今年工作的一个重点是“新技术新模式”的导入和研究。Elasticsearch技术比较火,各项目和产品用的都也比较多。其中某团队遇到一个问题:“在TB级的数据量下进行全文检索时,ES集群检索响应速度比较慢”。虽然由于各种原因没有接触到系统,没有看到代码,甚至都没见到具体现象,但是任务分配下来了,就要有结果就要出方案。“没吃过猪肉,也得先见见猪跑”,先在一个30GB级别的ES集群下做一下优化研究。
字符过滤器(char filters)
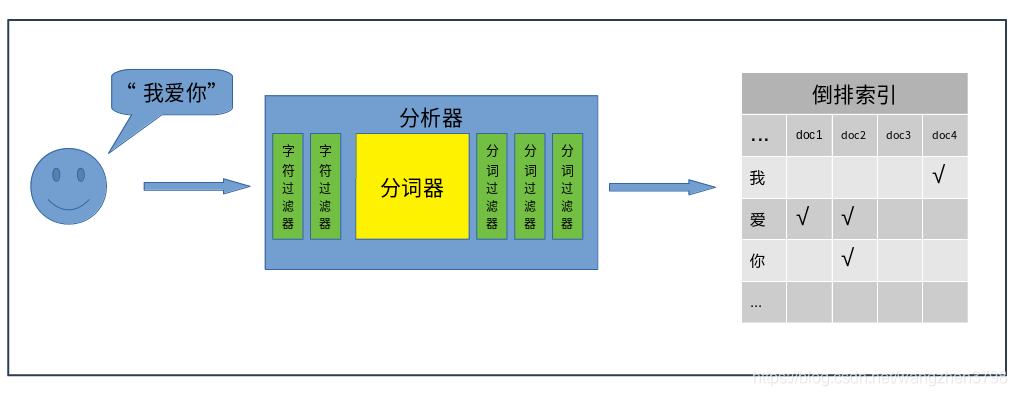
主要职责是在分词器前过滤字符流,在源字符流中添加、删除、替换字符。一个分析器中可以有0个或多个字符过滤器。主要包括:html char filter、mapping char filter等。
分词器
主要职责是将接收到的字符流,按照某些规则切分成若干个“词”,并记录这些“词”在源字符串中的位置。比如将“我爱你”切分成"我"、“爱”、“你”、“我爱”,“爱你”,“我爱你”等等。分析器中有且只能有一个分词器。
分词过滤器
主要职责是将分好的“词”进行某种规则的过滤,可以添加、移除、替换“词”,但是不能修改“词”在源字符串中的相对位置。一个分析器中可以有0个或多个分词过滤器。常用的分词过滤器包括:大小写转换过滤器、停用词过滤器、同义词过滤器、拼音过滤器 等等
一个分析器可以有字符过滤器、分词器、分词过滤器自由组合,形成新的自定义的分析器。
推理总结
原文地址:https://www.cnblogs.com/wangzhen3798/p/9996906.html