标签:一段 本地 长度 索引 dea com string 路径 推广
目录
| 组员 | 职责 |
|---|---|
| 绪佩 | 组织分工、改进前端、后端、云化 |
| 庄卉 | 改进前端、后端 |
| 家伟 | 算法关键词识别、附加题实现 |
| 家灿 | 数据库 |
| 一好 | 算法随机数、算法审查 |
| 鸿杰 | 算法随机数、算法审查 |
| 政演 | 提供算法思路、附加题idea思路、博客撰写 |
| 凯琳 | 前端审查 |
| 丹丹 | 前端审查 |
| 青元 | 前端改进 |
| 宇恒 | 前端审查 |
运行结果
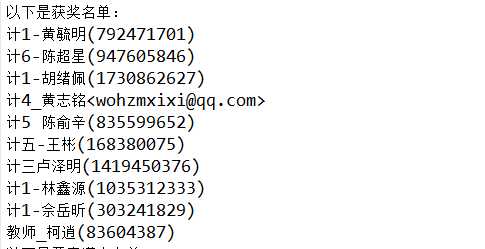
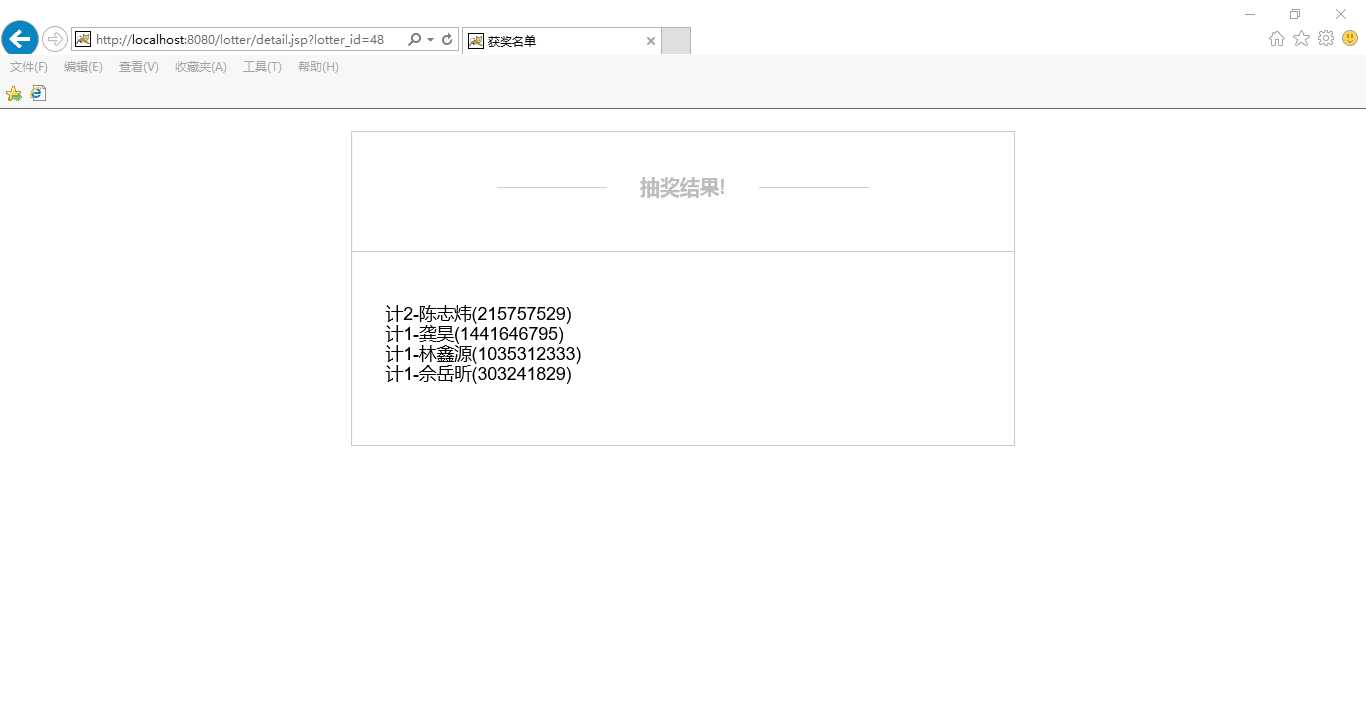
抽奖结果名单
| 环境 | 名称 |
|---|---|
| 操作系统 | Windows10 |
| 编译器 | Eclipse javaee |
| 本地服务器 | Tomcat |
| 数据库 | MySQL |
| 可视化数据库工具 | Navicat |
进入界面
抽奖规则设定1
抽奖规则设定2
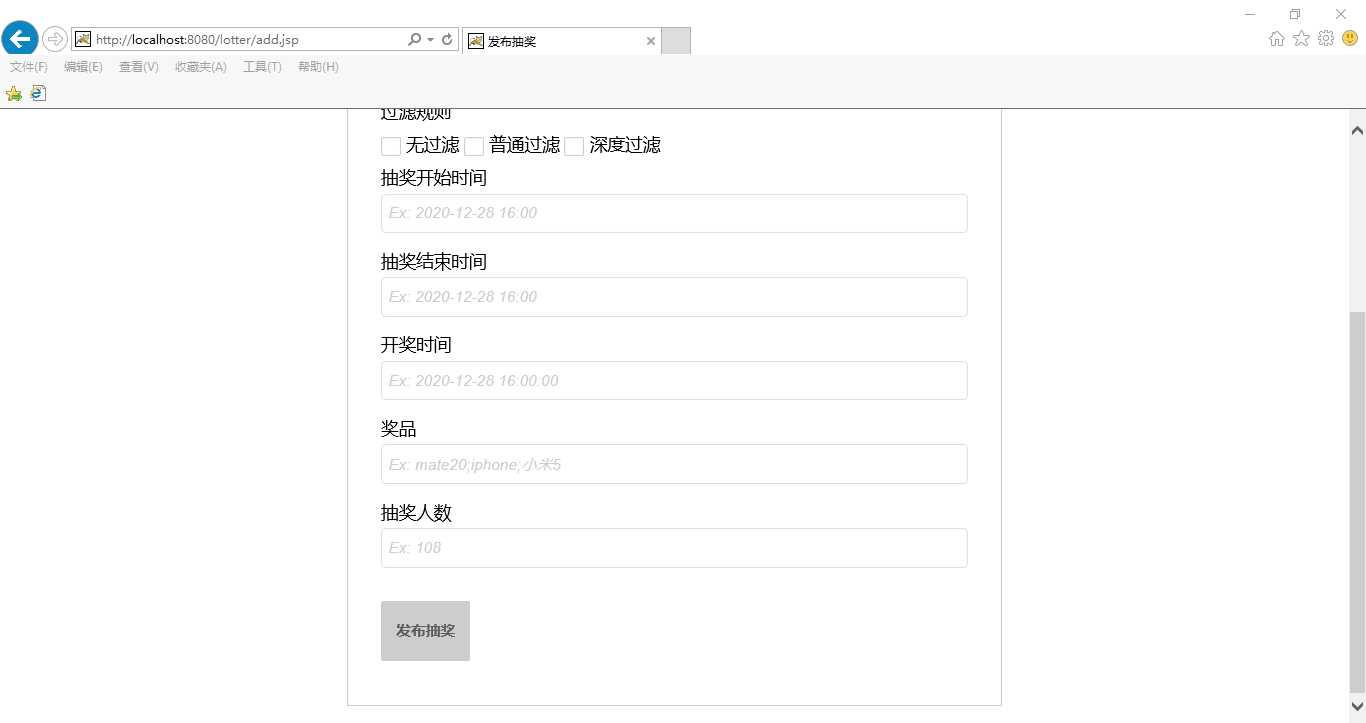
抽奖结果名单
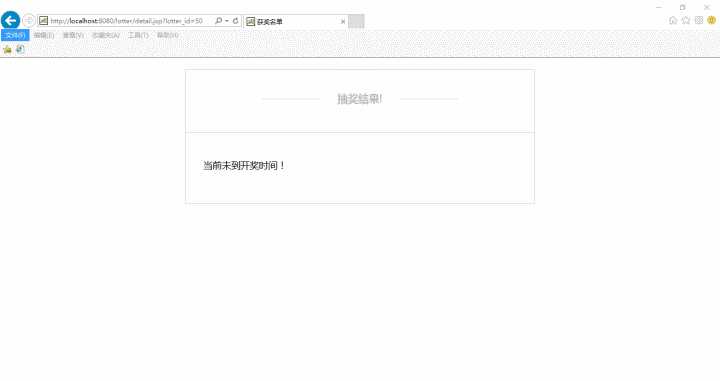
错误提示
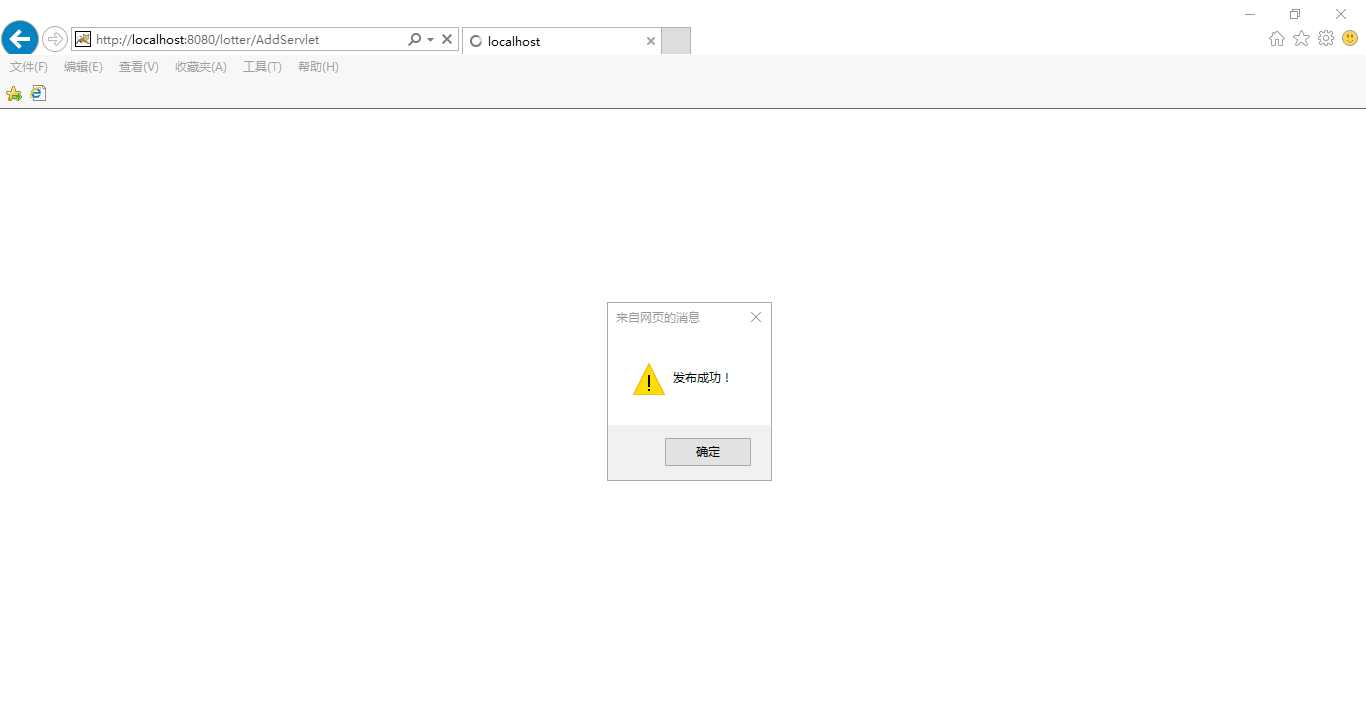
发布成功显示
本算法具有以下模式:
随机算法:
我们的抽奖算法基于LCG算法,LCG(linear congruential generator)线性同余算法,是一个古老的产生随机数的算法。
本算法有以下优点:
本算法基于的LCG算法由以下参数组成:
| 参数 | m | a | c | X |
|---|---|---|---|---|
| 性质 | 模数 | 乘数 | 加数 | 随机数 |
| 作用 | 取模 | 移位 | 偏移 | 作为结果 |
LCG算法是如下的一个递推公式,每下一个随机数是当前随机数向左移动 log2 a 位,加上一个 c,最后对 m 取余,使随机数限制在 0 ~ m-1 内
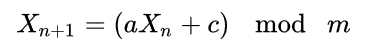
从该式可以看出,该算法由于构成简单,具有以下优点:
以下是针对不同参数 lcg 产生随机数的效果图
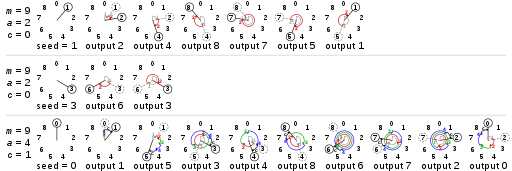
可以看出,针对不同的参数,lcg产生的效果差别很大
以下是针对不同环境下的参数选择
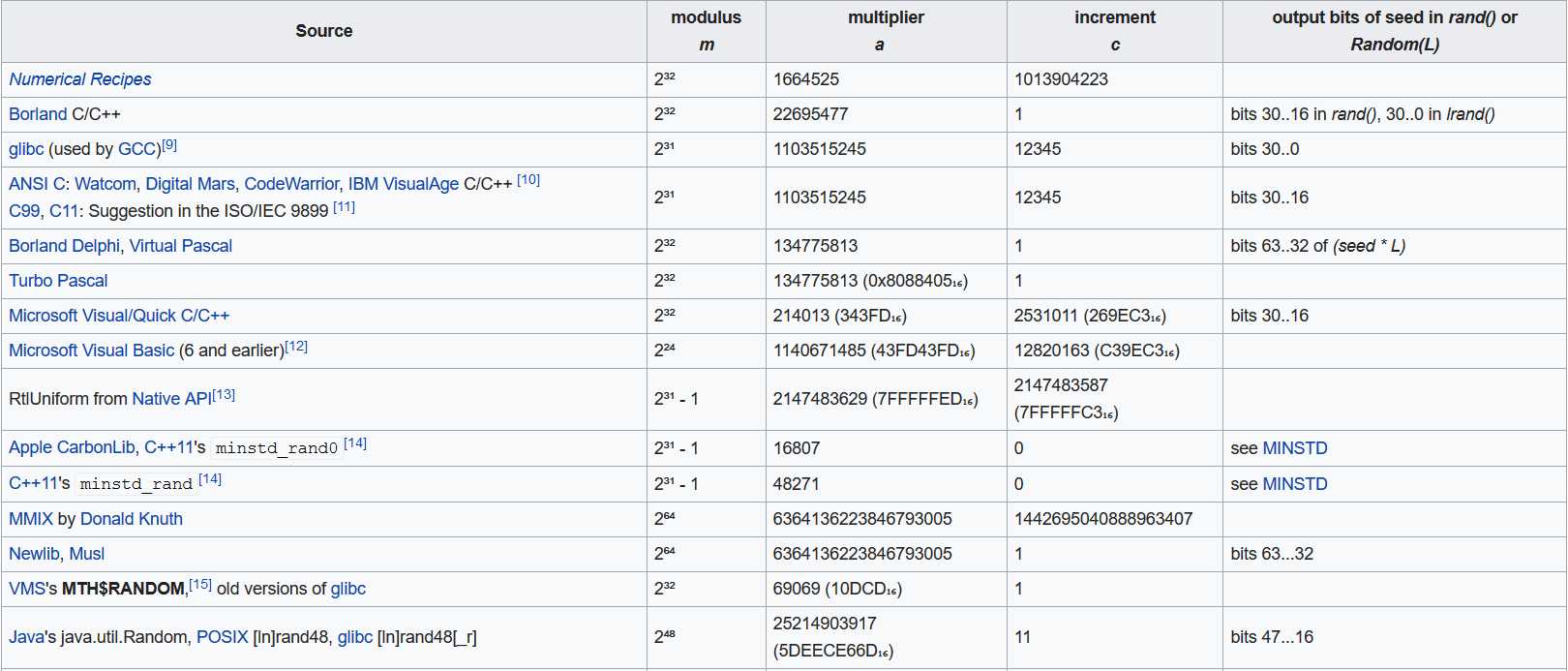
根据我们机器的情况,我们选择使用参数:
抽奖算法对两种情况进行了处理:
无发言剔除:当用户只转发抽奖关键字,而没有相关发言时,直接剔出抽奖名单。
恶意刷屏:抽奖者可以自行定义一个抽奖阈值φ1,当发言数超过φ1时,对该用户进行中奖概率降权处理。
灌水剔除:抽奖者可以自行定义一个抽奖阈值φ2,发送的表情数超过阈值的时候,判定为灌水,剔出抽奖名单
for (Map.Entry<String, Integer> en : map.entrySet()) {
//System.out.println(en.getKey() + "=" + en.getValue());
x[i] = ( a * x[i-1] + b ) % m;
if (en.getValue() < 0) { //发言为空,剔出抽奖名单
i++;
continue;
} else if (en.getValue() > 0) { //恶意刷屏,降低权重
weight = en.getValue();
if (weight > 30) {
weight = 30;
}
x[i] = (int) (x[i] * ((double)(30 - weight) / 30.0));
}
map.put(en.getKey(), x[i]);
//System.out.println(en.getKey() + "=" + en.getValue());
i++;
}
红黑树是一种自平衡的二叉查找树,是一种高效的查找树。
提供良好的效率:可在O(logN)时间内完成查找、增加、删除等操作,能保证在最坏情况下,基本的动态几何操作的时间均为O(lgn)。只要求部分地达到平衡要求,降低了对旋转的要求,任何不平衡都会在三次旋转之内解决,从而提高了效率。抽奖伏安法涉及大量增删改查操作,红黑树算法提供了良好的效率支撑。
提供性能下限保证:相比于BST,红黑树可以能确保树的最长路径不大于两倍的最短路径的长度,可见其查找效果的最低保证。最坏的情况下也可以保证O(logN)的复杂度,好于二叉查找树O(N)复杂度。在大数据量情况下,红黑树算法为抽奖算法提供良好的性能保证。
提供词频统计的高性能:红黑树的算法时间复杂度和AVL树相同,但统计性能更高。插入 AVL树和红黑树的速度取决于所插入的数据。在数据比较杂乱的情况,则红黑树的统计性能优于AVL树。在抽奖时时,数据分布较为杂乱,在此应用场景下,红黑树算法与抽奖器契合。
提供较小的资源开销:与基于哈希的算法相比,基于红黑树方法带来更小的资源开销,程序消耗内存较少。哈希的算法占用大量资源,需要维护大量的计数器,并且在哈希过程中消耗了大量的计算资源。抽奖系统器消耗的资源较少。
sketch 是一种基于散列的数据结构,可以在高速网络环境中,实时地存储流量特征信息,只占用较小的空间资源,并且具备在理论上可证明的估计精度与内存的平衡特性
原理
sketch是基于散列的数据结构,通过设置散列函数,将具有相同散列值的键值数据存入相同的桶内,以减少空间开销。桶内的数据值作为测量结果,是真实值的近似。利用开辟二维地址空间,多重散列等技术减少散列冲突,提高测量结果的准确度。Count-Min[7] 是一种典型的 sketch ,在 2004 年被提出。实际上 Count-Min sketch 用到的是分类的思想:将具有相同哈希值的网络流归为一类,并使用同一个计数器计数。
当高速网络流量到来时,逐个记录所有流量的信息,会带来巨大的计算和空间资源开销。而网络测量往往也无需记录所有的信息。
Count-Min sketch由多个哈希函数(f1……fn)和一张二维表组成。二维表的每个存储空间维护了一个计数器,其中每个哈希函数分别对应表中的每一行。当一个网络流到来时,需要经过每个哈希函数 f1……fn 的处理,根据处理得到的哈希值分别存入每一行对应哈希值的计数器。有几个哈希函数,就要计算几次。算完后,取这m个计数器中的最小值,作为测量的最终值。
设计考量
测量值偏大:使用哈希的方法会产生冲突,多个网络流数据哈希到同一个桶内,那么这个桶的计数值就会偏大。
1.为什么允许有误差:在高速网络条件下,若把所有信息都准确地记录下来,要消耗大量计算和空间开销,无法满足实时性;而且在很多情况下,并不需要非常精确的测量数据,在一定程度上可靠的估计值,便足以满足需求。
2.为什么要设置多个哈希函数:如果只设置一个哈希函数,多个流数据存入同一个桶,误差就会很大。通过设计多个哈希函数,减少哈希值的冲突,以减少误差。每个流都要经过所有哈希函数的处理,存入不同的计数器中。计数器的最小值虽然还是大于等于真实值,但最接近真实值。这也是 “ Count-Min ”的由来。
3.哈希函数个数:哈希函数越多,冲突越少,测量值越精确,但计算开销大。需要权衡测量精度和准确度,来设置合适的哈希函数个数。
困难:
解决办法
困难:alpha还在单机阶段课堂实战已经进入web,时间分配不均,分工出现混乱,作为后端负责人没有检查环境软件版本甚至不少人没有某某软件,导致不熟悉。
解决办法:冷静冷静冷静,尽量不焦虑,事情一件一件来(嗯,体会到了濒临死亡的感觉)
困难:时间太短,对代码要求很高,不允许迭代修改bug。算法全新,需要构思。附加题构思。
解决办法:考虑到前一段学习的djb2散列函数,修改使用LCG线性同余法,解决随机数的问题。考虑在实际场景下,微博转发数量太大,要进行数据挖掘等工作,需要耗费很大计算和空间资源,故使用LCG和Sketch解决。
困难:随机数生成算法需要从网上查阅很多相关资料,需要同后端使用相同的类和传参方式
困难:
1.编码方面,在其他人面前,真的是有点过于弱。
2.前端方面,浅显的还能写出来,深度一点的就会一直出bug。
3.擅长的东西过于单一,理解的知识也是过于肤浅,个人能力有待提升。
解决办法:
1.看教程,一步步来。
2.看队友操作,积累经验。
解决办法:在网上查找代码,并同其他同学交流,制定相同的传参规则
困难:前端界面太不友好,不了解代码,修改起来有难度。与后端交接时,返回值有待商榷。
解决办法:查看网上代码,下载模板进行修改。
困难:
解决办法:
困难:
解决办法
困难:对于抽奖应该如何实现没有头绪
解决办法:求助了组内的周政演和黄鸿杰同学
困难:
解决办法:
困难:对于web很么有经验,对于排版,真的难为我这个男生
解决办法:找了一个婚庆的模板套了一下,改了些字和图
由于本次现场编程开发进度低于预期,给每位同学一个一句话吐槽机会,格式为:如果……,那么……
如果能睡一个好觉,那么我会补一个月的觉
如果我有好好学搜索引擎或者好好看前端,那么这次作业大家做起来都会快很多
如果我能力强一些,那么我的团队就可以更快更完美的完成这项项目。
如果给定时间长一点或者不在考试之前发布这么复杂的问题,那么大家能更轻松愉快地完成这项任务。
如果能拿到相关教程,学习一段时间,那么我们就不会感觉很慌张
如果能重来,那么我一定要在课前学习,课上装逼。
如果能重来一次,那么我可能会选择做自闭软件或者直接自闭吧
如果我再强一些,那么我的团队就可以更开心的完成
以下部分计入个人得分:
| PSP2.1 | header 2 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | ·估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 150 | 240 |
| · Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 180 | 150 |
| · Coding | · 具体编码 | 120 | 450 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | ·测试(自我测试,修改代码,提交修改) | 0 | 0 |
| Reporting | 报告 | 10 | 10 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 600 | 950 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 15 | 15 | 学会代码质量分析 |
| 2 | 100 | 400 | 10 | 25 | Axure设计原型 |
| 3 | 500 | 900 | 15 | 50 | 学会正则表达式和NFA的应用 |
| 4 | 300 | 1200 | 15 | 65 | 学会了andorid前端页面的书写 |
| 5 | 500 | 1700 | 25 | 90 | 对前端与后端的交互有了新的了解,同时对前端的认识加深了 |
| 6 | 500 | 2200 | 38 | 108 | 学习了一定的web +java 编程 |
标签:一段 本地 长度 索引 dea com string 路径 推广
原文地址:https://www.cnblogs.com/waaaafool/p/9979236.html