标签:sudo 权限 ip地址 删除 div ram slaves master 生产
集群配置:
jdk1.8.0_161
hadoop-2.6.1
zookeeper-3.4.8
linux系统环境:Centos6.5
3台主机:master、slave01、slave02
Hadoop HA集群搭建(高可用):
设置静态IP地址
为普通用户添加sudo权限
服务器网络设置:NAT模式
域名设置
主机名设置
SSH免登录配置
关闭防火墙
红色步骤主每台主机都要执行,参照上一篇伪分布式集群的搭建
环境变量(每台主机一样):
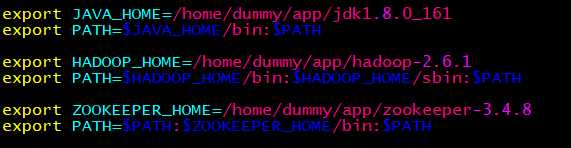
配置文件:
配置core-site.xml
<configuration>
<property>
<!-- 指定hdfs的nameservice为ns1 -->
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir </name>
<value>/home/dummy/app/hadoop-2.6.1/hdpdata</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave01:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave01:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave01:8485;slave02:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/dummy/app/hadoop-2.6.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverPr
oxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/dummy/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置slaves
master
slave01
slave02
HA安装步骤
全新的集群的启动方式:(一定要按步骤执行)
最关键的步骤:把防火墙全部关闭
第一步:启动ZooKeeper集群
第二步:在其中一台修改core-site.xml和hdfs-site.xml的配置文件,修改好后,把它分发到其它的机器
第三步:启动hadoop-daemon.sh start journalnode(三台都启动)
第四步:格式化namenode,然后把格式化的namenode的目录分发到另外一台namenode,分发hdpdata即可
第五步:再到其中一台的namenode上执行命令hdfs zkfc -formatZK
第六步:启动集群
第七步:网页正常访问
非全新的集群的启动方式:
非全新集群模式指的是你之前可能运行过HA或者普通的集群,这个时候,如果是以前运行过HA,但是现在报错,
最简单的方式,先把ZK下面的data里面的数据全部删除,只保留myid,这个时候ZooKeeper就是一个全新的。
并且把hadoop下面的logs和格式化生产的目录全部删除,这个时候保证hadoop是一个全新的。
上面的所有的步骤都是为了保证你重新从一个全新的集群开始搭建HA,可以避免很多问题。
之后的安装参照上面的全新的集群的启动方式进行。
之后集群的启动就是:
每台机启动 zkServer.sh start
再在任意一条主机的hadopp/sbin 目录启动
start-all.sh
hadoop ha集群搭建
标签:sudo 权限 ip地址 删除 div ram slaves master 生产
原文地址:https://www.cnblogs.com/dummyly/p/10006617.html