标签:tle == 等级 指针数组 core 其他 分享 建立 性能
排行榜有很多种设计方案:
比如数组,排序树,Redis的sort set等,还有这里说的跳表。
先科普一下跳表以及分析一下跳表优劣:
跳表:在普通链表中,给一些节点增加额外的指针,使得这些节点能够一次跨越更多的中间节点,提高了效率。
优点:相比普通链表,由于跳跃的特性,可以节省便利次数,时间复杂度上是O(logN)。相比平衡二叉树,在插入和删除操作上,不需要再进行树的平衡等操作。
缺点:有额外指针的空间消耗,在数据量超大的情况下,性能还是会下降。
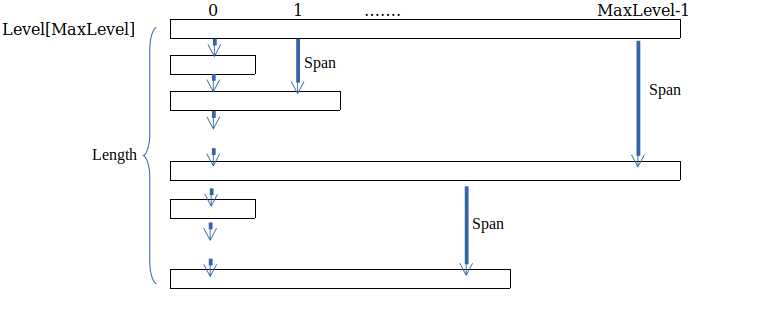
跳表结构如下:
每个框框表示一个Node,里面存了一个指针数组,位数越大,跨度越大
先说一下查找:
由于位数越大,跨度越大,所以我们从位数高到位数低遍历,对每一位:While循环对比指针指向的Node里的Score是否小于插入成绩,是则指针跳到该Node,否则跳出循环。
uint32 GetRank(int64 InsertCode, uint64 InsertScore) { if(!insertCode) return; skiplistNode* pNode = header; uint32 rank = 0; for(int i = CurLevel - 1; i >= 0; i--) { skiplistNode* pNexNode = pNode->level[i].forward; while(pNexNode && pNexNode->Value<=InsertValue) { rank +=pNode->level[i].span; pNode = pNode->level[i].forward; } if(pNode->Code == InsertCode) return rank; } return 0; }
能够看懂查找的话,插入和删除也就差不多了,理一下插入流程:
1,整体流程是:找到插入位置,记录指针数组,随机一个插入Node的Level,然后插入(与一般的链表插入差不多)
2,建立指针数组和排名数组,比如:skiplistNode* update[MaxLevel]; uint32 rank[MaxLevel];
3,查找。这儿查找需要记录最接近插入位置的每一个跨度的指针,保存到update里
4,随机一下插入Node的Level,通常建议:level = 1; while(1/4概率) ++level; 这样跨度等级不会爆炸
5,如果InsertLevel超过了当前排行榜的Level,就把update数组中超出部分的指针指向header,且每位保存的步长都设置为排行榜的长度Length
6,接着就是常规链表的插入了,这儿相当于同时插入了InsertLevel个链表,根据update数组中的指针,和指针指向的下一个Node,中间插入
7,插入之后,遍历update数组,将里面的InsertLevel位到排行榜CurLevel位的步长加1
8,因为这种设计的排行榜最后面的是最大值,我们在每个Node里存一个后向指针,组成双向链表,方便遍历,所以再简单处理一下Node里的backward指针就可以了
删除的操作和插入差不多,从这一系列的步骤来看,对比平衡树在插入和删除之后,还要调整位置,跳表就不需要这么麻烦了,所以这是一个很好的可以用来设计排行榜的方式。
对了,如果需要在排行榜上保存玩家数据怎么弄?保存在Node里?
不建议直接存Node里,不然其他地方需要数据的时候还需要查找一次,建议Node里存一个唯一标志的Code和成绩就可以了,玩家详细信息用一个HashMap保存在其他地方(如果有多个排行榜的话,还可以共用数据)
标签:tle == 等级 指针数组 core 其他 分享 建立 性能
原文地址:https://www.cnblogs.com/YoungBig/p/9959107.html