标签:shanghai 查看 0ms 列表 ade 命名 后台 创建 容器
一、Hadoop 介绍Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
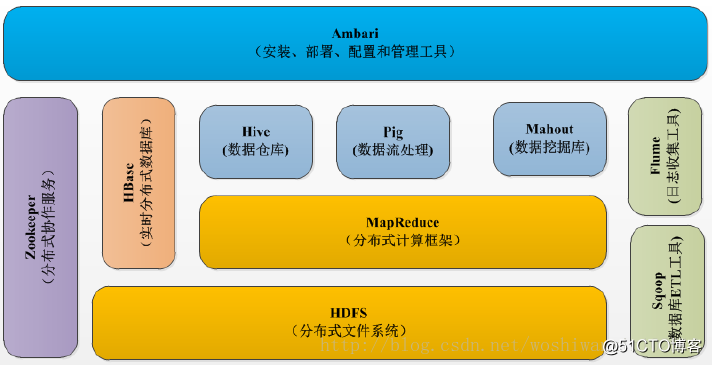
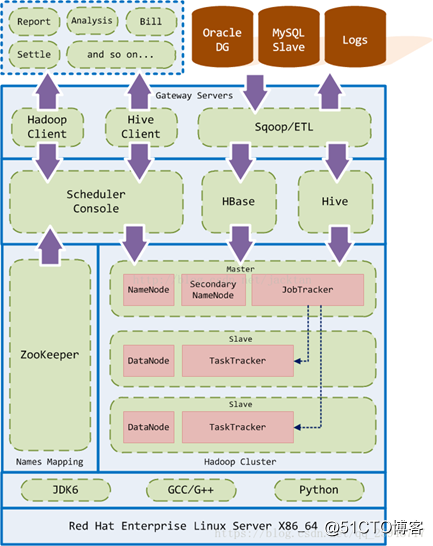
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
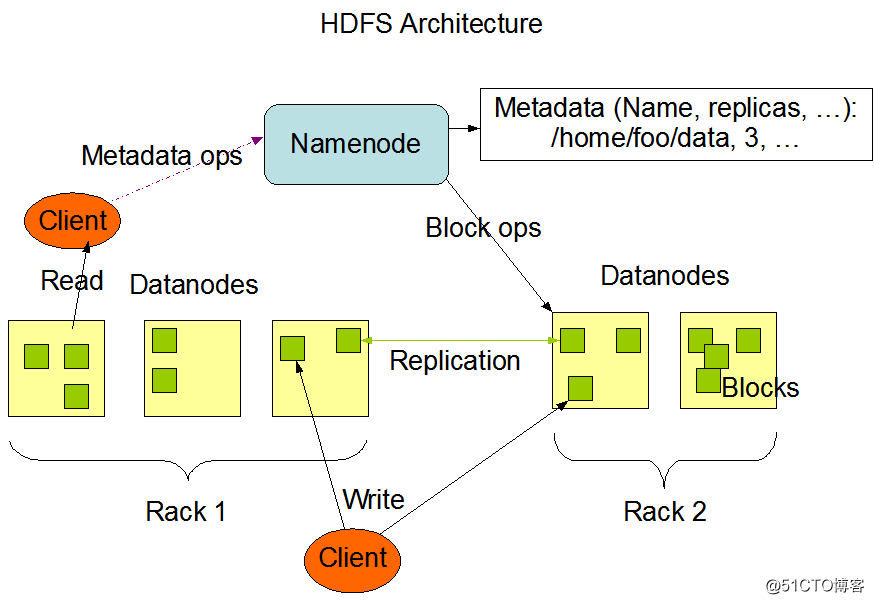
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
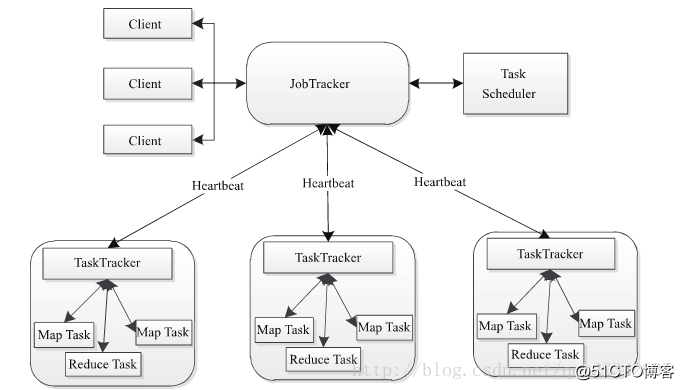
Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Hadoop MapReduce采用Master/Slave(M/S)架构,如下图所示,主要包括以下组件:Client、JobTracker、TaskTracker和Task。
# 下载安装包
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
# 解压安装包
tar xf hadoop-2.7.3.tar.gz && mv hadoop-2.7.3 /usr/local/hadoop
# 创建目录
mkdir -p /home/hadoop/{name,data,log,journal}编辑文件/etc/profile.d/hadoop.sh。
# HADOOP ENV
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin使 Hadoop 环境变量生效。
source /etc/profile.d/hadoop.sh编辑文件/usr/local/hadoop/etc/hadoop/hadoop-env.sh,修改下面字段。
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/usr/local/hadoop编辑文件/usr/local/hadoop/etc/hadoop/yarn-env.sh,修改下面字段。
export JAVA_HOME=/usr/local/java编辑文件/usr/local/hadoop/etc/hadoop/slaves
datanode01
datanode02
datanode03编辑文件/usr/local/hadoop/etc/hadoop/core-site.xml,修改为如下:
<configuration>
<!-- 指定hdfs的nameservice为cluster1 -->
<property>
<name>fs.default.name</name>
<value>hdfs://cluster1:9000</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk01:2181,zk02:2181,zk03:2181</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--设置hadoop的缓冲区大小为128MB-->
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>编辑文件/usr/local/hadoop/etc/hadoop/hdfs-site.xml,修改为如下:
<configuration>
<!--NameNode存储元数据的目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/name</value>
</property>
<!--DataNode存储数据块的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/data</value>
</property>
<!--指定HDFS的副本数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--开启HDFS的WEB管理界面功能-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定HDFS的nameservice为cluster1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
</configuration>编辑文件/usr/local/hadoop/etc/hadoop/mapred-site.xml,修改为如下:
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapred做本地计算所使用的文件夹,可以配置多块硬盘,逗号分隔 -->
<property>
<name>mapred.local.dir</name>
<value>/home/hadoop/data</value>
</property>
<!-- 使用管理员身份,指定作业map的堆大小-->
<property>
<name>mapreduce.admin.map.child.java.opts</name>
<value>-Xmx256m</value>
</property>
<!-- 使用管理员身份,指定作业reduce的堆大小-->
<property>
<name>mapreduce.admin.reduce.child.java.opts</name>
<value>-Xmx4096m</value>
</property>
<!-- 每个TT子进程所使用的虚拟机内存大小 -->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx512m</value>
</property>
<!-- 设置参数防止超时,默认600000ms,即600s-->
<property>
<name>mapred.task.timeout</name>
<value>1200000</value>
<final>true</final>
</property>
<!-- 禁止访问NN的主机名称列表,指定要动态删除的节点-->
<property>
<name>dfs.hosts.exclude</name>
<value>slaves.exclude</value>
</property>
<!-- 禁止连接JT的TT列表,节点摘除是很有作用 -->
<property>
<name>mapred.hosts.exclude</name>
<value>slaves.exclude</value>
</property>
</configuration>编辑文件/usr/local/hadoop/etc/hadoop/yarn-site.xml,修改为如下:
<configuration>
<!--RM的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode01</value>
</property>
<!--RM对客户端暴露的地址,客户端通过该地址向RM提交应用程序、杀死应用程序等-->
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<!--RM对AM暴露的访问地址,AM通过该地址向RM申请资源、释放资源等-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<!--RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<!--RM对NM暴露地址,NM通过该地址向RM汇报心跳、领取任务等-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<!--RM对管理员暴露的访问地址,管理员通过该地址向RM发送管理命令等-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<!--单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,小于最小值则分配最小值-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>983040</value>
</property>
<!--启用的资源调度器主类。目前可用的有FIFO、Capacity Scheduler和Fair Scheduler-->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<!--RM对管理员暴露的访问地址,管理员通过该地址向RM发送管理命令等-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<!--单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,小于最小值则分配最小值-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8182</value>
</property>
<!--启用的资源调度器主类。目前可用的有FIFO、Capacity Scheduler和Fair Scheduler-->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!--启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!--单个容器可申请的最小/最大虚拟CPU个数。比如设置为1和4,则运行MapRedce作业时,每个Task最少可申请1个虚拟CPU,最多可申请4个虚拟CPU-->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>512</value>
</property>
<!--单个可申请的最小/最大内存资源量 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!--启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置在HDFS上聚集的日志最多保存多长时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--NM运行的Container,总的可用虚拟CPU个数,默认值8-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>12</value>
</property>
<!--NM运行的Container,可以分配到的物理内存,一旦设置,运行过程中不可动态修改,默认8192MB-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--每使用1MB物理内存,最多可用的虚拟内存数,默认值2.1-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!--一块磁盘的最高使用率,当一块磁盘的使用率超过该值时,则认为该盘为坏盘,不再使用该盘,默认是100,表示100%-->
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98.0</value>
</property>
<!--NM运行的附属服务,需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--为了能够运行MapReduce程序,需要让各个NodeManager在启动时加载shuffle server-->
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>cd /usr/local/hadoop/etc/hadoop
scp * datanode01:/usr/local/hadoop/etc/hadoop
scp * datanode02:/usr/local/hadoop/etc/hadoop
scp * datanode03:/usr/local/hadoop/etc/hadoop
chown -R hadoop:hadoop /usr/local/hadoop
chmod 755 /usr/local/hadoop/etc/hadoophdfs namenode -format
hadoop-daemon.sh start namenodestop-all.sh
start-all.sh[root@namenode01 ~]# jps
17419 NameNode
17780 ResourceManager
18152 Jps
[root@datanode01 ~]# jps
27264 -- process information unavailable
2227 DataNode
1292 QuorumPeerMain
2509 Jps
2334 NodeManager
[root@datanode02 ~]# jps
13940 QuorumPeerMain
18980 DataNode
19093 NodeManager
27292 -- process information unavailable
32526 -- process information unavailable
19743 Jps
[root@datanode03 ~]# jps
19238 DataNode
19350 NodeManager
14215 QuorumPeerMain
27351 -- process information unavailable
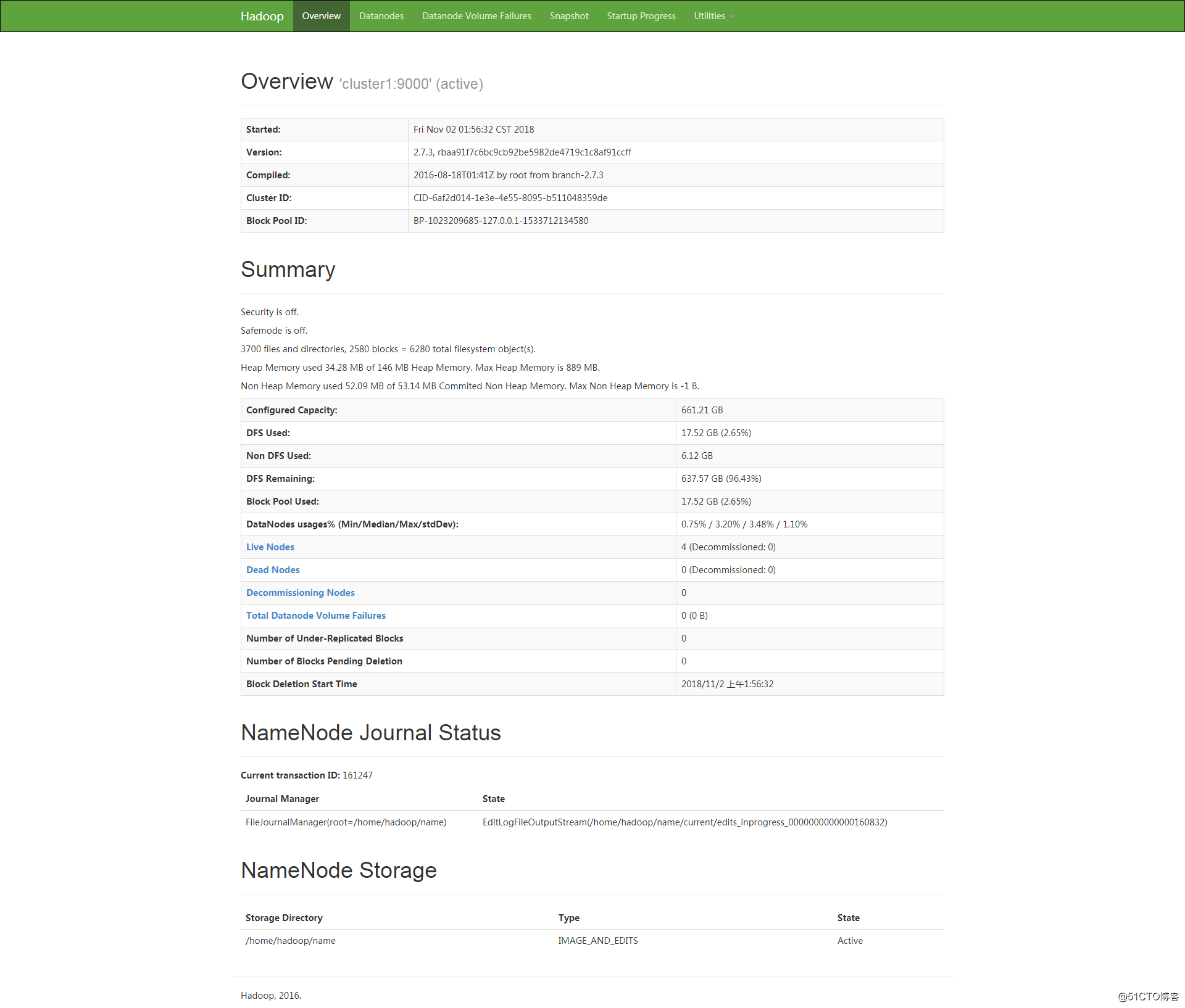
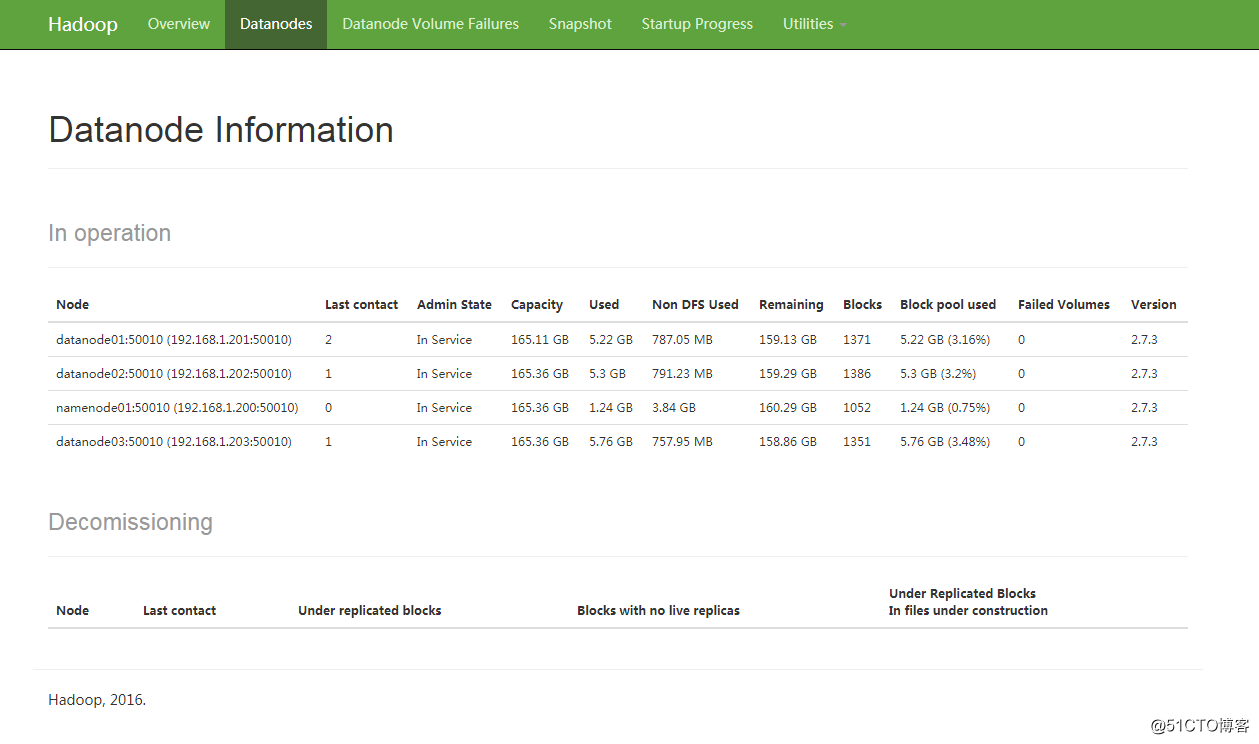
20014 Jps访问 http://192.168.1.200:50070/
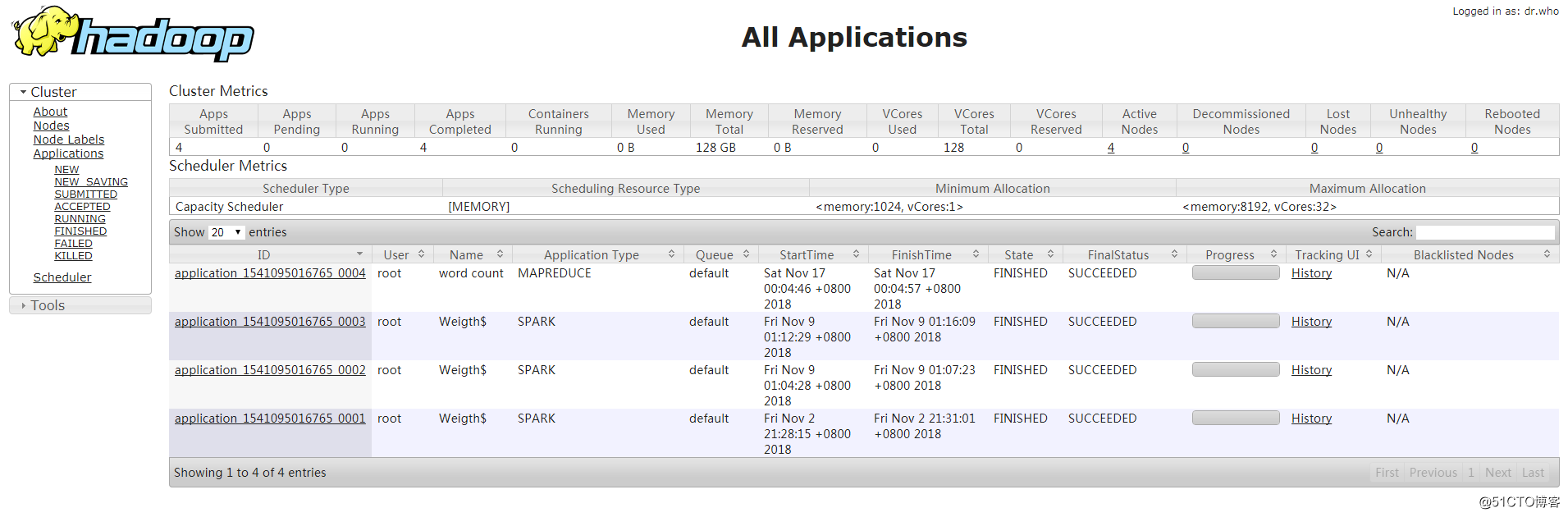
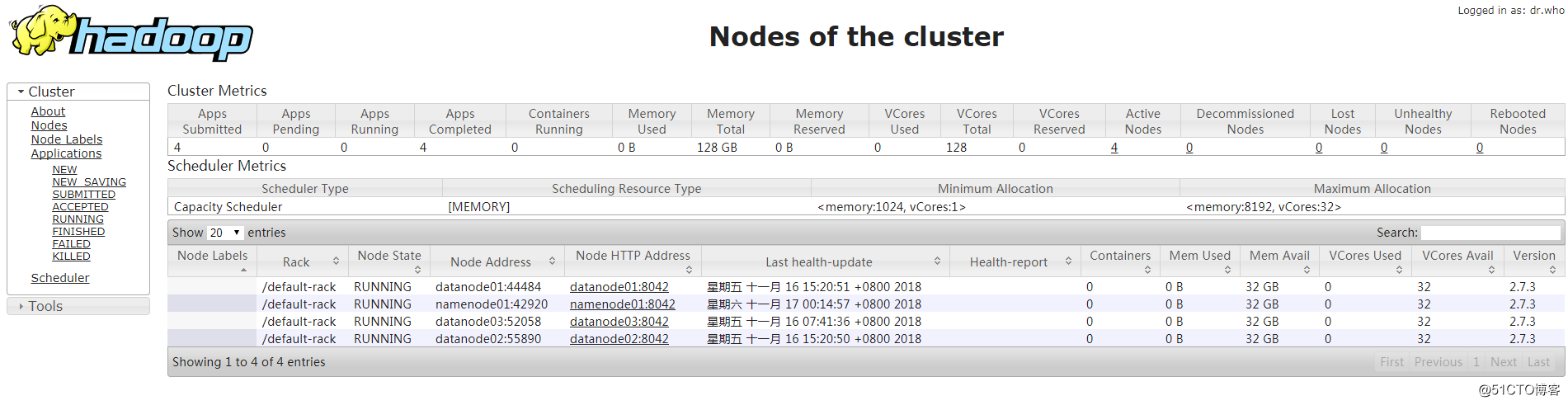
[root@namenode01 ~]# hadoop fs -put /root/anaconda-ks.cfg /anaconda-ks.cfg[root@namenode01 ~]# cd /usr/local/hadoop/share/hadoop/mapreduce/
[root@namenode01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /anaconda-ks.cfg /test
18/11/17 00:04:45 INFO client.RMProxy: Connecting to ResourceManager at namenode01/192.168.1.200:8032
18/11/17 00:04:45 INFO input.FileInputFormat: Total input paths to process : 1
18/11/17 00:04:45 INFO mapreduce.JobSubmitter: number of splits:1
18/11/17 00:04:45 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1541095016765_0004
18/11/17 00:04:46 INFO impl.YarnClientImpl: Submitted application application_1541095016765_0004
18/11/17 00:04:46 INFO mapreduce.Job: The url to track the job: http://namenode01:8088/proxy/application_1541095016765_0004/
18/11/17 00:04:46 INFO mapreduce.Job: Running job: job_1541095016765_0004
18/11/17 00:04:51 INFO mapreduce.Job: Job job_1541095016765_0004 running in uber mode : false
18/11/17 00:04:51 INFO mapreduce.Job: map 0% reduce 0%
18/11/17 00:04:55 INFO mapreduce.Job: map 100% reduce 0%
18/11/17 00:04:59 INFO mapreduce.Job: map 100% reduce 100%
18/11/17 00:04:59 INFO mapreduce.Job: Job job_1541095016765_0004 completed successfully
18/11/17 00:04:59 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1222
FILE: Number of bytes written=241621
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1023
HDFS: Number of bytes written=941
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1758
Total time spent by all reduces in occupied slots (ms)=2125
Total time spent by all map tasks (ms)=1758
Total time spent by all reduce tasks (ms)=2125
Total vcore-milliseconds taken by all map tasks=1758
Total vcore-milliseconds taken by all reduce tasks=2125
Total megabyte-milliseconds taken by all map tasks=1800192
Total megabyte-milliseconds taken by all reduce tasks=2176000
Map-Reduce Framework
Map input records=38
Map output records=90
Map output bytes=1274
Map output materialized bytes=1222
Input split bytes=101
Combine input records=90
Combine output records=69
Reduce input groups=69
Reduce shuffle bytes=1222
Reduce input records=69
Reduce output records=69
Spilled Records=138
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=99
CPU time spent (ms)=970
Physical memory (bytes) snapshot=473649152
Virtual memory (bytes) snapshot=4921606144
Total committed heap usage (bytes)=441450496
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=922
File Output Format Counters
Bytes Written=941[root@namenode01 mapreduce]# hadoop fs -cat /test/part-r-00000
# 11
#version=DEVEL 1
$6$kRQ2y1nt/B6c6ETs$ITy0O/E9P5p0ePWlHJ7fRTqVrqGEQf7ZGi5IX2pCA7l25IdEThUNjxelq6wcD9SlSa1cGcqlJy2jjiV9/lMjg/ 1
%addon 1
%end 2
%packages 1
--all 1
--boot-drive=sda 1
--bootproto=dhcp 1
--device=enp1s0 1
--disable 1
--drives=sda 1
--enable 1
--enableshadow 1
--hostname=localhost.localdomain 1
--initlabel 1
--ipv6=auto 1
--isUtc 1
--iscrypted 1
--location=mbr 1
--onboot=off 1
--only-use=sda 1
--passalgo=sha512 1
--reserve-mb=‘auto‘ 1
--type=lvm 1
--vckeymap=cn 1
--xlayouts=‘cn‘ 1
@^minimal 1
@core 1
Agent 1
Asia/Shanghai 1
CDROM 1
Keyboard 1
Network 1
Partition 1
Root 1
Run 1
Setup 1
System 4
Use 2
auth 1
authorization 1
autopart 1
boot 1
bootloader 2
cdrom 1
clearing 1
clearpart 1
com_redhat_kdump 1
configuration 1
first 1
firstboot 1
graphical 2
ignoredisk 1
information 3
install 1
installation 1
keyboard 1
lang 1
language 1
layouts 1
media 1
network 2
on 1
password 1
rootpw 1
the 1
timezone 2
zh_CN.UTF-8 1查看fs帮助命令: hadoop fs -help
查看HDFS磁盘空间: hadoop fs -df -h
创建目录: hadoop fs -mkdir
上传本地文件: hadoop fs -put
查看文件: hadoop fs -ls
查看文件内容: hadoop fs –cat
复制文件: hadoop fs -cp
下载HDFS文件到本地: hadoop fs -get
移动文件: hadoop fs -mv
删除文件: hadoop fs -rm -r -f
删除文件夹: hadoop fs -rm –r
标签:shanghai 查看 0ms 列表 ade 命名 后台 创建 容器
原文地址:http://blog.51cto.com/wzlinux/2317912