标签:分片 客户 离散 增加 节点 技术 mon style 分析
(1).父表按照主键ID分片,子表的分片字段与主表ID关联,配置为ER分片
(2).父表的分片字段为其他字段,子表的分片字段与主表ID关联,配置为ER分片
答:(1)第一种分片:父表按照主键ID分片
表设计:父表student,子表selectcourse
student(id,stu_id);
selectcourse(id,stu_id,cou_id);
在schema.xml中增加父表、子表定义:
<table name="student" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long">
<childTable name="selectcourse" primaryKey="ID" joinKey="stu_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table student(id bigint not null primary key,stu_id bigint not null);
create table selectcourse(id bigint not null primary key,stu_id bigint not null,cou_id bigint not null);
插入父表记录
insert into student(id,stu_id) values(1,3001);//
insert into student(id,stu_id) values(2,3002);
插入子表记录
insert into selectcourse(id,stu_id,cou_id) values(1,1,1); //同时观察日志
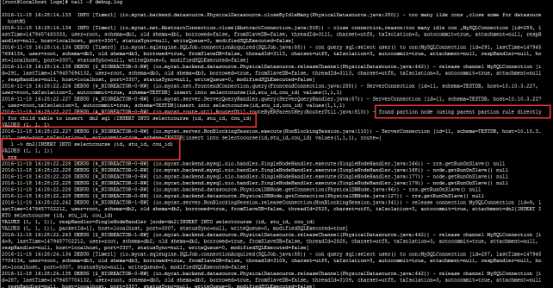
总结:直接使用父表的分片规则(id字段mod算法)来查找节点。
表设计:父表book,子表sail
book(id,book_id);
sail(id,book_id,custo_id);
在rule.xml中增加“mod-long-book”分片方法:分片字段为book_id
<tableRule name="mod-long-book">
<rule>
<columns>book_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
在schema.xml中增加父表、子表定义:父表用"mod-long-book"方法分片,
<table name="book" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long-book">
<childTable name="sail" primaryKey="ID" joinKey="book_id" parentKey="id" />
</table>
在mysql客户端中执行创建表的语句:
create table book(id bigint not null primary key,book_id bigint not null);
create table sail(id bigint not null primary key,book_id bigint not null,customer_id bigint not null);
插入父表记录:
insert into book(id,book_id) values(1,3001);
insert into book(id,book_id) values(2,3002);
插入子表记录
insert into sail(id,book_id,customer_id) values(1,2,2001);//同时观察日志
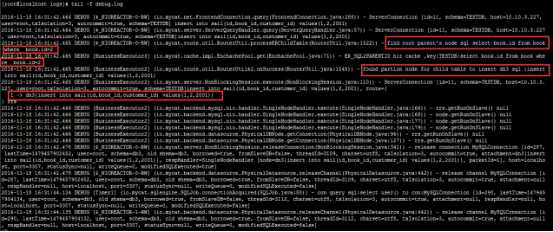
总结:先通过父表的id字段查询分片,再往相应的分片中插入数据。
比第一种方法多了一个“查找分片”的步骤。
(1)自定义数字范围分片:分片方法为“rang-long”
首先,在rule.xml中配置分片方法“price-rang-long”,算法为“rang-long”;
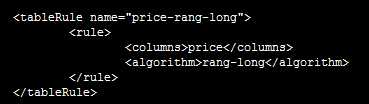
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(mygoods);

最后,往mygoods表中插入记录;

日志信息:

路由描述:
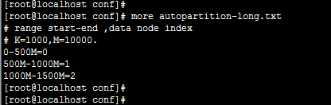
mygoods表依据rang-long算法进行分割,rang-long又依据autopartition-long.txt(如下图所示)文件中的值进行分片(制定数据节点dh),本题中的price为300,
属于0-500M的范围,所以本记录应该路由到第0个节点上(下标从0开始,第0个节点就是dn1)执行,正如上图中所示。
(2)自然月分片:分片方法为“partbymonth”
首先,在rule.xml中配置分片方法“sharding-by-month”,算法为“partbymonth”;
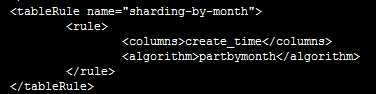
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(myrecords);

最后,往myrecords表中插入记录;

日志信息:

路由描述:
Myrecords表依据partbymonth算法进行分割,partbymonth的以自然月为依据,每个月一个分片,从2015-01-01开始(如下图所示:rule.xml中partbymonth分片方法),
即2015年1月份数据在第0节点,2015年2月份数据在第1节点,以此类推。本题中的create_time=”2015-03-01”对应的数据应该在第2个节点(下标从0开始,第2个节点
就是dn3)执行,所以,本记录路由到第2个节点上(dn3)执行,正如上图中所示。

3 选择离散分片规则的2种,对配置和路由过程做完整的分析
(1)十进制求模分片:分片方法为“mod-long”
首先,在rule.xml中配置分片方法;
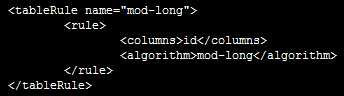
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(student);
create table student(id bigint not null primary key,stu_id bigint not null);
最后,往student表中插入记录;

日志信息:
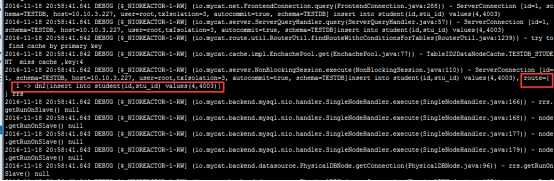
路由描述:
student表依据mod-log算法进行分割,本题中记录值为4除3的模为1,对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。
(2)哈希分片:分片方法为“hash-int”
首先,在rule.xml中配置分片方法;
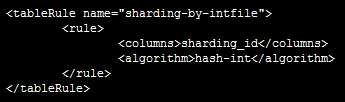
再在schema.xml中配置表信息,包括表名、主键、节点、分片方法等;

然后,在客户端执行创建表的命令(employee);
create table employee (id int not null primary key,name varchar(100),sharding_id int not null);
最后,往myrecords表中插入记录;

日志信息:
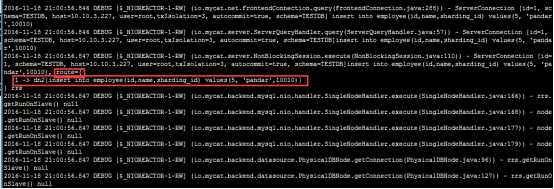
路由描述:
employee 表依据sharding-by-intfile算法进行分割,sharding-by-intfile算法又依据partition-hash-int.txt文件(如下图所示)中的范围进行分片,本题中记录值10010=1,
对应的数据应该在第1个节点(下标从0开始,第1个节点就是dn2)上;所以,本记录路由到第1个节点上(dn2)执行,正如上图中所示。


标签:分片 客户 离散 增加 节点 技术 mon style 分析
原文地址:https://www.cnblogs.com/yhq1314/p/9968267.html