标签:ISE lis 连接 pen 很多 adt 深度优先遍历 个数 node
(图)
(图)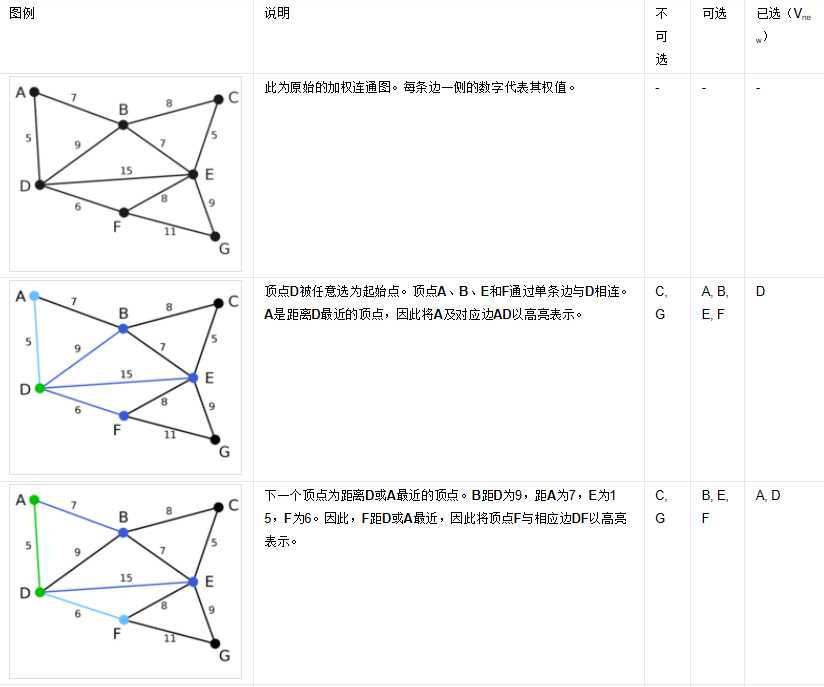
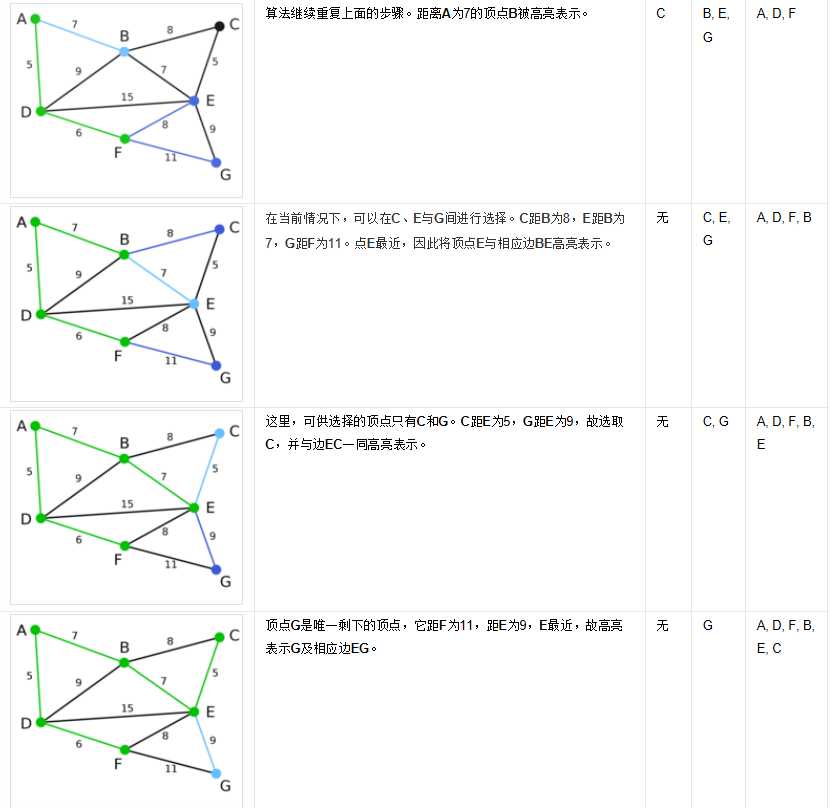

邻接矩阵:使用布尔数组来实现存储边。将存在边的位置记录为true,无位置的记录为false。对于一个无向图,其存储结果是一个对称矩阵。但是对于有向图来说,因为边的单向性,结果将不同。
问题1理解:首先打眼一看,似乎两个方法没什么区别。BFS相当于是从第一个顶点开始遍历完其所有的邻顶点的邻顶点再进行下一个的遍历。DFS类似于前序遍历。 通过对课本代码的分析。找出了几个关键部分代码。第一点,使用了不同的数据结构对其进行存储。BFS使用了队列的方式。DFS使用了栈进行存储。下面就详细的进行分析。先看BFS的代码。
while (!traversalQueue.isEmpty())
{
x = traversalQueue.dequeue();
resultList.addToRear(vertices[x.intValue()]);
//Find all vertices adjacent to x that have not been visited
// and queue them up
for (int i = 0; i < numVertices; i++)
{
if (adjMatrix[x.intValue()][i] && !visited[i])
{
traversalQueue.enqueue(new Integer(i));
visited[i] = true;
}
}
}首先,先声明,书上的方法均是是基于邻接矩阵实现的。具体来讲也就是两个布尔数组来确定顶点与顶底之间是否有边。将顶点进入队列后,再取出放入列表之中。然后根据邻接矩阵来判断边,也就是找出所有的邻接顶点。依次存入队列之中。当找到所有的邻接顶点后。将第一个进入队列的顶底取出,找出其所有的邻接顶点。之后再进行下一个顶点的邻接顶点的查询。通过队列先进先出的顺序,将所有顶点按照类似于树的先序遍历的方法储存起来。那么,如何防止出现重复的结点呢?建立的boolean型的visited数组就可以解决这个问题,初始化时所有结点都是false也就是未被访问。当访问到一个顶点后,将其标记为true。当下一次再访问到这个顶点后。就进行跳过。
while (!traversalStack.isEmpty())
{
x = traversalStack.peek();
found = false;
//Find a vertex adjacent to x that has not been visited
// and push it on the stack
for (int i = 0; (i < numVertices) && !found; i++)
{
if (adjMatrix[x.intValue()][i] && !visited[i])
{
traversalStack.push(new Integer(i));
resultList.addToRear(vertices[i]);
visited[i] = true;
found = true;
}
}
if (!found && !traversalStack.isEmpty())
traversalStack.pop();
}众所周知,栈是后进先出的。那么,如果以顶点V开始,它的第一个邻顶点为U。那么它入栈,紧接着寻找U的第一个邻顶点,然后将其入栈。每次使用peek方法获取当前栈顶元素,也就是上一个顶点的第一个邻顶点。当找不到时,将其弹出。就好比一棵树,当把这一棵子树的所有结点找完后,就去下一棵子树找。同理,循环会将已经都访问过的顶点弹出栈,直到找到没有访问过邻顶点的顶点。按照这个顺序,将顶点按照深度优先的顺序存入列表中。
int[] pathLength = new int[numVertices];
int[] predecessor = new int[numVertices];之后根据放入的顺序进行遍历,如果与顶点有边,那么,将其存入,之后用队列,将其存储。如果只是需要具体的数字,我们直接将其对应的索引对应的数字返回即可。
while (!traversalQueue.isEmpty() && (index != targetIndex))
{
index = (traversalQueue.dequeue()).intValue();
//Update the pathLength for each unvisited vertex adjacent
// to the vertex at the current index.
for (int i = 0; i < numVertices; i++)
{
if (adjMatrix[index][i] && !visited[i])//
{
pathLength[i] = pathLength[index] + 1;
predecessor[i] = index;
traversalQueue.enqueue(new Integer(i));
visited[i] = true;
}
}
}但是,我们不妨再将其顺序返回,使得其更加直观。通过之前对部分方法的分析我们不难发现,对于这种非线性数据结构,有时使用队列来达到层序遍历,而使用栈达到前序遍历(后序遍历)这时,我们就用栈(后进先出)来实现。
StackADT<Integer> stack = new LinkedStack<Integer>();
index = targetIndex;
stack.push(new Integer(index));
do
{
index = predecessor[index];
stack.push(new Integer(index));
} while (index != startIndex);
while (!stack.isEmpty())
resultList.addToRear(((Integer)stack.pop()));public static final double POSITIVE_INFINITY = 1.0 / 0.0;就是无穷大了,它被定义于Double中,可以直接调用。然后,首先对目前已有的“非0(不是它自己)非-1(两者之间有边)。在这个基础上,选出最小的值,存入列表之中。之后,用最小值的索引值来继续向下遍历。换句话说,对于dist数组中存取数据为无穷大的(也就是计算出未直接与初顶点相连的间接权重)
for (int i = 0; i < numVertices; i++) {
flag[i] = false;
dist[i] = adjMatrix[start][i];
}for (int j = 0; j < numVertices; j++) {
if (flag[j] == false && dist[j] < min && dist[j] != -1 && dist[j] != 0) {
min = dist[j];
k = j;
}
}这里的k就是最小权的索引值。每次都选择最小的权重边作为路径。然后重复这个过程。最终,整个disc数组的每个索引对应的就是从初顶点到该对应索引的最短权重路径。我们根据需要,取出即可。
for (int j = 0; j < numVertices; j++) {
if (adjMatrix[k][j] != -1&&dist[j]!= -1) {
double temp = (adjMatrix[k][j] == Double.POSITIVE_INFINITY
? Double.POSITIVE_INFINITY : (min + adjMatrix[k][j]));
if (flag[j] == false && (temp < dist[j])) {
dist[j] = temp;
}
}
}
}
return dist[end];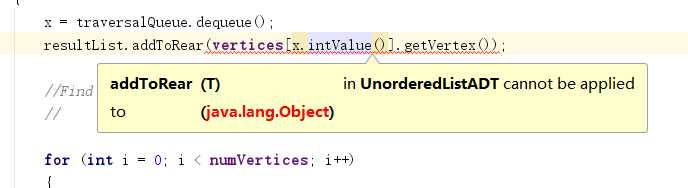 ,按理来说,这两者似乎没什么区别。在上学期的学习中,有一个定义让我印象深刻,就是Object类是所有类的父类。所以Object范围非常广,而T从一开始就会限定这个类型(包括它可以限定类型为Object)。
,按理来说,这两者似乎没什么区别。在上学期的学习中,有一个定义让我印象深刻,就是Object类是所有类的父类。所以Object范围非常广,而T从一开始就会限定这个类型(包括它可以限定类型为Object)。对于堆,插入元素时,为了满足其完全树的定义,当一层未满时,优先将元素放至左孩子位置,如左孩子填满,则放至右孩子处。如果一层满。则放在下一层的第一个位置。
图的情况有很多种,有向和无向,有权重和无权重,遍历方法也比较难懂,需要继续学习
代码中值得学习的或问题:
代码写的很规范,思路很清晰,继续加油!
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 3/3 | |
| 第二周 | 409/409 | 1/2 | 5/8 | |
| 第三周 | 1174/1583 | 1/3 | 10/18 | |
| 第四周 | 1843/3426 | 2/5 | 10/28 | |
| 第五周 | 539/3965 | 2/7 | 20/48 | |
| 第六周 | 965/4936 | 1/8 | 20/68 | |
| 第七周 | 766/5702 | 1/9 | 20/88 | |
| 第八周 | 1562/7264 | 2/11 | 20/108 | |
| 第九周 | 2016/9280 | 1/12 | 20/128 |
标签:ISE lis 连接 pen 很多 adt 深度优先遍历 个数 node
原文地址:https://www.cnblogs.com/326477465-a/p/9976176.html