标签:exce proc als 自定义 文本编辑 positive 阅读量 expand 查询
1、将阅读量的代码封装在一个app中,增加扩展性
新建app:
python manage.py startapp read_statistics
2、变化的部分
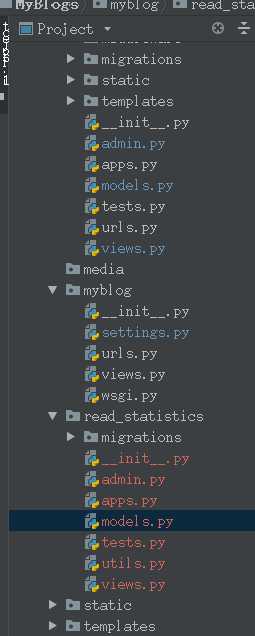
3、上代码

from django.contrib import admin from .models import BlogType, Blog # Register your models here. @admin.register(BlogType) class BlogTypeAdmin(admin.ModelAdmin): list_display = (‘id‘, ‘type_name‘) # 需要显示的列表 @admin.register(Blog) class BlogAdmin(admin.ModelAdmin): list_display = (‘title‘, ‘blog_type‘, ‘author‘, ‘get_read_num‘, ‘created_time‘, ‘last_updated_time‘)
from django.db import models from django.contrib.auth.models import User from ckeditor_uploader.fields import RichTextUploadingField from django.contrib.contenttypes.models import ContentType from read_statistics.models import ReadNum, ReadNumExpandMethod # Create your models here. # 博客分类 class BlogType(models.Model): type_name = models.CharField(max_length=15) # 博客分类名称 def __str__(self): # 显示标签名 return self.type_name # 博客 class Blog(models.Model, ReadNumExpandMethod): title = models.CharField(max_length=50) # 博客标题 blog_type = models.ForeignKey(BlogType, on_delete=models.DO_NOTHING) # 博客分类 content = RichTextUploadingField() # 博客内容,使用富文本编辑 author = models.ForeignKey(User, on_delete=models.DO_NOTHING) # 博客作者 created_time = models.DateTimeField(auto_now_add=True) # 博客创建时间 last_updated_time = models.DateTimeField(auto_now=True) # 博客更新事件 def __str__(self): # 显示标题名 return "<Blog:{}>".format(self.title) class Meta: ordering = [‘-created_time‘] # 定义排序规则,按照创建时间倒序
from django.shortcuts import render_to_response, get_object_or_404 from .models import Blog, BlogType from django.core.paginator import Paginator from django.conf import settings from django.db.models import Count from read_statistics.utils import read_statistics_once_read # 分页部分公共代码 def blog_list_common_data(requests, blogs_all_list): paginator = Paginator(blogs_all_list, settings.EACH_PAGE_BLOGS_NUMBER) # 第一个参数是全部内容,第二个是每页多少 page_num = requests.GET.get(‘page‘, 1) # 获取url的页面参数(get请求) page_of_blogs = paginator.get_page(page_num) # 从分页器中获取指定页码的内容 current_page_num = page_of_blogs.number # 获取当前页 all_pages = paginator.num_pages if all_pages < 5: page_range = list( range(max(current_page_num - 2, 1), min(all_pages + 1, current_page_num + 3))) # 获取需要显示的页码 并且剔除不符合条件的页码 else: if current_page_num <= 2: page_range = range(1, 5 + 1) elif current_page_num >= all_pages - 2: page_range = range(all_pages - 4, paginator.num_pages + 1) else: page_range = list( range(max(current_page_num - 2, 1), min(all_pages + 1, current_page_num + 3))) # 获取需要显示的页码 并且剔除不符合条件的页码 blog_dates = Blog.objects.dates(‘created_time‘, ‘month‘, order=‘DESC‘) blog_dates_dict = {} for blog_date in blog_dates: blog_count = Blog.objects.filter(created_time__year=blog_date.year, created_time__month=blog_date.month).count() blog_dates_dict = { blog_date: blog_count } return { ‘blogs‘: page_of_blogs.object_list, ‘page_of_blogs‘: page_of_blogs, ‘blog_types‘: BlogType.objects.annotate(blog_count=Count(‘blog‘)), # 添加查询并添加字段 ‘page_range‘: page_range, ‘blog_dates‘: blog_dates_dict } # 博客列表 def blog_list(requests): blogs_all_list = Blog.objects.all() # 获取全部博客 context = blog_list_common_data(requests, blogs_all_list) return render_to_response(‘blog/blog_list.html‘, context) # 根据类型筛选 def blogs_with_type(requests, blog_type_pk): blog_type = get_object_or_404(BlogType, pk=blog_type_pk) blogs_all_list = Blog.objects.filter(blog_type=blog_type) # 获取全部博客 context = blog_list_common_data(requests, blogs_all_list) context[‘blog_type‘] = blog_type return render_to_response(‘blog/blog_with_type.html‘, context) # 根据日期筛选 def blogs_with_date(requests, year, month): blogs_all_list = Blog.objects.filter(created_time__year=year, created_time__month=month) # 获取全部博客 context = blog_list_common_data(requests, blogs_all_list) context[‘blogs_with_date‘] = ‘{}年{}日‘.format(year, month) return render_to_response(‘blog/blog_with_date.html‘, context) # 博客详情 def blog_detail(requests, blog_pk): blog = get_object_or_404(Blog, pk=blog_pk) obj_key = read_statistics_once_read(requests, blog) context = { ‘blog‘: blog, ‘previous_blog‘: Blog.objects.filter(created_time__gt=blog.created_time).last(), ‘next_blog‘: Blog.objects.filter(created_time__lt=blog.created_time).first(), } response = render_to_response(‘blog/blog_detail.html‘, context) response.set_cookie(obj_key, ‘true‘) return response
""" Django settings for myblog project. Generated by ‘django-admin startproject‘ using Django 2.1.3. For more information on this file, see https://docs.djangoproject.com/en/2.1/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/2.1/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/2.1/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = ‘ea+kzo_5k^6r7micfg@lar1(rfdc08@b4*+w5d11=0mp1p5ngr‘ # SECURITY WARNING: don‘t run with debug turned on in production! DEBUG = True ALLOWED_HOSTS = [] # Application definition INSTALLED_APPS = [ ‘django.contrib.admin‘, ‘django.contrib.auth‘, ‘django.contrib.contenttypes‘, ‘django.contrib.sessions‘, ‘django.contrib.messages‘, ‘django.contrib.staticfiles‘, ‘ckeditor‘, ‘ckeditor_uploader‘, ‘blog.apps.BlogConfig‘, # 将自己创建的app添加到设置中 ‘read_statistics.apps.ReadStatisticsConfig‘, # 注册阅读统计app ] MIDDLEWARE = [ ‘django.middleware.security.SecurityMiddleware‘, ‘django.contrib.sessions.middleware.SessionMiddleware‘, ‘django.middleware.common.CommonMiddleware‘, ‘django.middleware.csrf.CsrfViewMiddleware‘, ‘django.contrib.auth.middleware.AuthenticationMiddleware‘, ‘django.contrib.messages.middleware.MessageMiddleware‘, ‘django.middleware.clickjacking.XFrameOptionsMiddleware‘, ‘blog.middleware.mymiddleware.My404‘, # 添加自己的中间件 ] ROOT_URLCONF = ‘myblog.urls‘ TEMPLATES = [ { ‘BACKEND‘: ‘django.template.backends.django.DjangoTemplates‘, ‘DIRS‘: [ os.path.join(BASE_DIR, ‘templates‘), ], ‘APP_DIRS‘: True, ‘OPTIONS‘: { ‘context_processors‘: [ ‘django.template.context_processors.debug‘, ‘django.template.context_processors.request‘, ‘django.contrib.auth.context_processors.auth‘, ‘django.contrib.messages.context_processors.messages‘, ], }, }, ] WSGI_APPLICATION = ‘myblog.wsgi.application‘ # Database # https://docs.djangoproject.com/en/2.1/ref/settings/#databases DATABASES = { # ‘default‘: { # ‘ENGINE‘: ‘django.db.backends.sqlite3‘, # ‘NAME‘: os.path.join(BASE_DIR, ‘db.sqlite3‘), # } ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: ‘myblogs‘, # 要连接的数据库,连接前需要创建好 ‘USER‘: ‘root‘, # 连接数据库的用户名 ‘PASSWORD‘: ‘felixwang‘, # 连接数据库的密码 ‘HOST‘: ‘127.0.0.1‘, # 连接主机,默认本级 ‘PORT‘: 3306 # 端口 默认3306 } } # Password validation # https://docs.djangoproject.com/en/2.1/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { ‘NAME‘: ‘django.contrib.auth.password_validation.UserAttributeSimilarityValidator‘, }, { ‘NAME‘: ‘django.contrib.auth.password_validation.MinimumLengthValidator‘, }, { ‘NAME‘: ‘django.contrib.auth.password_validation.CommonPasswordValidator‘, }, { ‘NAME‘: ‘django.contrib.auth.password_validation.NumericPasswordValidator‘, }, ] # Internationalization # https://docs.djangoproject.com/en/2.1/topics/i18n/ # LANGUAGE_CODE = ‘en-us‘ # 语言 LANGUAGE_CODE = ‘zh-hans‘ # TIME_ZONE = ‘UTC‘ # 时区 TIME_ZONE = ‘Asia/Shanghai‘ USE_I18N = True USE_L10N = True # 不考虑时区 USE_TZ = False # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.1/howto/static-files/ STATIC_URL = ‘/static/‘ STATICFILES_DIRS = [ os.path.join(BASE_DIR, "static") ] # media MEDIA_URL = ‘/media/‘ MEDIA_ROOT = os.path.join(BASE_DIR, ‘media‘) # 配置ckeditor CKEDITOR_UPLOAD_PATH = ‘upload/‘ # 自定义参数 EACH_PAGE_BLOGS_NUMBER = 7
from django.contrib import admin from .models import ReadNum # Register your models here. @admin.register(ReadNum) class ReadNumAdmin(admin.ModelAdmin): list_display = (‘read_num‘, ‘content_object‘)
from django.db import models from django.contrib.contenttypes.fields import GenericForeignKey from django.contrib.contenttypes.models import ContentType from django.db.models.fields import exceptions # Create your models here. # 使用到了contenttype 参考网址:https://docs.djangoproject.com/en/2.1/ref/contrib/contenttypes/ class ReadNum(models.Model): read_num = models.IntegerField(default=0) # 阅读量 content_type = models.ForeignKey(ContentType, on_delete=models.DO_NOTHING) object_id = models.PositiveIntegerField() content_object = GenericForeignKey(‘content_type‘, ‘object_id‘) def __str__(self): return str(self.read_num) # 阅读计数扩展方法 class ReadNumExpandMethod: def get_read_num(self): # 获取一对一关联的阅读数 try: ct = ContentType.objects.get_for_model(self) readnum = ReadNum.objects.get(content_type=ct, object_id=self.pk) return readnum.read_num except exceptions.ObjectDoesNotExist as e: return 0
# -*- coding: utf-8 -*- # @Time : 18-11-17 下午10:03 # @Author : Felix Wang from django.contrib.contenttypes.models import ContentType from read_statistics.models import ReadNum def read_statistics_once_read(requests, obj): ct = ContentType.objects.get_for_model(obj) key = ‘{}_{}_read‘.format(ct.model, obj.pk) # 获取并处理阅读计数 if not requests.COOKIES.get(key): if ReadNum.objects.filter(content_type=ct, object_id=obj.pk).count(): readnum = ReadNum.objects.get(content_type=ct, object_id=obj.pk) else: readnum = ReadNum(content_type=ct, object_id=obj.pk) # 处理阅读量 readnum.read_num += 1 readnum.save() return key
4、封装和优化了之前的代码
from django.shortcuts import render_to_response, get_object_or_404
from .models import Blog, BlogType
from django.core.paginator import Paginator
from django.conf import settings
from django.db.models import Count
from read_statistics.utils import read_statistics_once_read
# 分页部分公共代码
def blog_list_common_data(requests, blogs_all_list):
paginator = Paginator(blogs_all_list, settings.EACH_PAGE_BLOGS_NUMBER) # 第一个参数是全部内容,第二个是每页多少
page_num = requests.GET.get(‘page‘, 1) # 获取url的页面参数(get请求)
page_of_blogs = paginator.get_page(page_num) # 从分页器中获取指定页码的内容
current_page_num = page_of_blogs.number # 获取当前页
all_pages = paginator.num_pages
if all_pages < 5:
page_range = list(
range(max(current_page_num - 2, 1),
min(all_pages + 1, current_page_num + 3))) # 获取需要显示的页码 并且剔除不符合条件的页码
else:
if current_page_num <= 2:
page_range = range(1, 5 + 1)
elif current_page_num >= all_pages - 2:
page_range = range(all_pages - 4, paginator.num_pages + 1)
else:
page_range = list(
range(max(current_page_num - 2, 1),
min(all_pages + 1, current_page_num + 3))) # 获取需要显示的页码 并且剔除不符合条件的页码
blog_dates = Blog.objects.dates(‘created_time‘, ‘month‘, order=‘DESC‘)
blog_dates_dict = {}
for blog_date in blog_dates:
blog_count = Blog.objects.filter(created_time__year=blog_date.year, created_time__month=blog_date.month).count()
blog_dates_dict = {
blog_date: blog_count
}
return {
‘blogs‘: page_of_blogs.object_list,
‘page_of_blogs‘: page_of_blogs,
‘blog_types‘: BlogType.objects.annotate(blog_count=Count(‘blog‘)), # 添加查询并添加字段
‘page_range‘: page_range,
‘blog_dates‘: blog_dates_dict
}
# 博客列表
def blog_list(requests):
blogs_all_list = Blog.objects.all() # 获取全部博客
context = blog_list_common_data(requests, blogs_all_list)
return render_to_response(‘blog/blog_list.html‘, context)
# 根据类型筛选
def blogs_with_type(requests, blog_type_pk):
blog_type = get_object_or_404(BlogType, pk=blog_type_pk)
blogs_all_list = Blog.objects.filter(blog_type=blog_type) # 获取全部博客
context = blog_list_common_data(requests, blogs_all_list)
context[‘blog_type‘] = blog_type
return render_to_response(‘blog/blog_with_type.html‘, context)
# 根据日期筛选
def blogs_with_date(requests, year, month):
blogs_all_list = Blog.objects.filter(created_time__year=year, created_time__month=month) # 获取全部博客
context = blog_list_common_data(requests, blogs_all_list)
context[‘blogs_with_date‘] = ‘{}年{}日‘.format(year, month)
return render_to_response(‘blog/blog_with_date.html‘, context)
# 博客详情
def blog_detail(requests, blog_pk):
blog = get_object_or_404(Blog, pk=blog_pk)
obj_key = read_statistics_once_read(requests, blog)
context = {
‘blog‘: blog,
‘previous_blog‘: Blog.objects.filter(created_time__gt=blog.created_time).last(),
‘next_blog‘: Blog.objects.filter(created_time__lt=blog.created_time).first(),
}
response = render_to_response(‘blog/blog_detail.html‘, context)
response.set_cookie(obj_key, ‘true‘)
return response
标签:exce proc als 自定义 文本编辑 positive 阅读量 expand 查询
原文地址:https://www.cnblogs.com/felixwang2/p/9976094.html
