标签:pen ram jks 测试 ++ 优先 大小 伪代码 ast
图 G 由两个集合 V 和 E 组成,记为:
G=(V, E) 其中: V 是顶点的有穷非空集合,
E 是 V 中顶点偶对(称为边)的有穷集。
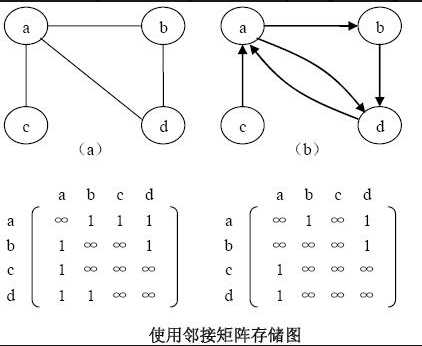
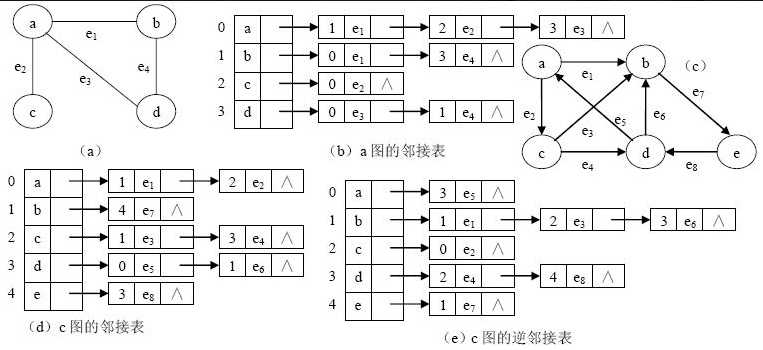
邻接矩阵储存法:采用2个数组来表示图;一个是存储所有顶点信息的一维数组(vetices[])、一个是存储图中顶点之间关联关系的二维数组(adjMatrix[][]),这个二维数组称为邻接矩阵。
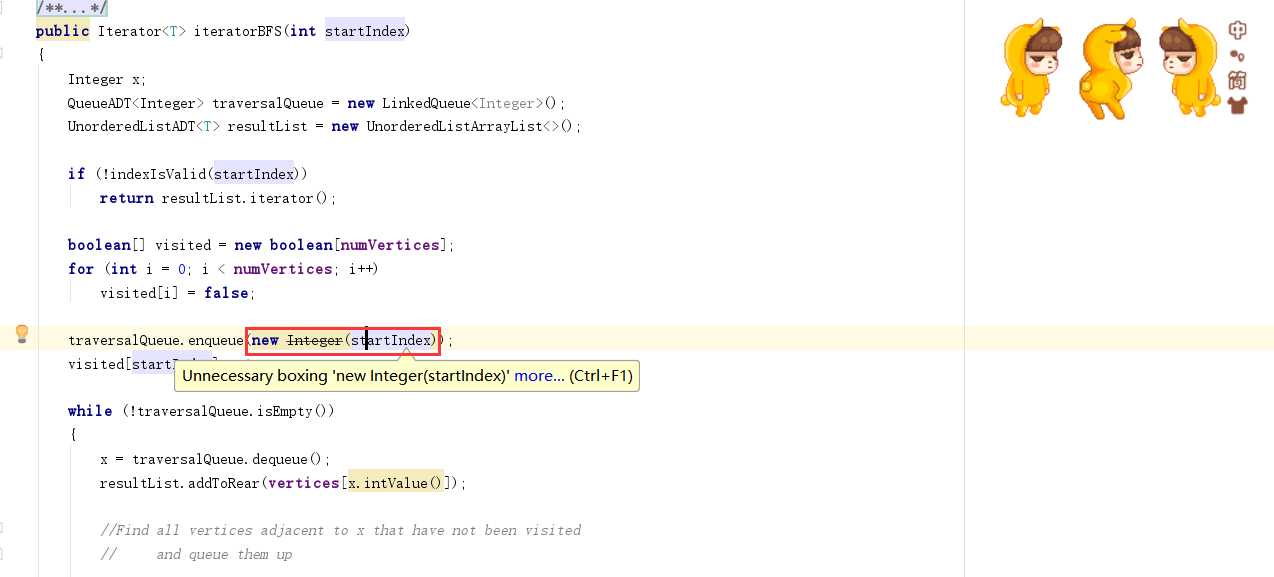
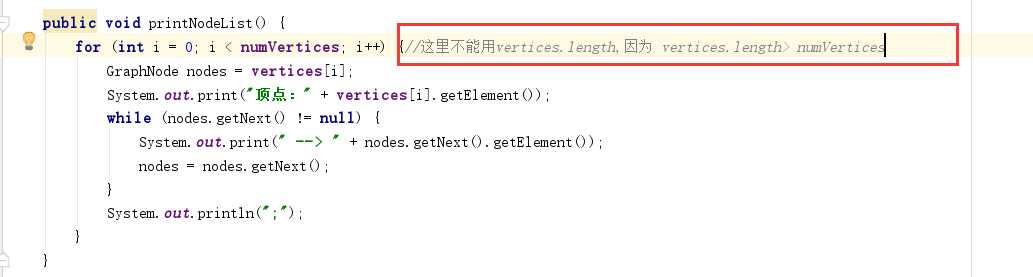
问题1:书中有关integer的代码什么意思?
问题1解决方案:如图:
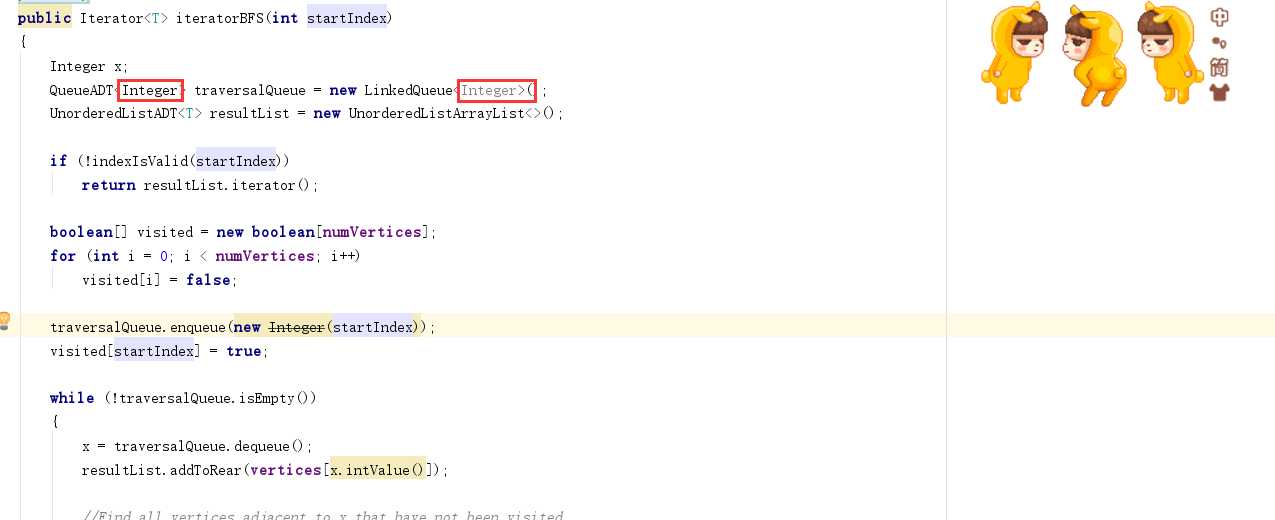
因为队列中储存的数据是Integer类型的,而numVertices是int类型的,因此应该转化为Integer型,对应的方法为:
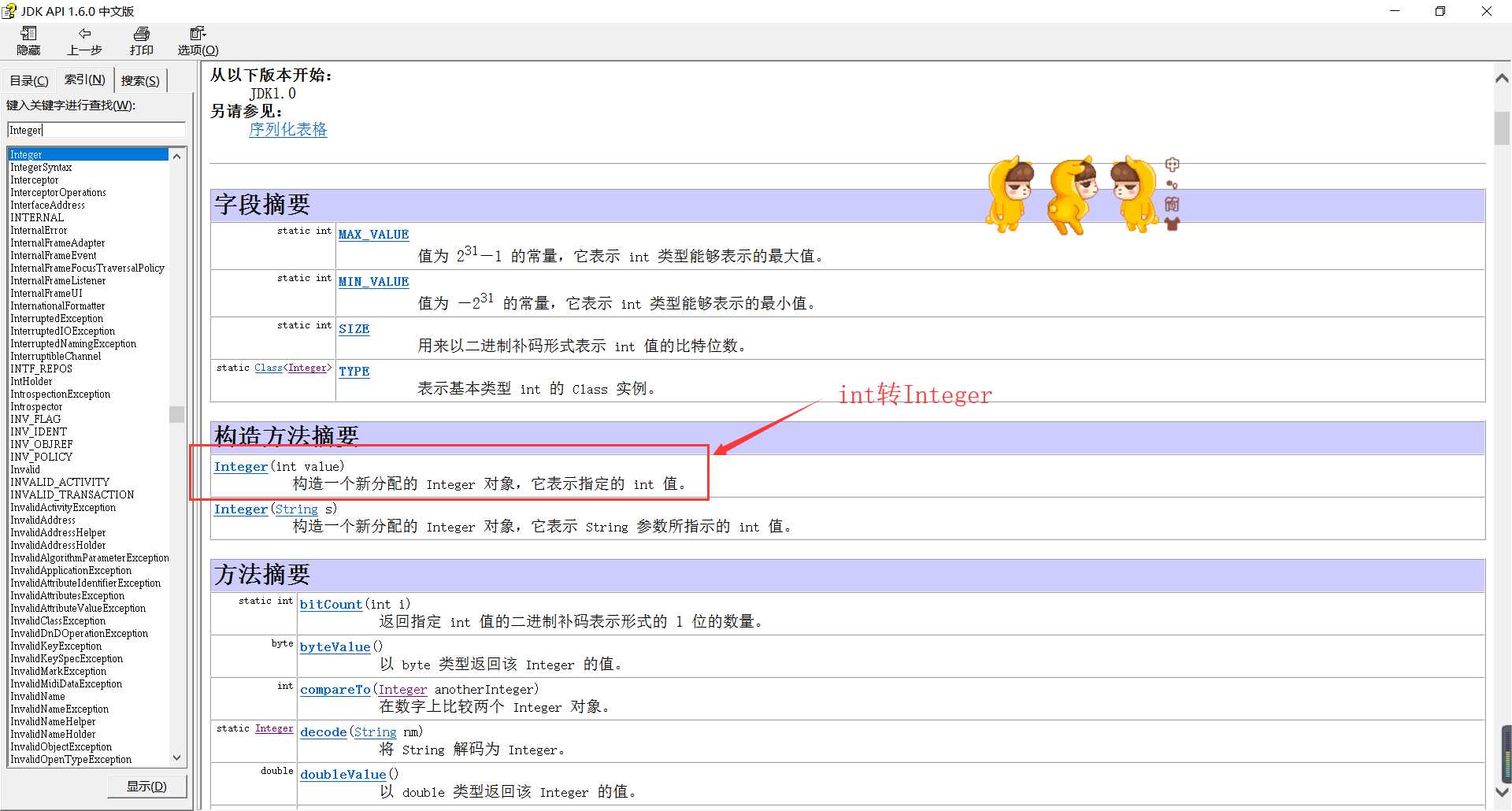
那么新的问题又来了:为什么一定要Integer,直接用int不好吗?
答案:Integer是其包装类,注意是一个类。而int 是基本数据类型.我们使用integer是为了在各种类型间转化,通过各种方法的调用。
1. 初始化队列:visited[n] = 0
2. 访问顶点:visited[v] = 1
3. 顶点v加入队列
4. 循环:
while(队列是否为空)
v = 队列头元素
w = v的第一个邻接点
while(w存在)
if(如果w未访问)
visited[w] = 1;
顶点w加入队列
w = 顶点v的下一个邻接点1. 访问数组初始化:visited[n] = 0
2. 访问顶点:visited[v] = 1
3. 取v的第一个邻接点w;
4. 循环递归:
while(w存在)
if(w未被访问过)
从顶点w出发递归执行;
w = v的下一个邻接点;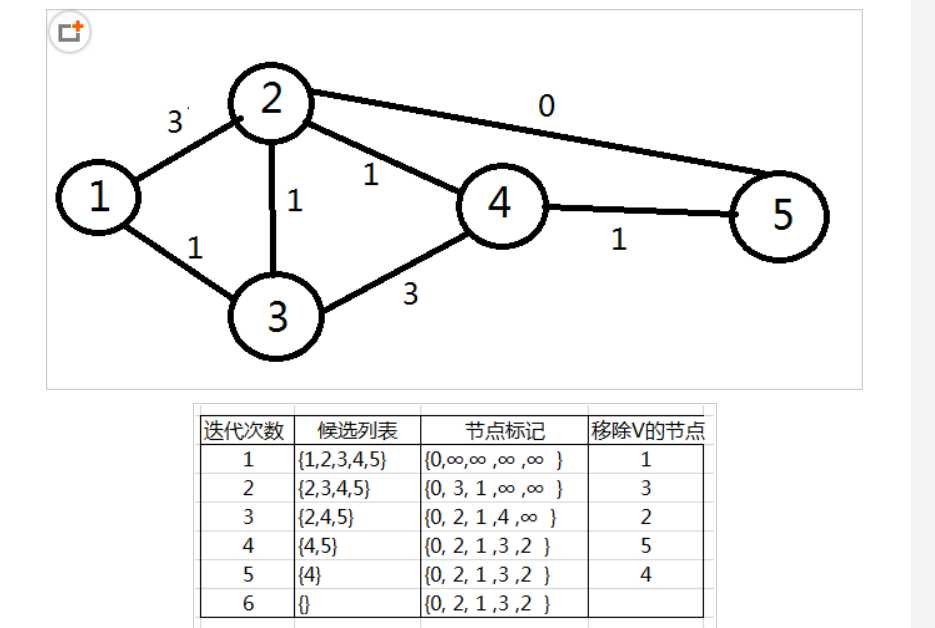
public boolean isConnected()
{
boolean result = true;
for(int i=0;i<numVertices;i++){
int temp=0;
temp=getSizeOfIterator(this.iteratorBFS(vertices[i]));
if(temp!=numVertices)
{
result = false;
break;
}
}
return result;
}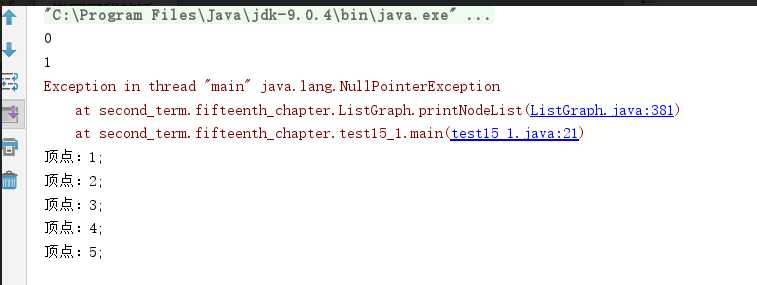
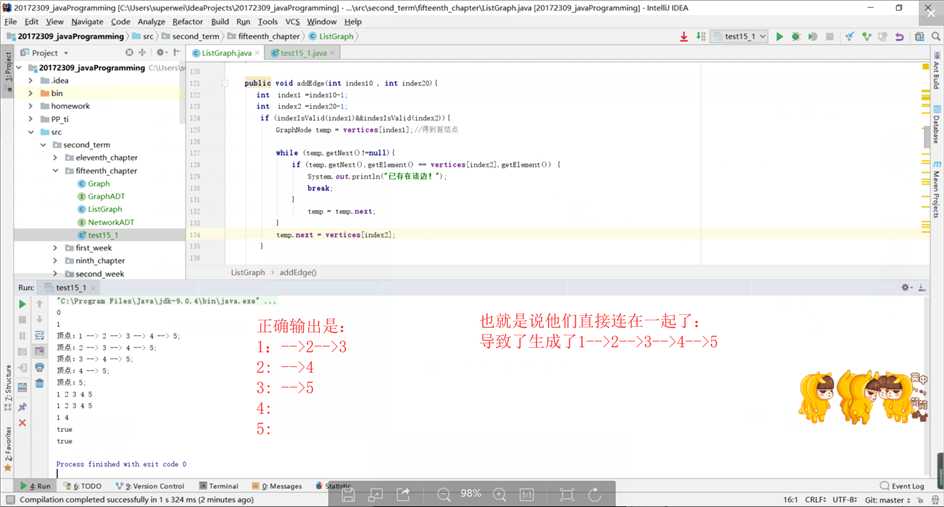
问题2解决方案:首先 肯定是 输出方法出现了问题,解决后发现应该这样:
然后出现的问题是:
经分析:肯定是哪句代码错了:导致全部连在一起了!
值得注意的是 在无向图中添加边,应该两边的联系都要考虑:
public void addEdge(int index10 , int index20){
int index1 =index10-1;
int index2 =index20-1;
if (indexIsValid(index1)&&indexIsValid(index2)){
GraphNode temp = vertices[index1];//得到首结点
while (temp.getNext()!=null){
if (temp.getNext().getElement() == vertices[index2].getElement()) {
System.out.println("已存在该边!");
break;
}
temp = temp.next;
}
temp.next = new GraphNode(vertices[index2].getElement());//有index10--》index20
GraphNode temp2 = vertices[index2];
while (temp2.getNext()!=null){
if (temp2.getNext().getElement() == vertices[index1].getElement()) {
System.out.println("已存在该边!");
break;
}
temp2 = temp2.next;
}
temp2.next = new GraphNode(vertices[index1].getElement());//有index20--》index10
}
modCount++;
}(statistics.sh脚本的运行结果截图)
Since a heap is a binary search tree, there is only one correct location for the insertion of a new node, and that is either the next open position from the left at level h or the first position on the left at level h+1 if level h is full. A .True B .Flase错误原因:堆是一棵完全二叉树、不是一颗二叉搜索树。自己瞎了眼!!!!
-
-
- 这一章内容比较简单,或者可以说书上的内容比较简单,但是实现起来很难。也可能是书上的例子比较少的原因。还有就是发现里面的几个算法是非常有意思的,比如Dijkstra算法。它能通过实际的几个数组就能找到最短路径!!!很惊讶!!!
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 260/0 | 1/1 | 05/05 | |
| 第二周 | 300/560 | 1/2 | 13/18 | |
| 第三周 | 212/772 | 1/4 | 21/39 | |
| 第四周 | 330/1112 | 2/7 | 21/60 | |
| 第五周 | 1321/2433 | 1/8 | 30/90 | |
| 第六周 | 1024/3457 | 1/9 | 20/110 | |
| 第七周 | 1024/3457 | 1/9 | 20/130 | |
| 第八周 | 643/4100 | 2/11 | 30/170 |
2017-2018-20172309 《程序设计与数据结构》第九周学习总结
标签:pen ram jks 测试 ++ 优先 大小 伪代码 ast
原文地址:https://www.cnblogs.com/dky-wzw/p/9979551.html