标签:amp range .sh pytho 图片 play github read print
手动实现mini深度学习框架,主要精力不放在运算优化上,仅体会原理。
地址见:miniDeepFrame
『TensorFlow』卷积层、池化层详解
『科学计算』全连接层、均方误差、激活函数实现
Layer.py 层 class,已实现:全连接层,卷积层,平均池化层
Loss.py 损失函数 class,已实现:均方误差损失函数
Activate.py 激活函数 class,已实现:sigmoid、tanh、relu
test.py 训练测试代码
主流框架对于卷积相关层的实现都是基于矩阵乘法运算,而非这里的多层for循环,这里仅仅是最直观的演示原理,并非最优实现。
我们此时不对层函数进行封装,仅仅实现了最简单的前向传播、反向传播、参数获取几个功能,利用这些功能,我们已经可以实现一个最简单的神经网络,
声明并初始化各层class的实例,这会使得各个实例初始化可学习参数
(【注】一般的框架会在运行时,即第一次前向传播时才初始化参数,本demo由于是动态的,所以没必要这样写)
进入循环体:
获取数据,向前传播,计算损失函数&损失函数的梯度
向后传播,获取各个参数的梯度
对参数循环,利用参数梯度更新参数
在test.py中,我们使用tensorflow的接口,下载并读取mnist数据集,然后训练一个10分类的分类器,观察收敛过程。
mnist = input_data.read_data_sets(‘../../Mnist_data/‘, one_hot=True)
X_train,y_train = mnist.train.next_batch(BARCH_SIZE)
X_train = np.reshape(X_train, [4, 1, 28, 28])
conv1 = Layer.Conv2D([8, 1, 2, 2])
pool1 = Layer.MeanPooling([2, 2])
relu1 = Activate.Relu()
conv2 = Layer.Conv2D([16, 8, 2, 2])
pool2 = Layer.MeanPooling([2, 2])
relu2 = Activate.Relu()
conv3 = Layer.Conv2D([8, 16, 2, 2])
pool3 = Layer.MeanPooling([2, 2])
relu3= Activate.Relu()
dense1 = Layer.Dense(128, 10)
sigmoid = Activate.Sigmoid()
loss = Loss.MSECostLayer()
loss_line = []
for i in range(1000):
# 正向传播
x = conv1.forward(X_train, 1)
x = pool1.forward(x, 2)
x = relu1.forward(x)
x = conv2.forward(x, 1)
x = pool2.forward(x, 2)
x = relu2.forward(x)
x = conv3.forward(x, 1)
x = pool3.forward(x, 2)
x = relu3.forward(x)
shape = x.shape
x = x.reshape([x.shape[0], -1])
x = dense1.forward(x)
l_val = loss.loss(x, y_train)
print("损失函数值为:", l_val)
loss_line.append(l_val)
# 反向传播
l = loss.loss_grad(x, y_train)
l = dense1.backward(l)
l = l.reshape(shape)
l = relu3.backward(l)
l = pool3.backward(l)
l = conv3.backward(l)
l = relu2.backward(l)
l = pool2.backward(l)
l = conv2.backward(l)
l = relu1.backward(l)
l = pool1.backward(l)
l = conv1.backward(l)
for layer in [conv1, conv2, conv3, dense1]:
for param, param_grad in zip(layer.params(), layer.params_grad()):
param -= LEARNING_RATE * param_grad
实际运行test.py,会输出loss函数结果,并绘制成图,左图展示了整个loss函数收敛过程,
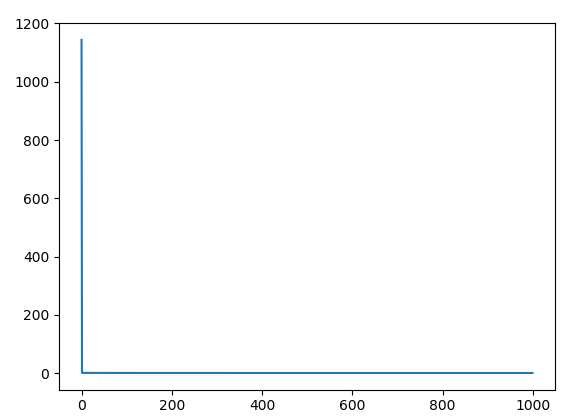
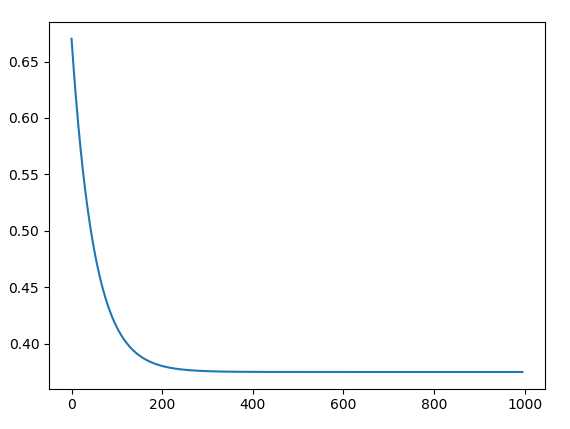
下图则截掉了前四次迭代输出的Loss,因为初始四次损失函数过大,收敛速度极快,影响后面的结果展示:
标签:amp range .sh pytho 图片 play github read print
原文地址:https://www.cnblogs.com/hellcat/p/9963383.html