标签:处理海量数据 inf 一个 角度 需要 核心模块 pre print ado
Hadoop 两个核心模块:
(1)计算模块 MapReduce
(2)存储模块 分布式文件系统
Hadoop解决了什么问题?
海量数据需要及时分析和处理
海量数据需要深入分析和挖掘
数据需要长期保存
MapReduce引入:一个用于处理海量数据的分布式计算框架
MapReduce主要从两个方面来讲,Map和Reduce,其中map可以理解为分的过程,而Reduce是合的过程,现在从wordcount的角度可以更好的理解mapreduce的过程
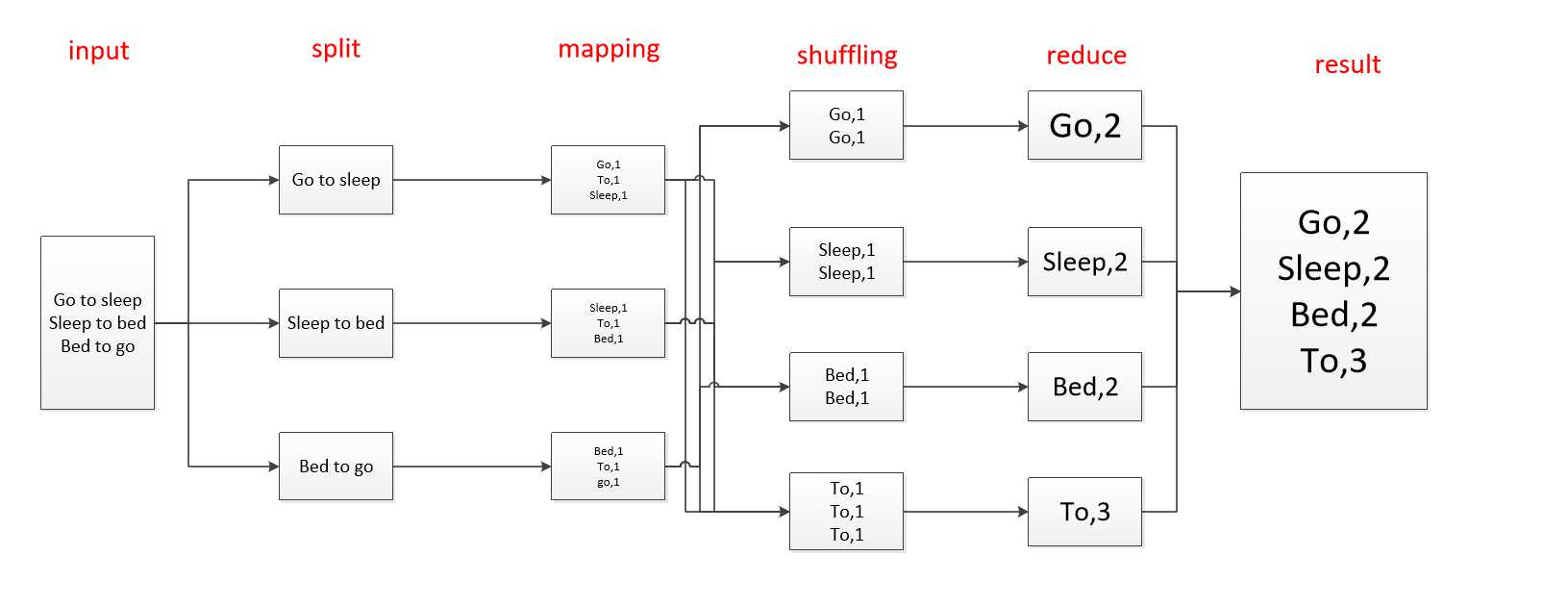
如上图所示就是一个简单的worldcount的例子,python代码如下所示
Map阶段:
import sys for line in sys.stdin:
ss = line.strip().split
for word in ss:
print ‘\t‘.join([word.split(),‘1‘])
Reduce阶段:
import sys cur_word=None sum =0 for line in sys.stdin: ss = line.strip().split(‘\t‘) if len(ss)!=2 continue word ,cnt=ss if cur_word = None: cur_word = word if cur_word != word: print ‘\t‘.join([cur_word,str(sum)])
cur_word = word
sum = 0
sum+=int(count)
print ‘\t‘.join([cur_word,str(sum)])
标签:处理海量数据 inf 一个 角度 需要 核心模块 pre print ado
原文地址:https://www.cnblogs.com/boboli/p/9977542.html