标签:path 内容 复制 over 卸载 文件中 log cga 元数据
一、Hadoop HA 机制的学习
1.1、Hadoop 2.X 的架构图
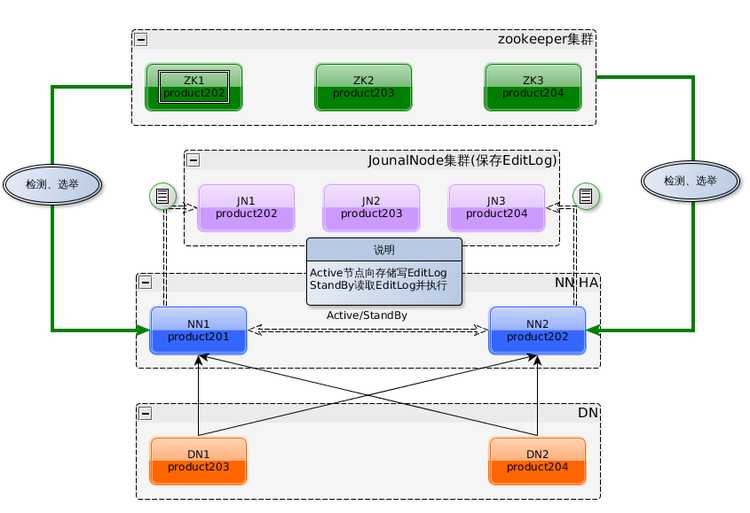
2.x版本中,HDFS架构解决了单点故障问题,即引入双NameNode架构,同时借助共享存储系统来进行元数据的同步,共享存储系统类型一般有几类,如:Shared NAS+NFS、BookKeeper、BackupNode 和 Quorum Journal Manager(QJM),上图中用的是QJM作为共享存储组件,通过搭建奇数结点的JournalNode实现主备NameNode元数据操作信息同步。
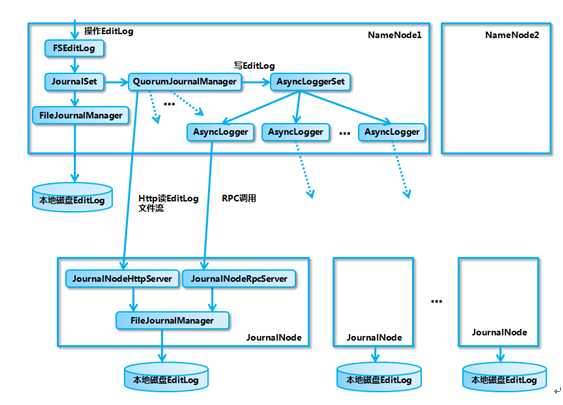
1.2、QJM原理
QJM全称是Quorum Journal Manager, 由JournalNode(JN)组成,一般是奇数点结点组成。每个JournalNode对外有一个简易的RPC接口,以供NameNode读写EditLog到JN本地磁盘。当写EditLog时,NameNode会同时向所有JournalNode并行写文件,只要有N/2+1结点写成功则认为此次写操作成功,遵循Paxos协议。其内部实现框架如下:
1.3、主备切换机制
要完成HA,除了元数据同步外,还得有一个完备的主备切换机制,Hadoop的主备选举依赖于ZooKeeper。下面是主备切换的状态图:
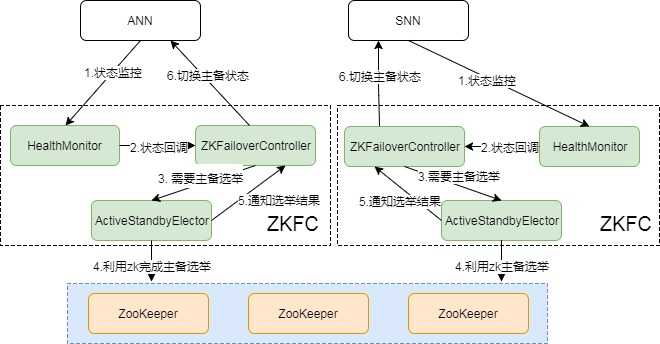
上面介绍了下关于HadoopHA机制,归纳起来主要是两块:元数据同步和主备选举。元数据同步依赖于QJM共享存储,主备选举依赖于ZKFC和Zookeeper。整个过程还是比较复杂的,如果能理解Paxos协议,那也能更好的理解这个。
详细请参考:https://www.cnblogs.com/qcloud1001/p/7693476.html
二、hadoop2.8.5 的HA 集群搭建准备
2.1、集群搭建准备
这里使用的是: CentOS7.0 VMware Workstation 14 SecureCRT连接工具
Hadoop-2.8.5 jdk-1.8.0_191 zookeeper-3.4.6
apache全系列资源官网下载:http://mirror.bit.edu.cn/apache/
2.2、虚拟机设置
打开VMware Workstation 14 通过ALT+E+N打开虚拟网络编辑器
以下1、2、3 需要记录,需要在虚拟机中配置
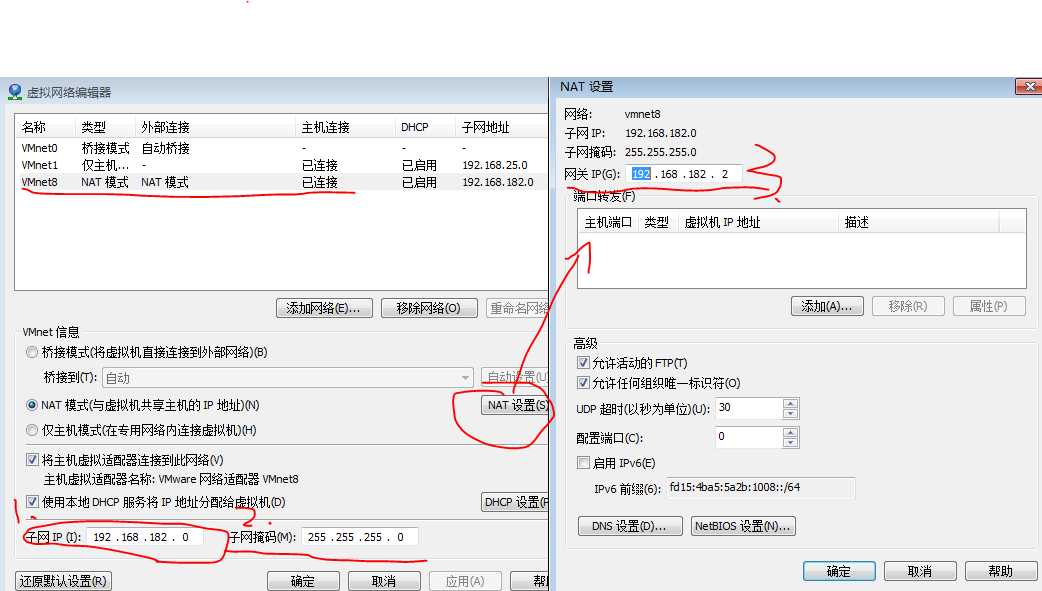
通过cmd也能找到网卡设置
cmd > ipconfig
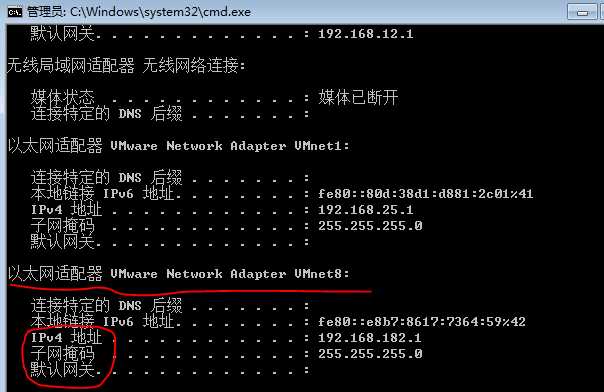
2.3、虚拟机设置
虚拟机安装可以参考: https://www.cnblogs.com/sxdcgaq8080/p/7466529.html
网络适配器:NAT
内存:512MB~1024MB即可
安装可以选择:最小安装
安装一台虚拟机即可,其他几台可以使用克隆方法:(其他几台虚拟机也可以在单机配置完毕后进行复制)
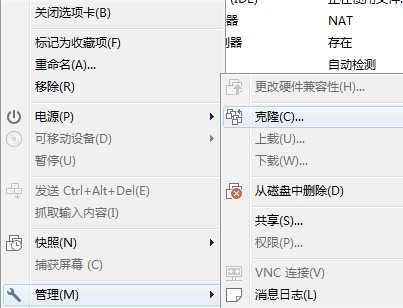
2.4、各虚拟机设置
2.4.1 静态ip的设置
2.4.2 主机名的设置
2.4.3 hosts设置
2.4.3 ssh密钥的设置
下面进行设置:可以参考我这里的配置
修改静态ip
这里的ifcfg-ens33需要根据个人虚拟机的网络名
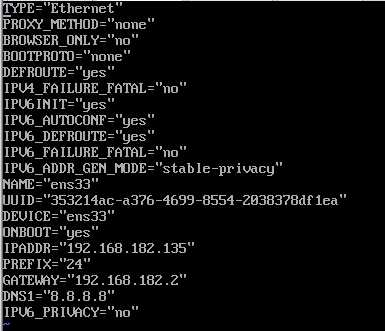
cd /etc/sysconfig/network-scripts ls vi ifcfg-ens33
这里修改:ONBOOT=yes,BOOTPROTO=static
添加:IPADDR=192.168.182.135 #参考前面的网卡设置
NETMASK=255.255.255.0 #参考前面的网卡设置
GATEWAY=192.168.182.2 #参考前面的网卡设置
DNS1=8.8.8.8
service network restart
进行网络重启后连接测试(个人/外网):ping 主机ip/www.baidu.com
其他三台虚拟机设置如上,只有ip需要修改
主机名修改:
hostname node1 su vi /etc/sysconfig/network vi /etc/hostname
reboot
network中添加:NETWORKING=yes
HOSTNAME=node1
hostname中添加:node1
之后重启:reboot
其他三台虚拟机设置如上,分别修改主机名为node2,node3,node4
hosts的设置:
vi /etc/hosts
node1的修改如下:
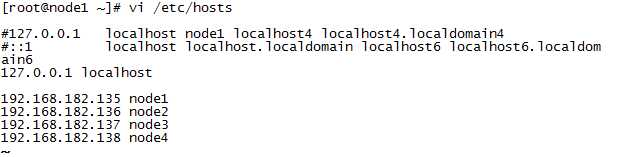
其他三台虚拟机设置如上,没有变化
ssh密钥的设置:
以下命令用于生成ssh键值对,复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys

其他三台虚拟机执行以上命令后,需要对node1进行设置,以后能通过node1免密访问其他主机。
通过SecureCRT分别连接4台虚拟机,需要将node1的公钥发送到其他主机进行记录
scp ~/.ssh/id_rsa.pub root@node2:~/.ssh/id_rsa_n1.pub scp ~/.ssh/id_rsa.pub root@node3:~/.ssh/id_rsa_n1.pub scp ~/.ssh/id_rsa.pub root@node4:~/.ssh/id_rsa_n1.pub
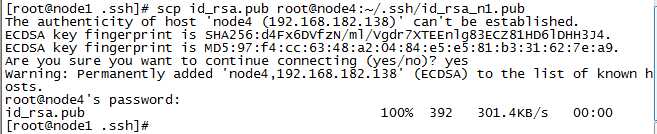
发送完毕后,将id_rsa_n1.pub中的内容追加到authorized_keys中
cat ~/.ssh/id_rsa_n1.pub >> ~/.ssh/authorized_keys

三台虚拟机完成上面操作可在node1主机中进行验证
ssh node2 ssh node3
正确的设置下登陆是不需要密码的,用exit退出登录

2.5、jdk1.8.0的设置安装及hadoop2.8.5的安装
2.5.1 jdk1.8的安装
首先卸载原centOS系统中附带的jdk
通过以下两个命令查找系统中的jdk
rpm -qa | grep jdk rpm -qa | grep gcj
可能的结果是:(也有可能有其他的)
libgcj-4.1.2-42.el5
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
之后通过 yum -y remove <file>命令卸载
yum -y remove java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
最后输入java -version验证虚拟机中是否还有jdk
接下来是安装的过程
1、通过SecureCRT将linux版本的jdk,hadoop,zookeeper(为了后面的搭建)发送到虚拟机上
 通过SFTP进行发送
通过SFTP进行发送
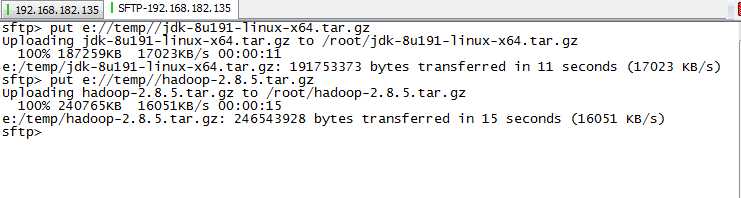
发送后的tar.gz文件在~文件夹内

使用 tar -zxvf <file> 进行解压 之后使用 mv ~/<file> /usr/local/java/ 移动到/usr/local目录下
这里我的目录是在/usr/local下

2、各种环境的配置
linux的环境配置在/etc/profile中
vi /etc/profile
在文件的最后添加如下的配置(后面的也一并配置了)
这里注意各个软件的目录位置
export HADOOP_HOME=/usr/local/hadoop2.8.5 export JAVA_HOME=/usr/local/java/jdk1.8.0 export ZOOKEEPER_HOME=/usr/local/zookeeper export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_INSTALL=$HADOOP_HOME export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
后面使用 source /etc/profile 刷新文件即可
下面进行验证:
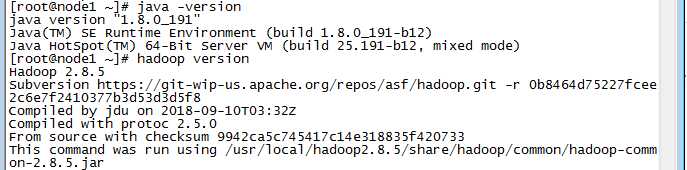
到这里验证通过就说明安装成功了。
三、HA集群搭建的设置
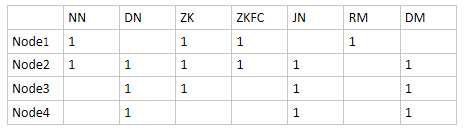
以上是各node上的分布:
NN:namenode DN:datanode ZK : zookeeper(QuorumPeerMain)
ZKFC : DFSZKFailoverController JN : JournalNode RM:ResourceManager
DM:DataNode、NodeManager
以下配置参考hadoop HA 官网配置:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
各hadoop文件配置:
cd $HADOOP_HOME ls cd etc/hadoop
该目录下进行hadoop的配置(均在configuration标签中配置):
core-site.xml

<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoopHA</value> </property>
hdfs-site.xml
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/journal/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
cp mapred-site.xml.template mapred-site.xml
通过这个创建mapred-site.xml配置
mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
编辑slaves文件,添加以下内容
node2
node3
node4
所有配置完成之后,要全部同步到其他几台虚拟机
scp ./* root@node2:/usr/local/hadoop2.8.5/etc/hadoop/
scp ./* root@node3:/usr/local/hadoop2.8.5/etc/hadoop/
scp ./* root@node4:/usr/local/hadoop2.8.5/etc/hadoop/
对于zookeeper进行配置
cd $ZOOKEEPER_HOME/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改:dataDir=/opt/zookeeper #这里指定zookeeper的data数据目录(没有,需要手动创建)
在最后添加:
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
现在保存并去创建zookeeper的data数据目录,在该目录下
vi myid
在该文件中不同zookeeper虚拟机中配置不同(不能有错),跟zoo.cfg后面配置的server有关,myid文件中只有1个数字即可。
node1:1
node2:2
node3:3
四、集群服务的启动验证
1、(node1,node2,node3)虚拟机上的zookeeper启动
cd $ZOOKEEPER_HOME/bin
./zkServer.sh start
启动完成后可通过 ./zkServer.sh status 进行查看
2、在node1上进行验证
2.1、格式化操作
cd $HADOOP_HOME/bin
zkfc格式化:hdfs zkfc -format
hdfs格式化:hdfs namenode -format
2.2、HA的启动
cd $HADOOP_HOME/sbin
./start-dfs.sh(启动HDFS)
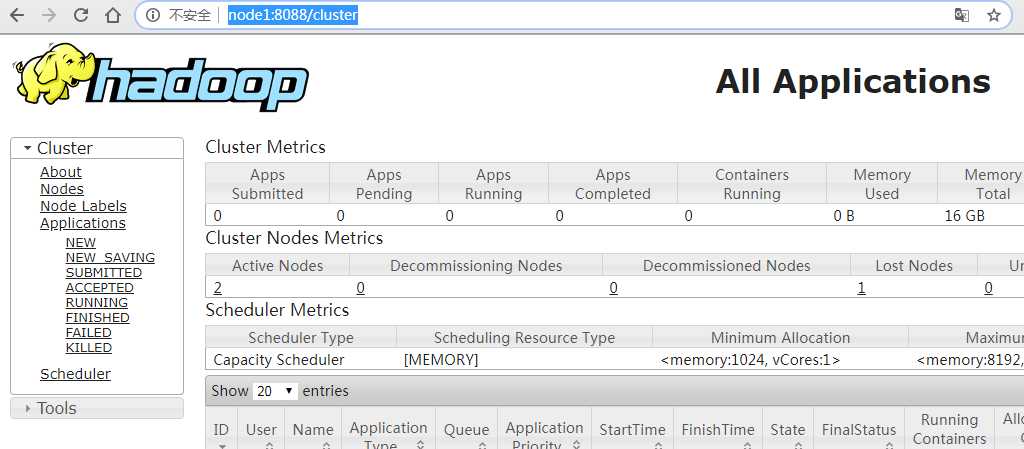
./start-yarn.sh(启动YARN)
2.3、HA的验证
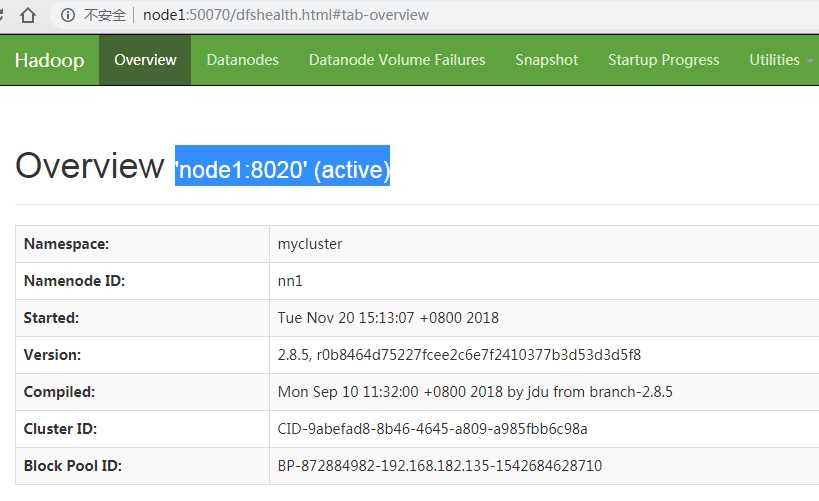
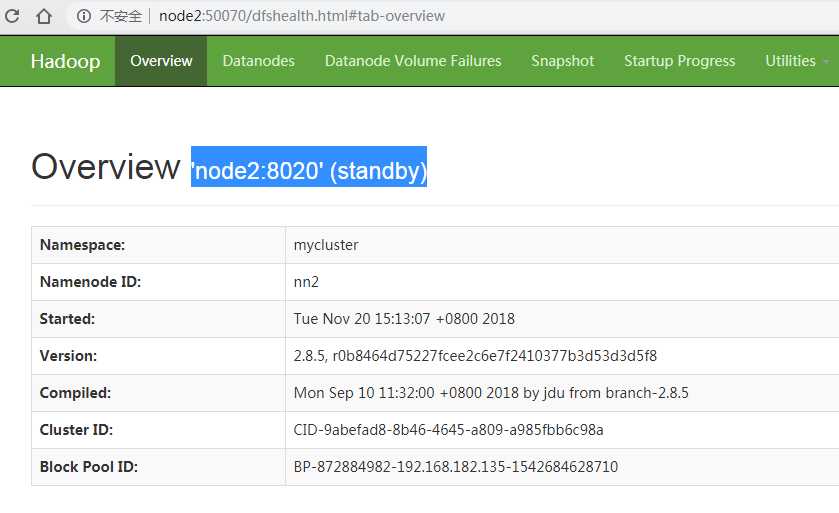
各node主机的hadoop端口验证
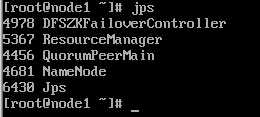
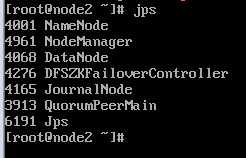
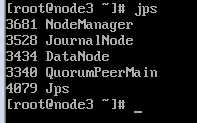
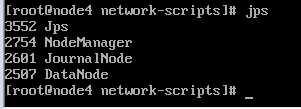
zookeeper各节点验证
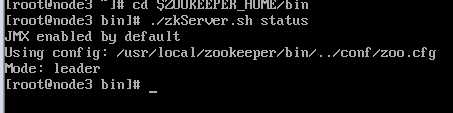
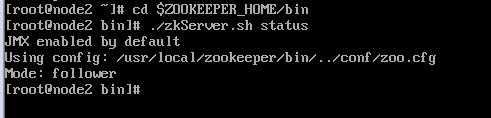
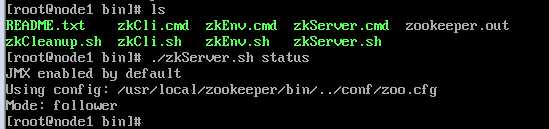
2.4 、外部网站验证
标签:path 内容 复制 over 卸载 文件中 log cga 元数据
原文地址:https://www.cnblogs.com/null-/p/10000309.html
