标签:投票 ima 观察 接受 相关 算法 leader 之间 进程
分布式系统的很多难题,都是由于缺少协调机制造成的。在分布式协调这块做得比较好的,有 Google 的 Chubby 以及 Apache 的 Zookeeper。Google Chubby 是一个分布式锁服务,通过 Google Chubby 来解决分布式协作、Master 选举等与分布式锁服务相关的问题。
Zookeeper 也是类似,因为当时在雅虎内部的很多系统都需要依赖一个系统来进行分布式协调,但是谷歌的Chubby是不开源的,所以后来雅虎基于 Chubby 的思想开发了 zookeeper,并捐赠给了 Apache。
zookeeper是一个精简的文件系统。这点它和hadoop有点像,但是zookeeper这个文件系统是管理小文件的,而hadoop是管理超大文件的。
zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布式队列、分布式锁以及一组同级节点的“领导者选举”算法。
zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题。
zookeeper采用了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制,让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系。
zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度。
zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
1. 防止单点故障
如果要防止 zookeeper 这个中间件的单点故障,那就势必要做集群。而且这个集群如果要满足高性能要求的话,还得是一个高性能高可用的集群。高性能意味着这个集群能够分担客户端的请求流量,高可用意味着集群中的某一个节点宕机以后,不影响整个集群的数据和继续提供服务的可能性。结论: 所以这个中间件需要考虑到集群,而且这个集群还需要分摊客户端的请求流量,实现服务的高性能。
2. 接着上面那个结论再来思考,如果要满足这样的一个高性能集群,我们最直观的想法应该是,每个节点都能接收到请求,并且每个节点的数据都必须要保持一致。要实现各个节点的数据一致性,就势必要一个 leader 节点负责协调和数据同步操作。这个我想大家都知道,如果在这样一个集群中没有 leader 节点,每个节点都可以接收所有请求,那么这个集群的数据同步的复杂度是非常大。结论:所以这个集群中涉及到数据同步以及会存在leader 节点
3.继续思考,如何在这些节点中选举出 leader 节点,以及leader 挂了以后,如何恢复呢?结论:所以 zookeeper 用了基于 paxos 理论所衍生出来的 ZAB 协议
.4. leader 节点如何和其他节点保证数据一致性,并且要求是强一致的。在分布式系统中,每一个机器节点虽然都能够明确知道自己进行的事务操作过程是成功和失败,但是却无法直接获取其他分布式节点的操作结果。所以当一个事务操作涉及到跨节点的时候,就需要用到分布式事务,分布式事务的数据一致性协议有 2PC 协议和3PC 协议。
Leader 角色:Leader 服务器是整个 zookeeper 集群的核心,主要的工作任务有两项1. 事务请求的唯一调度和处理者,保证集群事物处理的顺序性2. 集群内部各服务器的调度者
Follower 角色:Follower 角色的主要职责是1. 处理客户端非事务请求、转发事务请求给 leader 服务器2. 参与事物请求 Proposal 的投票(需要半数以上服务器通过才能通知 leader commit 数据; Leader 发起的提案,要求 Follower 投票)3. 参与 Leader 选举的投票
Observer 角色:Observer 是 zookeeper3.3 开始引入的一个全新的服务器角色,从字面来理解,该角色充当了观察者的角色。观察 zookeeper 集群中的最新状态变化并将这些状态变化同步到 observer 服务器上。Observer 的工作原理与follower 角色基本一致,而它和 follower 角色唯一的不同在于 observer 不参与任何形式的投票,包括事务请求Proposal的投票和leader选举的投票。简单来说,observer服务器只提供非事务请求服务,通常在于不影响集群事物处理能力的前提下提升集群非事务处理的能力
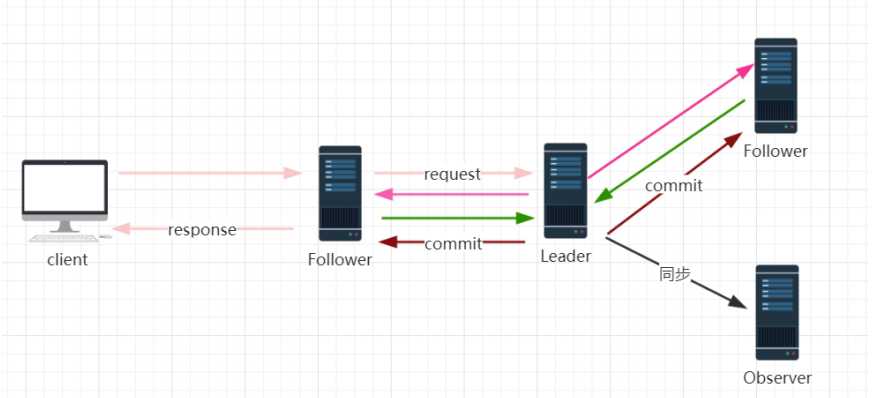
如上图,在 zookeeper 中,客户端会随机连接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据,如果是写请求,那么请求会被转发给 leader 提交事务,然后 leader 会广播事务,只要有超过半数节点写入成功,那么写请求就会被提交(类 2PC 事务)
所有事务请求必须由一个全局唯一的服务器来协调处理,这个服务器就是 Leader 服务器,其他的服务器就是follower。leader 服务器把客户端的失去请求转化成一个事务 Proposal(提议),并把这个 Proposal 分发给集群中的所有 Follower 服务器。之后 Leader 服务器需要等待所有Follower 服务器的反馈,一旦超过半数的 Follower 服务器进行了正确的反馈,那么 Leader 就会再次向所有的Follower 服务器发送 Commit 消息,要求各个 follower 节点对前面的一个 Proposal 进行提交;
标签:投票 ima 观察 接受 相关 算法 leader 之间 进程
原文地址:https://www.cnblogs.com/wuzhenzhao/p/9983231.html