标签:class ann 就是 item 集成 源码解读 ssl 检测 not
ssd是经典的one-stage目标检测算法,作者是基于caffe来实现的,这需要加入新的层来完成功能,caffe自定义层可以使用python和c++,faster rcnn既使用了c++定义如smoothl1layer,又使用了python定义,如proposaltargetlayer、roidatalayer等。而ssd完全使用c++来定义层,包括:
1)annotateddatalayer数据读取层,用于读取图像和标签数据,并且支持数据增强
2)permutelayer用于改变blob的读取顺序
3)priorboxlayer用于生成defalutbox
4)multiboxlosslayer,边框回归集成了l2loss、smoothl1,于分类集成了softmax和logistic,并且支持困难样本挖掘、defaultbox匹配等功能。
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
整个网络比较繁杂,不过相对于fasterrcnn算简单一些,我们从loss顺藤摸瓜,首先查看label的存储格式,这需要查看annotateddatalayer层是如何对数据进行读取的,查看网络定义文件发现数据读取层的输入要求是lmdb或leveldb格式,那么问题来了,如何将voc格式的数据制作成lmdb呢?原生caffe好像只支持分类的数据制作,github上说通过./data/VOC0712/create_list.sh和./data/VOC0712/create_data.sh来制作数据,查看create_data.sh文件,里面又调用了$root_dir/scripts/create_annoset.py,继续查看create_annoset.py 发现最终调用的是/build/tools/convert_annoset进而查看tools/convert_annoset.cpp,里面实现了将分散的文件转换为lmdb格式,但是依然还没找到哪里解析了voc格式标注的xml文件,convert_annoset.cpp调用了ReadRichImageToAnnotatedDatum函数,终于在utils/io.cpp中找到了读取xml标注文件的实现。数据层的输出有data和label,data的格式是n×3×300×300,而label的格式是n*1×nofboxes*8。每个物体包含了8个信息[item_id, group_label, instance_id, xmin, ymin, xmax, ymax, diff]
,含义是batchsize个图像中的第item_id幅图像中的第group_label个类别下的第instance_id个目标的坐标为[xmin, ymin, xmax, ymax]。
loss层的label输入格式清楚了,接下来解析mbox_priorbox的格式,mbox_priorbox是由多个priorbox层concat起来的,ssd300在6个featuremap上生成了priorbox,例如在conv4_3的featuremap上的priorbox数量为w×h×numprior,其存储方式为chw,维度为2×1*(w×h×numprior*4),可以看出是3维的,而不是nchw,这是因为一个batch的图像大小是相同的,为它们生成的priorbox也是完全相同的,所以不需要batch这个维度,另外注意channel维度是2,是存入了对应位置的方差varirance。多层的priorbox数据concat起来时,axis设为2,也就是在w的维度将bloob接起来形成一个如图所示长条。
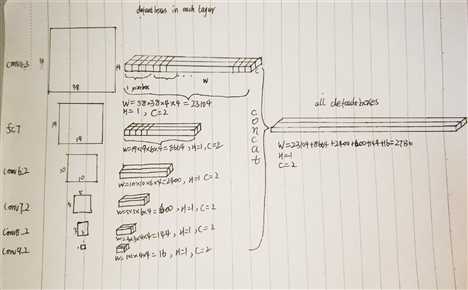
接着解析mbox_loc的维度,以大小为38×38的conv4_3的fmap为例,3*3的卷积在fmap上卷积得到bsize×16×38×38的map,注意通道数量是16,在38*38的空间位置上,每个空间位置对应16个数,而这16个数就是对4个priorbox也就是16个点的回归,但是麻烦的是priorbox是被拉成了1维向量(不考虑variance的话),暂时不考虑bsize的话,那如何将16×38×38的blob拉成与priorbox对应的1维向量呢?直接flatten的话将按照whc从低到高的顺序flatten,这是不行的,需要按照cwh的顺序flatten才能与priorbox的存储方式对应得上,于是ssd定义了permutelayer将blob的nchw顺序改为nhwc,然后进行flatten即可。这里需要注意flatten的用法,文件指定从1号axis开始flatten,也就是从permute过后hwc维flatten成1维,整体flatten过后的维度为n×(h*w*c)在conv4也就是bsize×23104,四维blob变成了2维,如果对flatten有疑惑可直接查看源码。各层的二维blob再继续concat,第1维是bsize,那么肯定在第2维上进行concat,所以mbox_loc和mbox_conf层拼接的axis都设为1。所以mbox_loc层blob的维度最终为bsize×27130。
mbox_conf层的维度与mbox_loc层维度的推算类似,3*3的卷积在fmap上卷积得到bsize×84×38×38的map,其中84=4×21,4是每个位置4个不同的priorbox,21代表了卷积网络预测出该priorbox属于21类的概率。后续计算方式参考mbox_loc即可。

标签:class ann 就是 item 集成 源码解读 ssl 检测 not
原文地址:https://www.cnblogs.com/anti-tao/p/9991334.html