标签:style blog http color os ar strong 数据 sp
1、离散随机分布
超几何分布:M:产品总数;K:次品数;N:抽样数。
hygepdf(X, M,K,N):计算超几何分布的密度。
例:hygepdf(1,10,1,3),执行结果为ans=0.3000
表示参数为10,、1和3的超几何分布在数值1处的密度为0.3。
例:hygepdf([1,0],10,1,3),执行结果为ans=0.3000 0.7000
第一个分量是超几何分布在数值1处的密度,第二个分量是该分布在数值0处的密度。
hygecdf(Y,M,K,N):计算超几何分布的累积分布函数值
例:hygepdf(2,100,20,10),执行结果为ans=0.6182
表示次品数0-2个的累积值。
hygernd(M,K,N):产生服从超几何分布的随机数。
例:见Hygernd.m
?
二项分布(伯努利Bernulli分布):N:实验总次数;P:实验成功概率
binopdf(X,N,P):计算二项式分布的密度,即在取X值时的密度。
binocdf(Y,N,P):计算二项式分布的累积分布函数值。
binornd(N,P):生成二项式分布的随机数。
例:见Binornd.m
?
泊松分布(Poisson):lambda:泊松参数λ。
poisspdf (X,lambda):计算泊松分布的密度。
poisscdf (Y,lambda):计算泊松分布的累积分布函数值。
poissrnd (lambda):生成泊松分布的随机数。
例:见Poissrnd.m
?
几何分布:X:首次成功时的实验次数;P:概率
?
2、连续型随机分布
均匀分布:区间[A,B]
unifpdf(X,A,B):计算均匀分布的密度。
unifcdf(Y,A,B):计算均匀分布的累积分布函数值。
unifrnd(A,B):生成均匀分布的随机数。
例:见Unifrnd.m
?
指数分布:分布参数为λ,mu:分布的期望。mu=1/λ。
?
正态分布(高斯Gauss分布):分布参数为mu=μ,sigma=σ。
normpdf(X,mu,sigma):计算正态分布的密度。
normcdf(Y,mu, sigma):计算正态分布的累积分布函数值。
例:见Normpdfcdf.m
norminv(P,mu,sigma):计算正态分布的逆累积分布函数值。P为正态分布概率值。
例:x = norminv([0.025 0.975],0,1)
x = -1.9600 1.9600
第一分量表示累积概率为0.025的值,返回值为a,满足F(a)=P(x<a)。
第二分量表示累积概率为0.975的值。
normrnd(mu,sigma):生成正态分布的随机数。
例:见Normrnd.m
mvnpdf(xy,mu,sigma):多维高斯密度函数。
mvnrnd(mu1,sigma2,n):产生多维正态随机数,mu1为期望向量,sigma2为协方差矩阵,n为规模。
?
rand,randn
lognrnd(mu,sigma):生成服从对数正态分布的随机数。
chi2rnd(v):生成服从自由度为v的卡方分布的随机数。
frnd(v1,v2):生成服从参数(v1,v2)的F分布的随机数。
trnd(v):生成服从参数为v的t分布的随机数。
betarnd(A,B):生成服从参数为A,B的beta分布的随机数。
gamrnd(A,B):生成服从参数为A,B的gamma分布的随机数。
raylrnd(B):生成服从参数为B的瑞利(Rayleigh)分布的随机数。
wblrnd(A,B):生成服从参数为A,B的威布尔(Weibull)分布的随机数。
?
3、随机变量的数字特征
mean:均值(期望);geomean:几何平均;harmmean:调和平均;
trimmean(X,percnt):修剪平均。修整方式是去掉向量X中最大和最小的各0.5*percent% 个数据。
std(A,FLAG,dim):计算标准差。A:A只有一行,则输出一行的标准差,如果是矩阵,则输出每一列的标准差。FLAG:表示标注公差时是要除以n(FLAG=0)还是n-1(FLAG=1)。dim:表示维数,等于1时则按列分,等于2时则按行分,等于3时则按第三维分。
默认std为std(A,0,1)。
var(A ,FLAG,dim):计算方差。
cov(X,Y):输出协方差矩阵。
corrcoef(X,Y):输出相关系数矩阵。
?
[m,v]=binostat(N,P):计算二项分布的期望和方差。
[m,v]=expstat(mu):计算指数分布的期望和方差。
[m,v]=normstat(mu,sigma):计算正态分布的期望和方差。
[m,v]=poisstat(lambda):计算泊松分布的期望和方差。
[m,v]=wblstat(A,B):计算威布尔分布的期望和方差。
?
4、统计作图
scatter/scatter3:绘制离散点图,可对散点单独设置;
plot:绘制线图、散点图。
tabulate(A):输出正整数的频率表。其中A中元素需为正整数。
[h,stats] = cdfplot(X):绘制经验分布函数图像。输入的为样本数据向量X。输出图形句柄h。以及重要的统计量:样本最小值(stats.min)、样本最大值(stats.max)、样本均值(stats.mean)、样本中值(stats.median)、样本标准差(stats.std)。
lsline:最小二乘拟合直线。h=
lsline为直线的句柄(用来设置图形的颜色等参数)。
normplot(X):显示正态分布概率图。若X为矩阵,则显示每一列的正态分布概率图形。样本数据在图中用"+"显示;如果数据来自正态分布,则图形显示为直线,而其它分布可能在图中产生弯曲。h=normplot(X):绘图直线的句柄。
weibplot(X);显示威布尔概率图形,同上述正态分布语句。
refline(slope,intercept) :在当前图形中加一条参考线。slope:直线斜率,intercept:截距。
refcurve(p):在当前图形中加一条多项式曲线。多项式系数p=[p1,p2,…,pn]。
p = capaplot(data,specs) :输出样本概率图形、概率p。data:所给样本数据,specs:指定范围,p:在指定范围内的概率。
ceil(A):输出A中每个元素向离它最近的大整数圆整。如-1.9取-1;1.1取2。
[ni,ak]=hist(data,k):输出各组数据频率ni,数据组的区间位置值(组中值)ak。输入k为小组个数。当无参数输出时,则直接输出直方图。
histfit(data):附加有有正态密度曲线的直方图,输出直方图。
histfit(data,nbins):输出直方图,nibin为指定的直方个数。
例:Histfit.m
moni.m
p=normspec(specs,mu,sigma):输出在指定界线之间画正态密度曲线、概率。specs:指定界线,mu,sigma:正态分布的参数,p?:样本落在上,下界之间的概率。
gscatter(x,y,g,‘clr‘,‘sym‘,siz,‘doleg‘):散度图,h=gscatter为图形中直线的句柄。x,y是具有相同大小的向量,g是组的标记,‘clr‘,‘sym‘是绘图的颜色和符号,siz是大小的向量,‘doleg‘控制是否显示图的标记。
boxplot:产生样本数据盒图。
盒图是由五个数值点组成:最小值(min),下四分位数(Q1),中位数(median),上四分位数(Q3),最大值(max)。也可以往盒图里面加入平均值(mean)。如图。下四分位数、中位数、上四分位数组成一个"带有隔间的盒子"。上四分位数到最大值之间建立一条延伸线,这个延伸线成为"胡须(whisker)"。
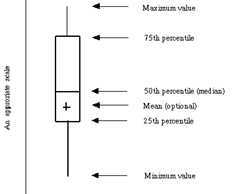
boxplot(X) :产生矩阵X的每一列的盒图和"须"图。
boxplot(X,notch) :当notch=1时,产生一凹盒图,notch=0时产生一矩箱图。
boxplot(X,notch,‘sym‘) :sym表示图形符号,默认值为"+"。
boxplot(X,notch,‘sym‘,vert):当vert=0时,生成水平盒图,vert=1时,生成竖直盒图(默认值vert=1)。
boxplot(X,notch,‘sym‘,vert,whis) :whis定义"须"图的长度,默认值为1.5,若whis=0则boxplot函数通过绘制sym符号图来显示盒外的所有数据值。
例:Boxplot.m
?
Matlab 数理统计
标签:style blog http color os ar strong 数据 sp
原文地址:http://www.cnblogs.com/lingsui/p/4021249.html