标签:class 权重 from 公式 learn target 线性回归 sele 完全
# 线性回归可以求解 各个特征的权重 # 但是如果特征比样本还多 这个时候用线性回归就无法求解了 # 三元一次方程组 y1 = w1*x11 + w2*x21 + w3*x31 y2 = w1*x12 + w2*x22 + w3*x32 y3 = w1*x13 + w2*x23 + w3*x33 1 2 3 2 4 6 4 8 12 10 20 40 w1*1 + w2*2 + w3*3 = 10 w1*2 + w2*4 + w3*6 = 20 w1*4 + w2*8 + w3*12 = 40 1 2 3 2 4 6 4 8 12 1 2 3 1 0 0 2 2 3 2 4 6 + 0 1 0 = 2 5 6 4 8 12 0 0 1 4 8 12 # 通过人为引入 偏差 使得方程有解 # 使得 样本数 < 特征数 的方程 有解 # 比如一个图片 成百上千个特征 样本数没有特征数那么多
X = np.array([ [1,2,3], [2,4,6], [4,8,12] ]) y = np.array([10,20,40]) # (X.T*X)^-1*X.T*y
import numpy as np np.linalg.inv(np.dot(X.T,X)) # Singular matrix 奇异矩阵 # 没法计算 0.5*np.eye(3) np.linalg.inv(np.dot(X.T,X)+0.5*np.eye(3))
使用岭回归
岭回归一般用在样本值不够的时候
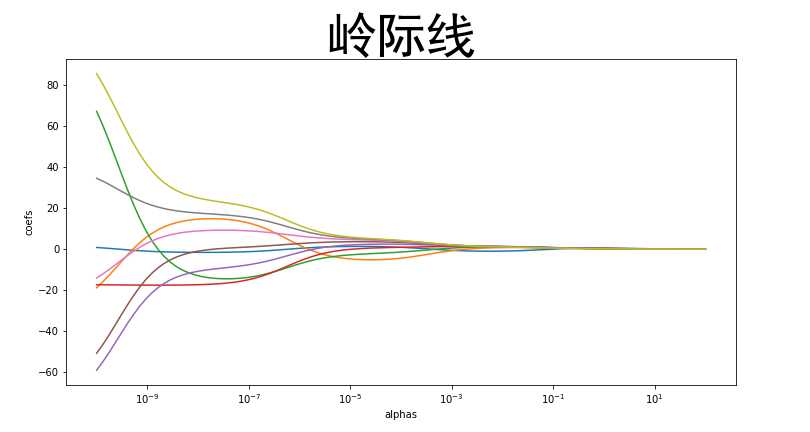
from sklearn import datasets # 从sklearn中获取数据集 diabetes = datasets.load_diabetes() # 加载糖尿病数据 data = diabetes.data # 特征值 target = diabetes.target # 目标值 import pandas as pd pd.DataFrame(data,columns=diabetes.feature_names) from sklearn.linear_model import Ridge # Ridge 山岭 # alpha就相当于上面公式中的lambda 用来空值引入的偏差的大小 # 默认值是1 相当于 引入了一个单位矩阵 # 一般 我们还可以设置成 0.1 0.01 0.001 引入的偏差就小了 # 如果 10 100 1000 引入的偏差就会很大 rr = Ridge(alpha=1000) # 如果alpha是0(没有引入偏差 就和普通线性回归完全一样) # 如果alpha太大 原来的权重就都成0了(各个特征和结果是无关的)
rr.fit(data,target) rr.coef_ # 使用岭回归 估测出来的 各个特征的权重 # 和线性回归做对比 from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(data,target) lr.coef_ # 普通线性回归 估测出来的 各个特征的权重
标签:class 权重 from 公式 learn target 线性回归 sele 完全
原文地址:https://www.cnblogs.com/louyifei0824/p/10002419.html