标签:streaming line 基本功 first 交互式 OLE 解决方案 方案 恢复
Spark起源于加州大学伯克利分校RAD实验室,起初旨在解决MapReduce在迭代计算和交互计算中的效率低下问题.目前Spark已经发展成集离线计算,交互式计算,流计算,图计算,机器学习等模块于一体的通用大数据解决方案.
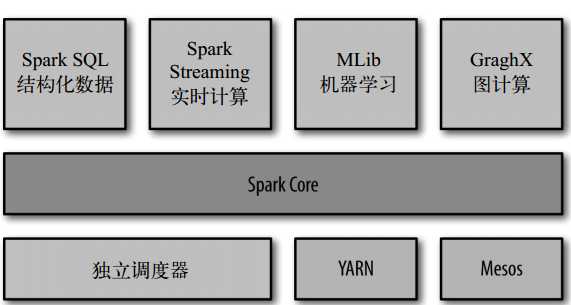
Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统
交互等模块。
Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简
称 RDD)定义。
SparkSQL是对计算任务的SQL化封装,类似于Hive.
支持多种数据源,如Hive,Json等.
Spark Streaming是Spark的流式计算组件.
支持三种调度器,独立调度器(Spark自带)YARN,Mesos.
启动HDFS,启动Spark
进入shell
bin/spark-shell
bin/pyspark(Python版)
scala> var lines = sc.textFile("/test/hello.txt")
lines: org.apache.spark.rdd.RDD[String] = /test/hello.txt MapPartitionsRDD[5] at textFile at <console>:24
scala> lines.count()
res3: Long = 3
scala> lines.first()
res4: String = hello Spark!标签:streaming line 基本功 first 交互式 OLE 解决方案 方案 恢复
原文地址:https://www.cnblogs.com/guan-li/p/9993154.html