标签:这一 反汇编 伪指令 img 情况 而不是 通过 实现 完成后
1. 理解和掌握将数据、代码、栈放入不同段的程序的编写和调试
2. 理解具有多个段的汇编源程序对应的目标程序执行时,内存分配方式
1. 结合第 6 章教材和课件,复习第 6 章内容
2. 复习第 3 章「栈」的知识
实验任务(1)
下载课程公邮中的程序框架放入,masm.exe,link.exe同文件夹下,用DS BOX挂载到masm文件夹后
使用之前写好的process.bat文件简化编译,连接,执行操作。
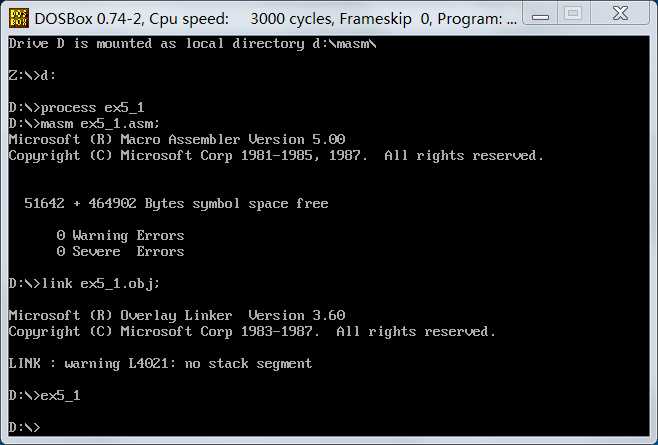
顺利执行,下面对ex5_1.exe debug。
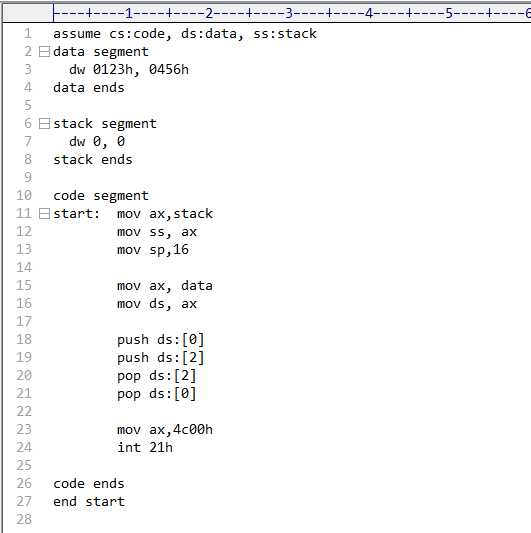
使用r命令查看各寄存器的值,下面我们要精确反汇编程序段,首先通过r命令可以看出cx=0042,
即这段程序所占的字节数是42h,但这还包括数据段和栈段,数据段有8个数据,16个字节,即
10h,栈段也是16个字节,即10h。所以代码段长度为42-20=22h,CS:IP = 076C:0000,所以若要精确反汇编
,应该是u 0000 0021(注:代码段,栈段,数据段均是从0开始的)。成功反汇编代码段。
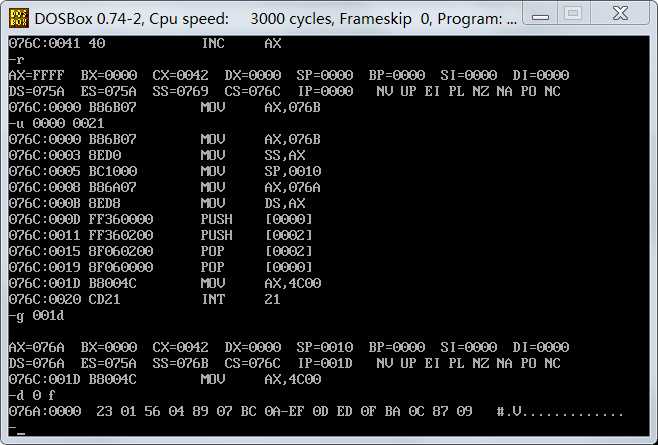
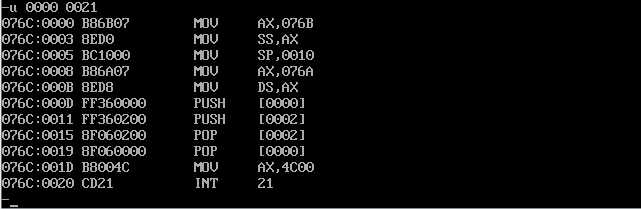
题目要求的是程序返回前,即 mov ax,4c00 int 21前,根据反汇编结果可知,因执行到CS:001d前,使用
g命令达到这一效果。
已经可以看出CPU执行程序,程序返回前,cs=076c,ss=076b,ds=076a.
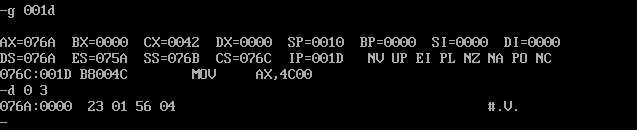
接下来需要查看数据段,已知数据段长16个字节,使用d命令查看内存中的数据 d 0 f(注:代码段,栈段,数据段均是从0开始的)
可以看出,程序返回前的数据段并没有改变(读数据时注意是小端法存储的)。
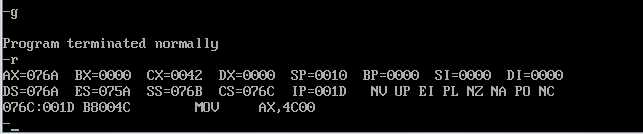
使用g命令执行完程序,程序加载后,可以看出DS = CS-2,SS=CS-1;

根据实验结果完成了书中填空。
实验任务(2)
前期步骤同(1)
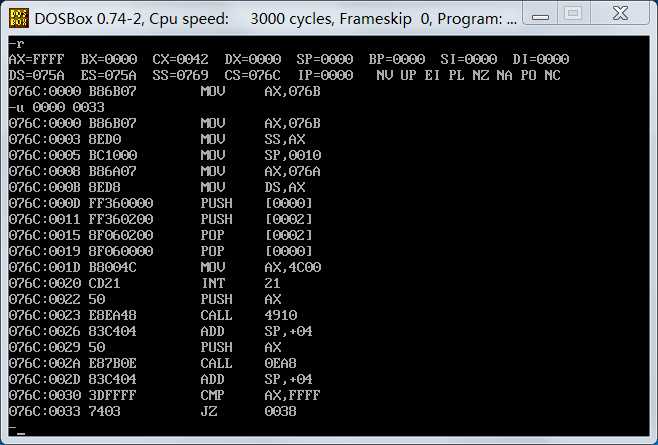
同实验(1),首先通过r命令可以看出cx=0042,即这段程序所占的字节数是42h,但这还包括数据段和栈段,数据段有2个数据,4个字节,栈段也是2个字节。
所以代码段长度为42-8=34h,CS:IP = 076C:0000,所以若要精确反汇编
,应该是u 0000 0033(注:代码段,栈段,数据段均是从0开始的)。但这里我却并没有做到成功反汇编,显然我们所给反汇编范围大了
通过查看源代码,给出猜测,虽然栈段和数据段都只给出了4个字节,但从第13行代码看出
,这里设sp = 16,栈顶设为了16,也就是说这里的栈仍然是16个字节的,尽管没有填满,所以情况应该和
实验(1)是一样的,当然这只是我的猜测
精确反汇编的结果与实验(1)一样
题目要求的是程序返回前,即 mov ax,4c00 int 21前,根据反汇编结果可知,因执行到CS:001d前,使用
g命令达到这一效果。
已经可以看出CPU执行程序,程序返回前,cs=076c,ss=076b,ds=076a.
接下来需要查看数据段,已知数据段长4个字节,使用d命令查看内存中的数据 d 0 3(注:代码段,栈段,数据段均是从0开始的)
可以看出,程序返回前的数据段并没有改变(读数据时注意是小端法存储的)。

使用g命令执行完程序,程序加载后,可以看出DS = CS-2,SS=CS-1;
这里的情况和实验(1)是一样的
考虑对于如下定义的段:
name segment
...
name ends
通过查阅资料得知
如果段中数据占N个字节,则程序加载后,该段实际占有的空间为 [(N+15)/16]*16。
数据段都是以16个字节对齐,不足16字节按16字节算,这也解释了对于实验任务(2)我的
疑问。
根据实验结果完成书中填空

实验任务(3)
与实验任务(1)(2)相同,前面的步骤在这里就省略截图分析了,直接从debug后开始
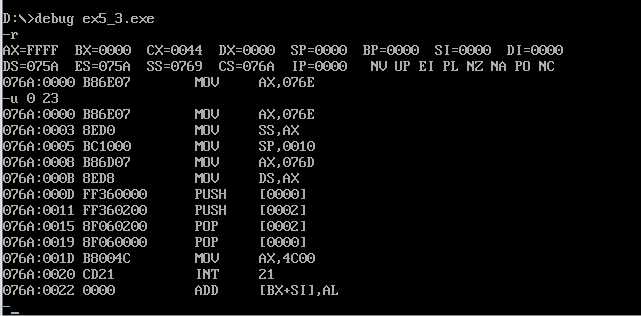
这里的精确反汇编又出现了问题,根据之前的实验总结,应该是CX = 44-10-10=24h,
所以应该是 u 0 23进行精确反汇编,但这里却还是应该 u 0 21。原因不得而知。
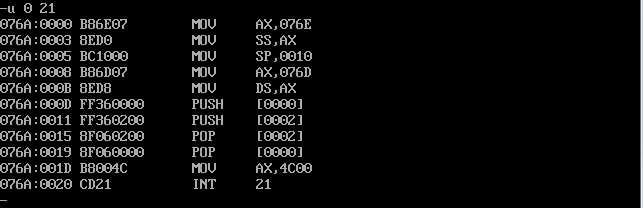
修改后精确反汇编

已经可以看出CPU执行程序,程序返回前,cs=076a,ss=076e,ds=076d.
接下来需要查看数据段,已知数据段长4个字节,使用d命令查看内存中的数据 d 0 3(注:代码段,栈段,数据段均是从0开始的)
可以看出,程序返回前的数据段并没有改变(读数据时注意是小端法存储的)。

使用g命令执行完程序,程序加载后,可以看出DS = CS+3,SS=CS+4;
根据实验结果完成书中填空

实验任务(4)
如果将(1),(2),(3)题中的最后一条伪指令“end start”改为“end”(也就是说,不指明程序的入口个),则哪个程序仍然可以正确执行?请说明原因。
对三个程序内容进行修改编译连接执行后
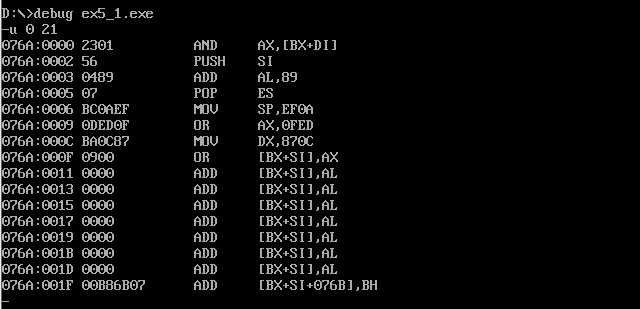
对第一个程序的反汇编结果,可以发现该程序已经没有办法正确执行
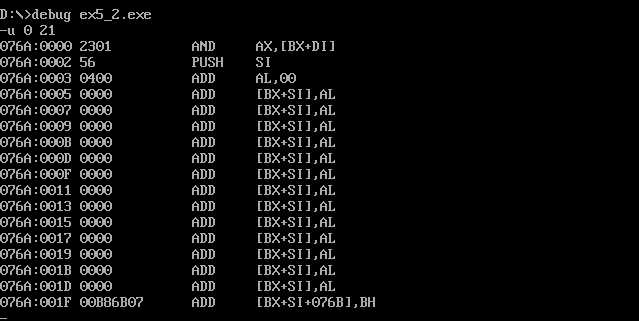
程序2也是无法正确执行
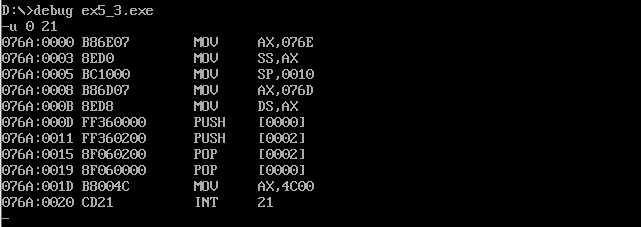
程序3可以正确执行
因为如果没有end start就会默认以IP=0开始执行,而不是从start开始执行。
而实验内容(3)的data和stack都在code之后,所以IP本来就为0,可以正确执行。
实验任务(5)
(1) 汇编程序源代码
补全代码如下:

分析:编写code代码,将a段b段中的数据依次相加,将结果存在c段中。
bx用于偏移量,初始置显然为0,dx为求和寄存器初始值也是0,cx用于设置循环次数,这里有a,b中均有8个字
,所以循环次数也就是8次。
循环体部分:每次将a段中和b段中内容依次加到寄存器dx中,最后将结果存到c段中。
这里需要注意,循环体开头部分每次都要将用于求和的寄存器bx置为0,否则上次的结果会接着累加。
偏移量bx每次增加一次,大体步骤就是这样,具体细节在这里就不做过多的阐述。
(2) 在 debug 中调试程序截图,截图中包括如下信息:
① 在实现数据相加前,逻辑段 c 的 8 个字节
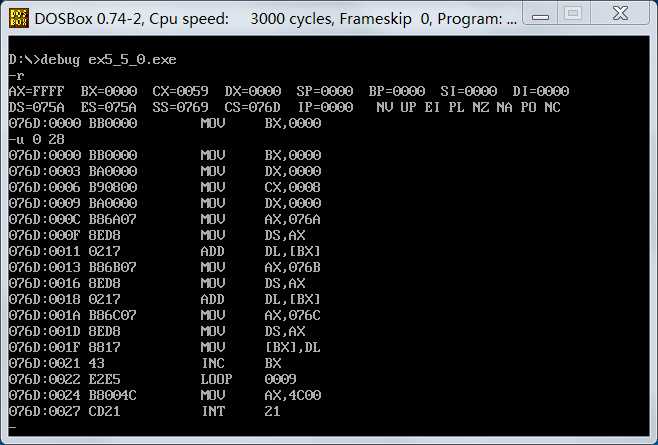
进入debug,然后查看寄存器,精确反汇编(CX-10h-10h-10h=29h),u 0 28
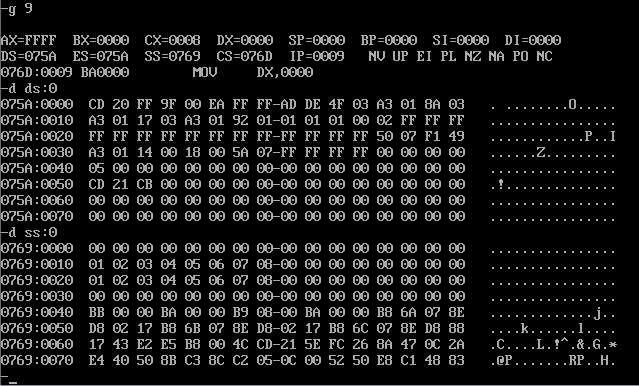
根据精确反汇编结果,执行到循环体外,使用d命令查看数据段内容,发现并没有做到预期,
但查看栈段内容时,发现第二行到第四行显示的内存符合预期,原因不得而知。
② 执行完实现加运算的代码后,逻辑段 c 的 8 个字节
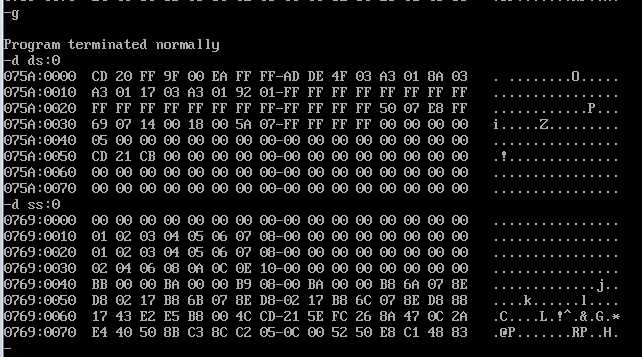
使用g命令执行完成后,发现用d命令查看数据段内存内容仍然不符合预期,但栈段内存内容
符合,第四行确实是前两行相加的结果。
根据①和②的调试,证实了程序确实正确的实现数据相加。
实验任务(6)
(1) 汇编程序源代码
补全代码如下:

分析:编写code段中的代码,用push指令将a段中的前8个字型数据,逆序存储b段中。
需要逆序存储,自然的便想到了栈段,这里需要设一个栈段,需要将b段前8个字数据逆序存储,
8个字数据即16个字节,栈顶SP = 16 =10h,栈底为SS = SP+1.
这里只要设置8次循环,将a段中前8个字型数据push到栈中,即实现了题目要求。
(2) 在 debug 中调试程序截图,截图中包括如下信息:
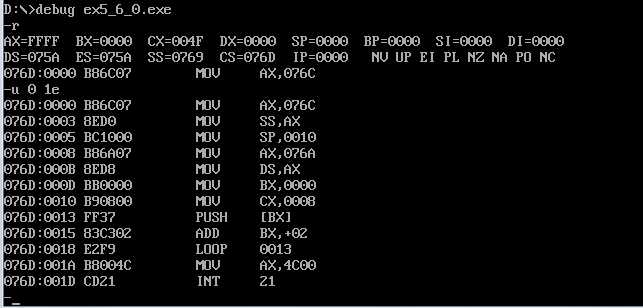
进入debug,使用r命令进行查看,精确反汇编(CX-20h-10h=1fh)u 0 1e
成功精确反汇编。
① 在 push 操作执行前,查看逻辑段 b 的 8 个字单元信息截图
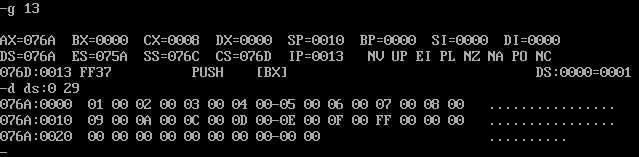
根据反汇编结果,使用g命令执行到push操作前,用d命令查看内存中内容,长度为a段的
32(20h)个字节加上b段16(10h)个字节,d ds:0 29.
可以看出b段8个字全是0.
② 执行 push 操作,然后再次查看逻辑段 b 的 8 个子单元信息截图

使用g命令执行完成后,用d命令查看,发现b的8个字单元为a段前8个字节的逆序.
根据①和②的调试,验证程序确实正确的实现题目要求。
1.通过此次实验理解和掌握将数据、代码、栈放入不同段的程序的编写和调试
理解具有多个段的汇编源程序对应的目标程序执行时,内存分配方式。
2.我们开始逐渐进入到汇编编程中,汇编也并不是很枯燥的,在实验过程中只有不断的探索尝试才能真正
体会汇编的乐趣。
标签:这一 反汇编 伪指令 img 情况 而不是 通过 实现 完成后
原文地址:https://www.cnblogs.com/mr-gao1/p/10002610.html