标签:class apt cap end append fir file attr col
模块化:
登录模块文件名:publiclogin.py
# coding=utf-8 #登录模块 def login(dr): dr.find_element_by_id(‘login-username‘).send_keys(‘username‘) dr.find_element_by_id(‘login-passwd‘).send_keys(‘password‘)
# coding=utf-8 from selenium import webdriver from publiclogin import login #调用publiclogin文件 dr = webdriver.Firefox() dr.get("https://passport.bilibili.com/login") login(dr) #调用登录模块,传入驱动参数 #其他测试内容
读取TXT文件
读取行数据:
读取整个文件:read()
读取一行数据:readline()
读取所有行数据:readlines()
txt文件如下:
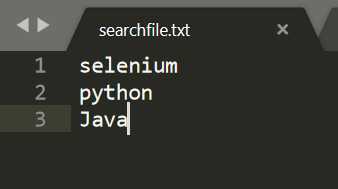
用open打开文件之后,要用close关闭文件
# coding=utf-8 from selenium import webdriver from time import sleep from publiclogin import login #调用publiclogin文件 search = open("searchfile.txt","r") #打开文件,只读 values = search.readlines() #逐行读取 search.close() #用open打开文件之后,要用close关闭文件 for searchword in values: dr = webdriver.Firefox() dr.get("https://baidu.com") dr.find_element_by_id(‘kw‘).send_keys(searchword) dr.find_element_by_id(‘su‘).click() sleep(1) dr.quit()
对TXT文件的一行数据进行拆分:
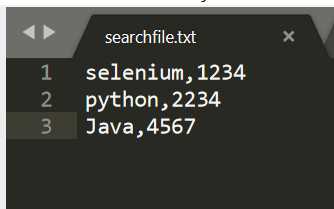
# coding=utf-8 from selenium import webdriver from time import sleep from publiclogin import login #调用publiclogin文件 search = open("searchfile.txt","r") #打开文件,只读 values = search.readlines() #逐一读取所有行 search.close() for searchword in values: username=searchword.split(‘,‘)[0] #按逗号分隔,并取第一个数组 print username password=searchword.split(‘,‘)[1] #按逗号分隔,并取第二个数组 print password
读取CSV文件
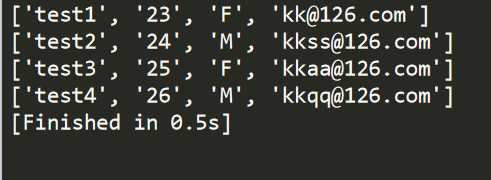
创建一个excel文件,并另存为CSV格式
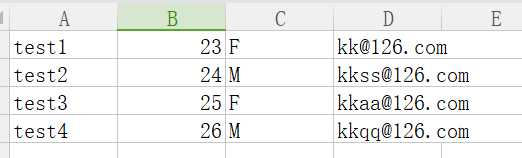
import csv #读取data目录内的CSV文件 cust_info = csv.reader(open(‘./data/custinfo.csv‘,‘r‘)) for customer in cust_info: print customer
读取XML文件
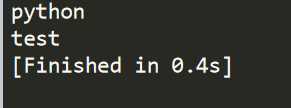
xml文件如下:
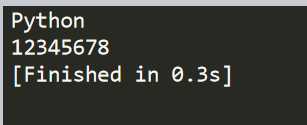
<?xml version="1.0" encoding="utf-8"?> <catalog> <maxid>10</maxid> <login username=‘Python‘ passwd=‘12345678‘> <caption>python</caption> <item id=‘4‘> <caption>test</caption> </item> </login> <item id=‘2‘> <caption>test2</caption> </item> </catalog>
读取标签内的数据:
# coding=utf-8 import xml.dom.minidom #引入xml文件 dom = xml.dom.minidom.parse(‘C:/Users/user/Desktop/python_study/script/data/userlogin.xml‘) root = dom.documentElement logins = root.getElementsByTagName(‘login‘) #注意elements有s username = logins[0].getAttribute(‘username‘) #logins[0]表示第一个login标签,getattribute获取username属性 print username password = logins[0].getAttribute(‘passwd‘) print password
读取标签对件的数据:
import xml.dom.minidom #读取当前目录下data文件夹内的XML文件 dom = xml.dom.minidom.parse(‘userlogin.xml‘) root = dom.documentElement captions = root.getElementsByTagName(‘caption‘) #注意elements有s c1=captions[0].firstChild.data #获取第一个caption标签对间的数据 print c1 c2=captions[1].firstChild.data #获取第二个caption标签对间的数据 print c2
模块化和数据驱动综合案例:
# coding=utf-8 from selenium import webdriverimport sys #跨目录获取文件 sys.path.append(‘./public‘) from public import publiclogin dr = webdriver.Firefox() dr.get("https://passport.bilibili.com/login") publiclogin.login(dr) #调用登录模块,指定文件,传入驱动参数
#其他功能测试
dr.quit()
Python读取文件顺序为当前目录—>python安装目录—>环境变量
publiclogin文件存放在public文件夹内,不是当前目录,也不再安装目录下,不能直接获取到
如果每次都要添加环境比较麻烦,为方便使用,可以调用import sys
public文件内需要有__init__.py文件,不然无法识别该文件夹内的文件
__init__.py文件文件为空时,写法如上;如果在__init__.py文件内import publiclogin,可写为 from public import *
登录模块:
# coding=utf-8 import xml.dom.minidom #引入xml文件 dom = xml.dom.minidom.parse(‘C:/Users/user/Desktop/python_study/script/data/userlogin.xml‘) root = dom.documentElement logins = root.getElementsByTagName(‘login‘) #注意elements有s username = logins[0].getAttribute(‘username‘) #获取username password = logins[0].getAttribute(‘passwd‘) #获取password#登录模块 def login(dr): dr.find_element_by_id(‘login-username‘).send_keys(username) #传入username dr.find_element_by_id(‘login-passwd‘).send_keys(password) #传入password
xml文件数据:
<?xml version="1.0" encoding="utf-8"?> <catalog> <maxid>10</maxid> <login username=‘testusername‘ passwd=‘testpassword‘> <caption>python</caption> <item id=‘4‘> <caption>test</caption> </item> </login> <item id=‘2‘> <caption>test2</caption> </item> </catalog>
标签:class apt cap end append fir file attr col
原文地址:https://www.cnblogs.com/hlbzzt/p/9960640.html