标签:缘分 http 添加 src 字典 目标 ecif 提取 begin
寻找领域不变特征一般分为三类:
为了实现两个领域的迁移需要减小其分布差异:
从稀疏编码谈起:
\[ \underset{D,Z}{min} \quad \lVert {X-DZ}\rVert_{F}^{2} + \mathcal{N}(Z) \ s.t. \,\, \lVert{{d}_{i}^j}\rVert_{2}^2 \le 1 \quad \forall i,j \]
减小边缘分布差异:
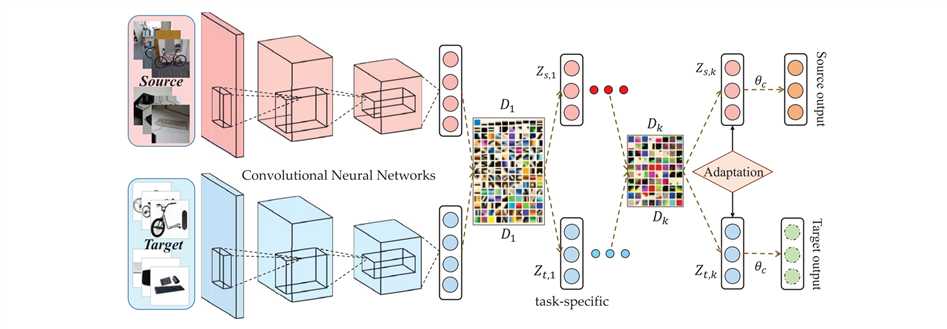
由于光照,角度等问题。直接通过字典学习得到新特征太浅显。\(\Rightarrow\)使用CNN提取抽象特征(参数共享)。
\[ \left. \begin{aligned} Z_{k-1} = D_{k}Z_{k} \Rightarrow \text{rank}(Z_{k-1}) = \text{rank}(D_{k}Z_{k}) \ \text{rank}(D_{k}Z_{k}) \le min(\text{rank}(Z_{k}),\text{rank}(D_{k})) \end{aligned} \right\} \Rightarrow \text{rank}(Z_{k-1}) \le \text{rank}(Z_{k}) \ \Downarrow \\ \text{rank}(Z_{1}) \le \text{rank}(Z_{2}) \le \cdots \text{rank}(Z_{k}) \]
改进结果:
\[ \underset{D_{1}\dots,D_{2},Z_{k}}{min} \quad \lVert{X-D_{1}D_{2}\dots D_{k}Z_{k}}\rVert_{F}^{2} + \text{rank}(Z_{k}) \ s.t. \,\, \lVert{{d}_{i}^j}\rVert_{2}^2 \le 1 \quad \forall i,j \]
减小条件分布差异:
半监督知识适应(\(Z_{k}=[Z_{k}^s,Z_{k}^t]\)):
\[ \mathcal{M}(Z_{k}) = \Vert {\frac{1}{m_{s}} \sum_{i=1}^{m_{s}} {z_{k,i}} - \frac{1}{m_{t}} \sum_{j=m_{s}+1}^{m}{z_{k,j}} } \Vert_{2}^2 = \sum_{i=1}^m \sum_{j=1}^m {z_{k,i}^\top z_{k,j}W_{ij}=\text{tr}(Z_{k}WZ_{k}^\top)} \]
改进:
传统的MMD只能减小边缘分布差异\(\Rightarrow\)采用类间MMD,可减小条件分布差异。
但目标域几乎无标签可用\(\Rightarrow\)对目标域样本添加"soft label"。
\[ \mathcal{C}(Z_{k}) = \sum_{c=1}^C \Vert {\frac{1}{m_{s}^c} \sum_{i=1}^{m_{s}^c} {z_{k,i}^{s}} - \frac{1}{m_{t}^c} \sum_{j=1}^{m_{t}}{p_{c,j}z_{k,j}^{t}} } \Vert_{2}^2 = \sum_{c=1}^C \text{tr}(Z_{k}W^{(c)}Z_{k}^\top) \]
"end-to-end":
\[ \mathcal{J}(Z_{K},\Theta,Y) = -\frac{1}{m}\sum _{i=1}^m \sum_{c=1}^C y_{c,i}\text{log}\frac{e^{\theta_{c}^\top}z_{k,i}}{\sum_{u=1}^C e^{\theta_{u}^\top}z_{k,i}} \]
非线性化:
\[ Z_{i} \approx f(D_{i+1}Z_{i+1}) \]
最终目标函数:
\[ \mathcal{L} = \mathcal{L}(Z_{k},\Theta,Y) + \lambda\Vert{X-D_{1}f(D_{2}f(\cdots f(D_{k}Z_{k}) ))}\Vert_{F}^2 +\alpha\sum_{c=0}^C\text{tr}(Z_{k}W^{(c)}Z_{k}^{\top})+\beta\Vert{Z_{k}-AB}\Vert_{F}^2 \]
标签:缘分 http 添加 src 字典 目标 ecif 提取 begin
原文地址:https://www.cnblogs.com/YvanZh/p/9960280.html