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
[2017-06-13 14:03:08,172] INFO Kafka version : 0.10.1.0 (org.apache.kafka.common.utils.AppInfoParser)
[2017-06-13 14:03:08,172] INFO Kafka commitId : 3402a74efb23d1d4 (org.apache.kafka.common.utils.AppInfoParser)
[2017-06-13 14:03:08,173] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
$ lsof -nP -iTCP -sTCP:LISTEN | sort -n
$ netstat -an | grep 9092
tcp46 0 0 *.9092 *.* LISTEN第三步,创建topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic x-microservice-transactions-t1
Created topic "x-microservice-transactions-t1".另外,运行多个Kafka 实例
Kafka多实例非常简单,只需要复制文件 server.properties,稍作修改即可。
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
// 启动多个broker,须指定不同的属性文件
$ bin/kafka-server-start.sh config/server-1.properties
$ bin/kafka-server-start.sh config/server-2.propertiesdomain model
package main
// domain model: bank_account.go
type BankAccount struct {
Id string
Name string
Balance int
}
//定义下列函数:
//1. FetchAccount(id) 从Redis读取账户实例信息
//2. updateAccount(id, data) 更新指定账户信息
//3. ToAccount(map) 将从Redis读到的账户信息转换为模型数据,return *BankAccount object.Kafka & Redis library
// main.go
import (
"github.com/go-redis/redis" // Redis通讯库:go-redis
)
var (
Redis = initRedis()
)
func initRedis() *redis.Client {
redisUrl := os.Getenv("REDIS_URL")
if redisUrl == "" {
redisUrl = "127.0.0.1:6379"
}
return redis.NewClient(&redis.Options{
Addr: redisUrl,
Password: "",
DB: 0,
})
}
package main
//kafka.go
import (
"encoding/json"
"fmt"
"github.com/Shopify/sarama" //Kafka通讯库:Sarama
"os"
)
var (
brokers = []string{"127.0.0.1:9092"}
topic = "go-microservice-transactions"
topics = []string{topic}
)
func newKafkaConfiguration() *sarama.Config {
conf := sarama.NewConfig()
conf.Producer.RequiredAcks = sarama.WaitForAll
conf.Producer.Return.Successes = true
conf.ChannelBufferSize = 1
conf.Version = sarama.V0_10_1_0
return conf
}
func newKafkaSyncProducer() sarama.SyncProducer {
kafka, err := sarama.NewSyncProducer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
return kafka
}
func newKafkaConsumer() sarama.Consumer {
consumer, err := sarama.NewConsumer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
return consumer
}消息生产者Producer
package main
//消息生产者 producer.go
import (
"bufio"
"fmt"
"os"
"strconv"
"strings"
)
func mainProducer() {
var err error
reader := bufio.NewReader(os.Stdin)
kafka := newKafkaSyncProducer()
for {
fmt.Print("-> ")
text, _ := reader.ReadString(‘
‘)
text = strings.Replace(text, "
", "", -1)
args := strings.Split(text, "###")
cmd := args[0]
switch cmd {
case "create":
if len(args) == 2 {
accName := args[1]
event := NewCreateAccountEvent(accName)
sendMsg(kafka, event)
} else {
fmt.Println("Only specify create###Account Name")
}
default:
fmt.Printf("Unknown command %s, only: create, deposit, withdraw, transfer
", cmd)
}
if err != nil {
fmt.Printf("Error: %s
", err)
err = nil
}
}
}
// kafka.go
// 增加发送消息的方法
func sendMsg(kafka sarama.SyncProducer, event interface{}) error {
json, err := json.Marshal(event)
if err != nil {
return err
}
msgLog := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(string(json)),
}
partition, offset, err := kafka.SendMessage(msgLog)
if err != nil {
fmt.Printf("Kafka error: %s
", err)
}
fmt.Printf("Message: %+v
", event)
fmt.Printf("Message is stored in partition %d, offset %d
",
partition, offset)
return nil
}
package main
//启动入口,main.go
func main() {
mainProducer()
}
$ go build
$ ./go-microservice
-> create
Only specify create###Account Name
-> create###Yanrui
Message: {Event:{AccId:49a23d27-4ffe-4c86-ab9a-fbc308ecff1c Type:CreateEvent} AccName:Yanrui}
Message is stored in partition 0, offset 0
->第二部分 消息消费者Consumer及其集群化
Consumer负责从Kafka加载消息队列。另外,我们需要为每一个事件创建process()函数。
package main
//processor.go
import (
"errors"
)
func (e CreateEvent) Process() (*BankAccount, error) {
return updateAccount(e.AccId, map[string]interface{}{
"Id": e.AccId,
"Name": e.AccName,
"Balance": "0",
})
}
func (e InvalidEvent) Process() error {
return nil
}
func (e AcceptEvent) Process() error {
return nil
}
// other Process() codes ...
package main
//consumer.go
func mainConsumer(partition int32) {
kafka := newKafkaConsumer()
defer kafka.Close()
//注:开发环境中我们使用sarama.OffsetOldest,Kafka将从创建以来第一条消息开始发送。
//在生产环境中切换为sarama.OffsetNewest,只会将最新生成的消息发送给我们。
consumer, err := kafka.ConsumePartition(topic, partition, sarama.OffsetOldest)
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
go consumeEvents(consumer)
fmt.Println("Press [enter] to exit consumer
")
bufio.NewReader(os.Stdin).ReadString(‘
‘)
fmt.Println("Terminating...")
}Go语言通过goroutine提供了对于并发编程的直接支持,goroutine是Go语言运行库的功能,作为一个函数入口,在堆上为其分配的一个堆栈。所以它非常廉价,我们可以很轻松的创建上万个goroutine,但它们并不是被操作系统所调度执行。除了被系统调用阻塞的线程外,Go运行库最多会启动$GOMAXPROCS个线程来运行goroutine。
goroutines: A goroutine is a lightweight thread of execution.
channels: Channels are the pipes that connect concurrent goroutines. (<- operator)
for: for is Go’s only looping construct. Here are three basic types of for loops.
select: Go’s select lets you wait on multiple channel operations.
Non-Blocking Channel Operations
func consumeEvents(consumer sarama.PartitionConsumer) {
var msgVal []byte
var log interface{}
var logMap map[string]interface{}
var bankAccount *BankAccount
var err error
for {
//goruntine exec
select {
// blocking <- channel operator
case err := <-consumer.Errors():
fmt.Printf("Kafka error: %s
", err)
case msg := <-consumer.Messages():
msgVal = msg.Value
//
if err = json.Unmarshal(msgVal, &log); err != nil {
fmt.Printf("Failed parsing: %s", err)
} else {
logMap = log.(map[string]interface{})
logType := logMap["Type"]
fmt.Printf("Processing %s:
%s
", logMap["Type"], string(msgVal))
switch logType {
case "CreateEvent":
event := new(CreateEvent)
if err = json.Unmarshal(msgVal, &event); err == nil {
bankAccount, err = event.Process()
}
default:
fmt.Println("Unknown command: ", logType)
}
if err != nil {
fmt.Printf("Error processing: %s
", err)
} else {
fmt.Printf("%+v
", *bankAccount)
}
}
}
}
} 重构main
package main
//main.go
//支持producer和consumer启动模式
import (
"flag"
...
)
func main() {
act := flag.String("act", "producer", "Either: producer or consumer")
partition := flag.String("partition", "0",
"Partition which the consumer program will be subscribing")
flag.Parse()
fmt.Printf("Welcome to go-microservice : %s
", *act)
switch *act {
case "producer":
mainProducer()
case "consumer":
if part32int, err := strconv.ParseInt(*partition, 10, 32); err == nil {
mainConsumer(int32(part32int))
}
}
}通过--act参数,可以启动一个消费者进程。当进程运行时,他将从Kafka一个一个拿出消息进行处理,按照我们之前在每个事件定义的Process() 方法。
$ go build
$ ./go-microservice --act=consumer
Welcome to go-microservice : consumer
Press [enter] to exit consumer
Processing CreateEvent:
{"AccId":"49a23d27-4ffe-4c86-ab9a-fbc308ecff1c","Type":"CreateEvent","AccName":"Yanrui"}
{Id:49a23d27-4ffe-4c86-ab9a-fbc308ecff1c Name:Yanrui Balance:0}
Terminating...集群化消息消费者
问题:如果一个Consumer宕机了怎么办?(例如:程序崩溃、网络异常等原因)
解决方案:将多个Consumer编组为集群实现高可用。具体来说就是打标签,当有一个新的Log发送时,Kafka将其发送给其中一个实例。当该实例无法接收Log时,Kafka将Log传递给另一个包含相同标签的Consumer。
注意:Kafka 版本 0.9 +,另外还需要使用sarama-cluster库
#使用govendor获取
govendor fetch github.com/bsm/sarama-cluster
//修改mainConsumer方法使用sarama-cluster library连接Kafka
config := cluster.NewConfig()
config.Consumer.Offsets.Initial = sarama.OffsetNewest
consumer, err := cluster.NewConsumer(brokers, "go-microservice-consumer", topics, config)
//topics定义
var (
topics = []string{topic}
)
//调整consumeEvents()
case err, more := <-consumer.Errors():
if more {
fmt.Printf("Kafka error: %s
", err)
}
//consumer.Messages() : MarkOffset
//consumer.go
//func mainConsumer(partition int32)
consumer.MarkOffset(msg, "") //增加的行
msgVal = msg.Value即使程序崩溃,MarkOffset也会将消息标记为 processed ,标签包括元数据以及这个时间点的状态。元数据可以被另外一个Consumer恢复数据状态,也就能被重新消费。即即使同样的消息被处理两次,结果也是一样的,这个过程理论上是 幂等 的(idempotent)。
Kafka Consumers
//运行多个consumer实例
$ ./go-microservice --act=consumer
$ ./go-microservice --act=consumer
$ ./go-microservice --act=consumer第三部分:测试驱动开发、Docker部署和持续集成
使用vendor管理Golang项目依赖
用govendor fetch <url1> <url2>新增的第三方包直接被get到根目录的vendor文件夹下,不会与其它的项目混用第三方包,完美避免多个项目同用同一个第三方包的不同版本问题。只需要对vendor/vendor.json进行版本控制,即可对第三包依赖关系进行控制。
$ //
$ go get -u github.com/kardianos/govendor
$ cd $PROJECT_PATH
$ govendor init
$ govendor add +external
$单元测试:ginkgo Test Suite
ginkgo
gomega
$ go get github.com/onsi/ginkgo/ginkgo
$ go get github.com/onsi/gomega
$ ginkgo bootstrap
Generating ginkgo test suite bootstrap for main in:
go_microservice_suite_test.go
package main_test
//go_microservice_suite_test.go,单元测试类
import (
"github.com/onsi/ginkgo"
"github.com/onsi/gomega"
)
var _ = Describe("Event", func() {
Describe("NewCreateAccountEvent", func() {
It("can create a create account event", func() {
name := "John Smith"
event := NewCreateAccountEvent(name)
Expect(event.AccName).To(Equal(name))
Expect(event.AccId).NotTo(BeNil())
Expect(event.Type).To(Equal("CreateEvent"))
})
})
})
$ ginkgo
Running Suite: go-microservice Suite
==========================
Random Seed: 1490709758
Will run 1 of 1 specs
Ran 1 of 1 Specs in 0.000 seconds
SUCCESS! -- 1 Passed | 0 Failed | 0 Pending | 0 Skipped PASS
Ginkgo ran 1 suite in 905.68195ms
Test Suite Passed单元测试的四个阶段
Setup 启动
Execution 执行
Verification 验证
Teardown 拆卸
Docker部署
Docker 容器中需要包含下列组件:
Golang
Redis、Kafka
微服务依赖的其它组件
在根目录创建一个Dockerfile
FROM golang:1.8.0
MAINTAINER Yanrui
//install our dependencies
RUN go get -u github.com/kardianos/govendor
RUN go get github.com/onsi/ginkgo/ginkgo
RUN go get github.com/onsi/gomega
//将整个目录拷贝到容器
ADD . /go/src/go-microservice
//检查工作目录
WORKDIR /go/src/go-microservice
//安装依赖项
RUN govendor sync
//测试
$ docker build -t go-microservice .
$ docker run -i -t go-microservice /bin/bash
$ ginkgo
.......................
.......Failed..........由于容器本地并没有一个Redis实例运行在上面,这时运行ginkgo测试就会报错。我们为什么不在这个Dockerfile中包含一个Redis呢?这就违背了Docker分层解耦的初衷,我们可以通过docker-compose将两个服务连接起来一起工作。
创建一个docker-compose.yml文件(与Dockerfile目录一致):
version: "2.0"
services:
app:
environment:
REDIS_URL: redis:6379
build: .
working_dir: /go/src/go-microservice
links:
- redis
redis:
image: redis:alpine本地构建完成之后,再次运行 docker-compose run app ginkgo 测试通过。
Infrastructure as Code(基础设施即代码)
The enabling idea of infrastructure as code is that the systems and devices which are used to run software can be treated as if they, themselves, are software. — Kief Morris
云带来的好的一方面是它让公司中的任何人都可以轻松部署、配置和管理他们需要的基础设施。虽然很多基础设施团队采用了云和自动化技术,却没有采用相应的自动化测试和发布流程。它们把这些当作一门过于复杂的脚本语言来使用。他们会为每一次具体的改动编写手册、配置文件和执行脚本,再针对一部分指定的服务器手工运行它们,也就是说每一次改动都还需要花费专业知识、时间和精力。这种工作方式意味着基础设施团队没有把他们自己从日常的重复性劳动中解放出来。目前已经有很多商业云平台提供了Docker服务,只需要将自己的 git repository 链接到平台,即可以自动帮你完成部署,在云上完成集成测试。
docker-compose build
docker-compose run app ginkgo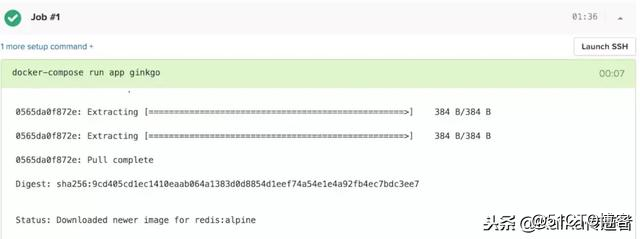
标签:状态 ring local 问题: 怎么 mount either mep links
原文地址:http://blog.51cto.com/13981400/2316977