标签:hash .lib 流程 [] 分解 memory leo http val
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
MapReduce架构
先来看一下MapReduce1.0的架构图
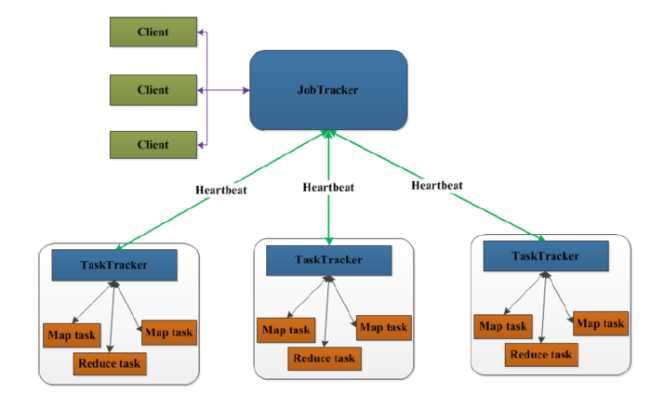
上图中的TaskTracker对应HDFS中的DataNode,
在MapReduce1.x中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
流程分析
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
MapReduce运行流程
以wordcount为例,运行的详细流程图如下
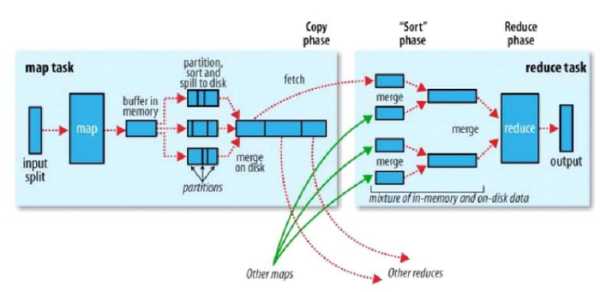
1.split阶段
首先mapreduce会根据要运行的大文件来进行split,每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。输入分片(input split)往往和HDFS的block(块)关系很密切,假如我们设定HDFS的块的大小是64MB,我们运行的大文件是64x10M,mapreduce会分为10个map任务,每个map任务都存在于它所要计算的block(块)的DataNode上。
2.map阶段
map阶段就是程序员编写的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行。本例的map函数如下:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * * KEYIN 即K1 表示行的偏移量 * VALUEIN 即V1 表示行文本内容 * KEYOUT 即K2 表示行中出现的单词 * VALUEOUT 即V2 表示行中出现的单词的次数,固定值1 * */ public class WCMapper extends Mapper<LongWritable,Text,Text,LongWritable> { @Override protected void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException { String str = value.toString(); String[] strs = StringUtils.split(str,‘‘); for(String s:strs) { context.write(new Text(s),new IntWritable(1)); } } }
根据空格切分单词,计数为1,生成key为单词,value为出现1次的map供后续计算。
3.shuffle阶段
shuffle阶段主要负责将map端生成的数据传递给reduce端,因此shuffle分为在map端的过程和在reduce端的执行过程。
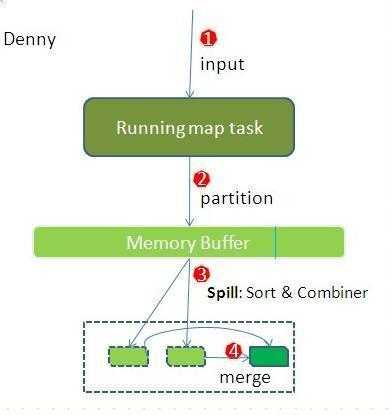
先看map端:
reduce端:
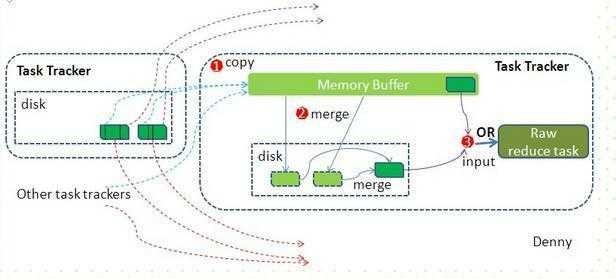
reduce节点从各个map节点拉取存在磁盘上的数据放到Memory Buffer(内存缓冲区),同理将各个map的数据进行合并并存到磁盘,最终磁盘的数据和缓冲区剩下的20%合并传给reduce阶段。
4.reduce阶段
reduce对shuffle阶段传来的数据进行最后的整理合并
/** * KEYIN 即K2 表示行中出现的单词 * VALUEIN 即V2 表示出现的单词的次数 * KEYOUT 即K3 表示行中出现的不同单词 * VALUEOUT 即V3 表示行中出现的不同单词的总次数 */ public class WCReducer extends Reducer<Text,LongWritable,Text,LongWritable> { @Override protected void reduce(Text key,IterableIntWritable values,Context context)throws IOException,InterruptedException { int sum = 0; for(IntWritable i:values) { sum+ = i.get(); } context.write(key,new IntWritable(sum)); } }
编写代码,实现文件中的单词个数统计
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class FinderCountApp { //封装mapreduce作业所有信息 public static void main(String[] args) throws Exception { //创建Configuration Configuration configuration = new Configuration(); //准备/清理环境 Path outputPath = new Path(args[1]); FileSystem fs = FileSystem.get(configuration); if (fs.exists(outputPath)){ fs.delete(outputPath,true); } //创建job,wordcount是job的名称 Job job =Job.getInstance(configuration,"wordcount"); //设置job处理类,就是主类 job.setJarByClass(WCMapper.class); //处理数据,就必须有一个输入路径,第一个参数job的名称,第二个参数是Path FileInputFormat.setInputPaths(job,new Path(args[0]));//设置作业处理的路径 //设置map相关的 job.setMapperClass(MyMapper.class);//设置MyMapper.class job.setOutputKeyClass(Text.class);//设置map输出key的类型,是Text job.setMapOutputValueClass(LongWritable.class);//设置map输出的value的类型 //设置reduce相关的 job.setReducerClass(WCReducer.class);//设置MyReduce.class job.setOutputKeyClass(Text.class);//设置reduce输出key的类型,是Text job.setMapOutputValueClass(LongWritable.class);//设置reduce输出的value的类型 //设置作业处理的输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean result = job.waitForCompletion(true);//把作业提交 System.exit(result ? 0 : 1);//0就是true } }
MapReduce的优缺点
优点:
4.适合PB级别以上的大数据的分布式离线批处理。
缺点:
标签:hash .lib 流程 [] 分解 memory leo http val
原文地址:https://www.cnblogs.com/rinack/p/9968881.html