标签:距离 core span 推荐算法 nes 图像压缩 des recommend 相对
我们知道,在实际生活中,采集到的数据大部分信息都是无用的噪声和冗余信息,那么,我们如何才能剔除掉这些噪声和无用的信息,只保留包含绝大部分重要信息的数据特征呢?
除了上次降到的PCA方法,本次介绍另外一种方法,即SVD。SVD可以用于简化数据,提取出数据的重要特征,而剔除掉数据中的噪声和冗余信息。SVD在现实中可以应用于推荐系统用于提升性能,也可以用于图像压缩,节省内存。
1 svd原理--矩阵分解
在很多情况下,数据中的一小段携带了数据集的大部分信息,其他信息则要么是噪声,要么是毫不相关的信息。而矩阵分解技术可以将原始矩阵表示成新的易于理解的形式,即将数据矩阵表示成两个或者多个矩阵相乘的形式。而我们这里要讲的SVD,就是最常用的一种矩阵分解技术,SVD将原始的数据矩阵D分解成三个矩阵U,Σ和VT。如果原始矩阵是m行n列,那么U,Σ和VT就分别是m行m列,m行n列,以及n行n列,即:
Dm×n=Um×m Σm×n和VTn×n (1)
其中,矩阵Σ是一个只含对角元素的矩阵,其余元素都为0;此外,Σ的对角元素值是按照由大到小排列的。这就给了我们一个启示,如果某一数据矩阵进过奇异值分解后得到的Σ,从某一对角元素值往后元素值小于某一很小的阈值,那么我们就可以将这些小于阈值的特征值忽略掉,只保留前面的包含绝大部分信息的特征值(一般情况下,这里的绝大部分指的是至少包含数据信息的90%的信息量)。这样,我们就能剔除掉数据中的噪声和冗余信息,使数据变得更加简洁和高效。
2 python实现SVD
在python中的Numpy中有一个线性工具箱叫做linalg,它可以帮助我们实现矩阵的奇异值分解,即调用语句:
from numpy import* from numpy import linalg U,Sigma,VT=linalg.svd(dataMat)
需要说明的是,在python中,由上述方法得到的Sigma,是Numpy的数组,所以,在实际的应用中,我们需要根据Sigma数组构建出相对应的方阵。比如,我们利用如下的矩阵来进行SVD,得到的Sigma如下所示:

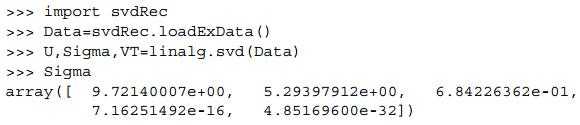
由上图可以看到,Sigma是以数组的形式呈现的,此外,前三个数值比其他值大很多个数量级。于是,我们可以将最后两个值去掉,只保留下前三个值,这样,SVD公式就变成这样:Dm×n=Um×3 Σ3×3和VT3×n。也是我们只用矩阵U的前三列和VT的前三行,进行计算,从而将原始数据转化到低维度的空间。
当然,这里的3仅代表此情况下只保留Sigma的前三个特征奇异值。而在实际中,一个典型的做法是,保留矩阵中90%的能量信息。计算方法是,先求出所有奇异值的平方和,然后从第一个特征奇异值开始进行平方和累加,当达到总能量的90%以上时,这些特征奇异值就是要保留下来的奇异值,其余的奇异值全部舍弃。
1 相似度的计算
推荐引擎是机器学习的一个重要应用,比如,Amazon会根据顾客的购买历史向他们推荐物品,Netflix会像其用户推荐电影,新闻网站会对用户推荐新闻报道等等。当然,有很多方法可以实现推荐功能,比如基于内容的推荐,基于协同过滤的推荐,或者多个推荐相组合的推荐等等。基于内容的推荐,是通过机器学习的方法,比如决策树,神经网络等从用户对于物品的评价的内容特征描述中得到用户感兴趣的资料,而不需要其他用户的数据。而基于协同过滤的推荐方法则是通过将用户与其他用户的数据进行比对,依据相似度的大小实现推荐。
首先,在进行协同过滤之前,我们需要将数据转化为合理的形式,即将数据转化为矩阵的形式,这样,便于我们处理和计算相似度。当我们计算出了用户或者物品之间的相似度,我们就可以利用已有的数据来预测未知的用户喜好。比如,我们试图对某个用户喜欢的电影进行预测,推荐引擎会发现有一部电影该用户没有看过。然后,就会计算该电影和用户看过电影之间的相似度,如果相似度很高,推荐算法就会认为用户喜欢这部电影。
这里,协同过滤的相似度计算,并不是计算两个物品的属性信息的相似程度,而是基于用户对这些物品的评价信息来计算相似度。这也是协同过滤所使用的方法,即不关心物品的描述属性,而只关心用户对于物品的评价观点来进行相似度计算。
相似度的计算方法有很多,比如欧氏距离,相关系数,余弦距离等。相关系数和余弦距离,是对两个向量之间的比较。这两种方法相对于欧氏距离的一个优势在于,它们对于用户的评级的量级并不敏感。为了将相似度归一化,我们需要对着三种方法计算得到的结果,进行归一化处理,使其最终的结果位于(0,1)内,即:
欧式距离相似度=1/(1+欧式距离)
相关系数相似度=0.5+0.5*corrcoef()
余弦距离相似度=0.5+0.5*(cosine距离)
下面是具体的相似度计算方法代码:

from numpy import *
from numpy import linalg
#欧式距离相似度计算
def eulidSim(inA,inB):
return 1.0/(1.0+linalg.norm(inA,inB))
#相关系数相似度计算
def corrSim(inA,inB):
if len(inA)<3:return 1.0
return 0.5+0.5*corrcoef(inA,inB,rowvar=0)[0][1]
#余弦距离相似度计算
def cosineSim(inA,inB):
num=float(inA.T*inB)
denom=linalg.norm(inA)*linalg.norm(inB)
return 0.5+0.5*corrcoef(num/denom)
上面有了,相似度的计算方法,那么接下来要考虑的问题就是,是计算用户的相似度还是计算物品的相似度呢?显然,数据的行代表的是基于用户,而列代表的则是基于物品。具体使用哪一种相似度计算,需要根据用户或者物品的数目。因为,不管是基于物品的相似度还是基于用户的相似度都会随着各自的数目的增加,计算的时间也相应增加。所以,为了节省计算时间,我们按照数目相对较少的那一个量去计算相似度。显然,对于一家固定的餐馆,其菜品的数目基本是固定的,变化不大,但其用户数目却可能会发生很大的变化,所以,一般情况下,协同过滤的推荐方法会偏向于计算基于物品的相似度。
2 推荐引擎的评价
那么如何对推荐引擎进行评价呢?此时,我们既没有预测的目标值,也没有用户来调查他们对于预测的满意程度。这么我们采用前面多次使用的交叉测试的方法。即,将某些已知的物品评分删掉,然后对这些物品的评分进行预测,然后比较预测值和真实值的差异。
通常用于推荐系统的评价的指标是最小均方根误差。即,首先计算平方误差的均值,然后再对平均值开根号。
3 餐馆菜菜肴引擎
首先我们构建一个基本的推荐引擎,它能够寻找用户没有尝过的菜肴。然后,通过SVD来减少特征空间并提高推荐效果。
基本的推荐系统基本流程如下:
(1)寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值
(2)在用户没有评级的所有物品中,对每一个物品预测一个可能的评级分数。
(3)对这些物品的评分从高到低排序,返回前N个物品。
具体的代码如下:
#未评级物品的评分预测函数
#@dataMat:数据矩阵
#@user:目标用户编号(矩阵索引,从0开始)
#@simMeans:相似度计算方法 默认余弦距离
#@item:未评分物品编号(索引,从0开始)
def standEst(dataMat,user,simMeans,item):
#获取数据矩阵的列数
n=shape[dataMat][1]
#需要更新的两个相似度计算相关的值
simTotal=0.0;ratSimTotal=0.0
#遍历矩阵的每一列(遍历目标用户评价的物品列)
for j in range(m):
#如果目标用户对该物品为评分,跳出本次循环
userRating=dataMat[user,j]
if userRating==0:continue
#用‘logical_and‘函数,统计目标列与当前列中在当前行均有评分的数据
overLap=nonzero(logical_and(dataMat[:,item].A>0, dataMat[:,j].A>0))[0]
#如果不存在,则当前列于目标列相似性为0返回
if len(overLap)==0:simiarity=0
否则,计算这两列中均有评分的行之间的相似度
else:similarity=simMean(dataMat[overLap,item], dataMat[overLap,j])
#更新两个变量的值
simTotal+=similarity
ratSimTotal+=similarity+userRating
if simTotal==0:return 0
else:return ratSimTotal/simTotal
#推荐系统主体函数
#@dataMat:数据矩阵
#@user:目标用户编号(矩阵索引,从0开始)
#@N=3:保留的相似度最高的前N个菜肴,默认为3个
#@simMeas=cosSim:相似度计算方法 默认余弦距离
#@estMethod=standEst:评分方法,默认是standEst函数
def recommend(dataMat,user,N=3,simMeas=cosSim,estMethod=standEst):
#从数据矩阵中找出目标用户user所用的未评分的菜肴的列
unratedItems=nonzero(dataMat[user,:].A==0)[1]
#如果没有,表明所有菜肴均有评分
if len(unratedItems)==0:renturn ‘you rated everything‘
itemScores=[]
#遍历每一个未评分的矩阵列(未评分的菜肴)
for item in unratedItems:
#预估的评分采用默认的评分方法
estimatedScore=esMethod(dataMat,user,simMeans,item)
#将该菜肴及其预估评分加入数组列表
itemScores.append((item,estimatedScore))
#利用sorted函数对列表中的预估评分由高到低排序,返回前N个菜肴
return sorted(itemsScores,key=lambda jj=jj[1],reverse=True)[:N]
由上面的函数,我们知道,推荐系统对于用户没有评分的菜肴,通过计算该用户与其他用户评分的菜肴的相似度,来预估出该用户对于该未评分菜肴的评分,从而选择出评分最高的前N个菜肴推荐给用户。
有了基本的协同过滤的推荐系统,我们接下来在推荐系统中引入SVD,将高维的数据矩阵映射到低维的矩阵中去,然后,在低纬空间中,利用前面的相似度计算方法来进行推荐。具体的代码如下:
#引入SVD的推荐引擎
#@dataMat:数据矩阵
#@user:目标用户索引
#@simMeans:相似度计算方法
#@item:目标菜肴索引
def svdEst(dataMat,user,simMeans,item):
#获取数据矩阵列
n=shape(dataMat)[1]
simTotal=0.0;ratSimTotal=0.0
#svd进行奇异值分解
U,Sigma,VT=linalg.svd(dataMat)
#保留前四个奇异值,并将奇异值转化为方阵
Sig4=mat(eye(4)*Sigma[:4])
#将数据矩阵进行映射到低维空间
xformedItems=dataMat.T*U[:,:4]*Sig4.I
#遍历矩阵的每一列
for j in range(n):
#该用户当前菜肴未评分,则跳出本次循环
userRating=dataMat[user,j]
if userRating==0 or j ==item:continue
#否则,按照相似度计算方法进行评分
similarity=simMeans(xformedItems[item,:].T, xformedItems[j,:].T)
simTotal+=similarity
ratSimTotal+=similarity*userRating
if simTotal==0:return 0
else:return ratSimTotal/simTotal
由上面的函数可知,相比于普通的推荐系统,增加了SVD的计算,即对数据矩阵进行奇异值分值,保留包含数据信息90%能量的m奇异值,组成m*m的方阵。然后,利用矩阵U的前m列和m*m的奇异值方阵,将数据矩阵映射到低纬的空间。
4 推荐系统面临的挑战
(1)当数据集规模很大时,SVD分解会降低程序的速度,所以,在大型系统中,SVD运行的频率很低,并且需要离线运行。
(2)实际的数据矩阵中0的数目很多,显然会造成空间资源的浪费,如果有效的存储这些数据,可以帮助我们节省内存和计算开销。
(3)在程序中,每次需要计算一个得分时,都要计算多个物品的相似度得分。我们知道,这些得分记录的是物品的相似度。所以,我们可以离线计算相似度得分并保存,当需要的时候调用即可。
(4)冷启动问题,即如何在缺乏数据时给出好的推荐。这时,我们可以将推荐看成是搜索问题,这就要用到需要推荐物品的属性。在餐馆菜肴的推荐系统中,我们可以通过各种标签来标记菜肴,比如素食,美式BBQ,价格高低等。同时,我们也可以将这些属性作为相似度计算所需要的数据,即基内容的推荐。
SVD除了应用在推荐系统中,还可以用来进行数据压缩,比如图像压缩。比如,对一个32*32=1024像素的图像,首先,我们采用矩阵的形式存储该图像;然后,对于图像中每个像素值,我们采用阈值函数,将像素值大于0.8像素设置为1,否则设置为0;接下来,我们对该图像进行奇异值分解,得到矩阵U,Sigma和VT,我们保留包含图像信息90%的m(m<32)奇异值;最后,我们只保留矩阵U的前m列,矩阵VT的前m行,以及m个奇异值,就可以完成原始矩阵的重构。假设,m=4,那么需要保存的数值个数为32*4+4*32+4=258,相比于原始矩阵的1024,获得了接近4倍的压缩比。
SVD是一种类似于PCA的降维工具,我们可以利用SVD来提取矩阵的重要特征,选择保留数据90%的能量的情况下,剔除数据中的噪声和冗余信息。SVD的一个强大的应用是提高推荐系统的性能,通过将数据矩阵映射到低纬的空间进行计算相似度,从而提升推荐引擎的效果。SVD还可以用于数据的压缩等,从而达到节省内存的目的
标签:距离 core span 推荐算法 nes 图像压缩 des recommend 相对
原文地址:https://www.cnblogs.com/echoboy/p/9977755.html