标签:ide pre reduce 分布 png set extend ... apr
操作背景
jdk的版本为1.8以上
ubuntu12
hadoop2.5伪分布
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的 hadoop2x-eclipse-plugin(备用下载地址:http://pan.baidu.com/s/1i4ikIoP)。
下载后,将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行
eclipse -clean 重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。
在继续配置前请确保已经开启了 Hadoop
1. 按照如下流程进入Hadoop Map/Reduce界面
Window--》Preference--》Hadoop Map/Reduce
点击右侧的Browse...选择Hadoop的安装路径,然后点击ok即可
2.按照如下操作到切换 Map/Reduce 开发视图
Window--》Open Perspective--》Other
弹出一个窗口选择Map/Reduce即可
3.建立与 Hadoop 集群的连接
点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location
在弹出的General选项面板里
设置两处
1.Location Name随便写就是连接名
2.DFS Master的Port与fs.defaultFS(设置为hdfs://localhost:9000)的端口号相同为9000
设置完成以后配置好后,点击左侧 Project Explorer 中的 MapReduce Location (点击三角形展开)就能直接查看 HDFS 中的文件列表了,双击可以查看内容,右键点击可以上传、下载、删除
用刚刚创建的Map/Reduce视图新建目录mymapreduce1/in,在此目录下上传文件文件名为buyer_favorite1,
这个文件的目录和名字可以自行修改,但要注意修改代码中的Path in的路径和文价名
此文件为某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段
内容如下
买家id 商家id 收藏日期
10181 1000481 2010-04-04 16:54:31 20001 1001597 2010-04-07 15:07:52 20001 1001560 2010-04-07 15:08:27 20042 1001368 2010-04-08 08:20:30 20067 1002061 2010-04-08 16:45:33 20056 1003289 2010-04-12 10:50:55 20056 1003290 2010-04-12 11:57:35 20056 1003292 2010-04-12 12:05:29 20054 1002420 2010-04-14 15:24:12 20055 1001679 2010-04-14 19:46:04 20054 1010675 2010-04-14 15:23:53 20054 1002429 2010-04-14 17:52:45 20076 1002427 2010-04-14 19:35:39 20054 1003326 2010-04-20 12:54:44 20056 1002420 2010-04-15 11:24:49 20064 1002422 2010-04-15 11:35:54 20056 1003066 2010-04-15 11:43:01 20056 1003055 2010-04-15 11:43:06 20056 1010183 2010-04-15 11:45:24 20056 1002422 2010-04-15 11:45:49 20056 1003100 2010-04-15 11:45:54 20056 1003094 2010-04-15 11:45:57 20056 1003064 2010-04-15 11:46:04 20056 1010178 2010-04-15 16:15:20 20076 1003101 2010-04-15 16:37:27 20076 1003103 2010-04-15 16:37:05 20076 1003100 2010-04-15 16:37:18
点击File--》New--》Other找到Map/Reduce Project点击创建即可。
然后将以下代码放到项目中
代码是是统计每个买家收藏商品数量
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(); job.setJobName("WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(doMapper.class); job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //这个路径是存放用户收藏商品的信息 Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1"); //这个路径也可自行设置,但是路径必须不存在 Path out = new Path("hdfs://localhost:9000/mymapreduce1/out"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); System.exit(job.waitForCompletion(true) ? 0 : 1); } /** * * 第一个Object表示输入key的类型;第二个Text表示输入value的类型; *第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型 */ public static class doMapper extends Mapper<Object, Text, Text, IntWritable> { public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { //StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分 //StringTokenizer构造函数的第二个参数是分割符,确认文件中的分割符是三个空格或者一个tab StringTokenizer tokenizer = new StringTokenizer(value.toString(), " "); word.set(tokenizer.nextToken()); context.write(word, one); } } //参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型 public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } result.set(sum); context.write(key, result); } } }
右键此Map/Reduce Project=>Run As=>Run on Hadoop
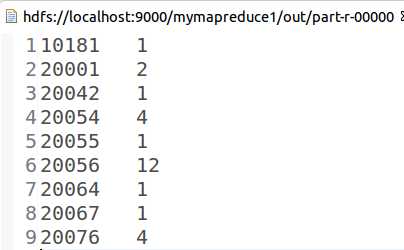
Map/Reduce视图工具查看输出目录中的part-r-00000文件
结果如下
参考资料
http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/?tdsourcetag=s_pcqq_aiomsg
大数据学习——MapReduce学习——字符统计WordCount
标签:ide pre reduce 分布 png set extend ... apr
原文地址:https://www.cnblogs.com/wei-jing/p/9971690.html