标签:需要 svc 自动 unit div csv parse 找到你 适合
既然你点进来看了,我就默认你知道什么是爬虫了。不知道也没有关系,来看一下爬虫的定义:网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。可以写爬虫的语言、框架有很多,这里记录一下Scrapy的入门教程。
安装Scrapy需要在Python2.7 或Python3.4 及以上版本,可以通过pip或Anaconda、Miniconda安装
如果你使用pip安装,可以在powershell/cmd/bash中键入
pip install scrapy
如果你使用Anaconda或者Miniconda,可以键入
conda install -c conda-forge scrapy
PS:在安装过程中你可能遇到Twisted这个包安装报错,如果报了找不到cl.exe文件的错误,可能是因为你没有安装VS或者没有将cl.exe所在的路径添加到环境变量里,假设你已经安装了VS找到这个路径 (我的路径是C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.16.27023\bin\Hostx64\x64)把路径添加到环境变量,或者你觉得安装VS太麻烦,你还可以打开这里找到你适合你机器环境的版本的whl包并执行下列命令先安装Twisted,然后再安装Scrapy就可以了。
pip install D:\Twisted?18.9.0?cp37?cp37m?win_amd64.whl
感谢加州大学尔湾分校荧光动力学实验室的Christoph Gohlke
安装完了之后键入
scrapy -V
如果出现下图画面即为安装成功

这里我用了PyCharm,不用也没关系,只用命令行和记事本也是可以的。
在Terminal这个标签页里(poweshell/cmd/bash也可以,注意先要转到你要创建项目的目录再执行命令)键入
scrapy startproject tutorial
这里tutorial是你的项目名称,你可以根据你的爬虫内容自行更改。
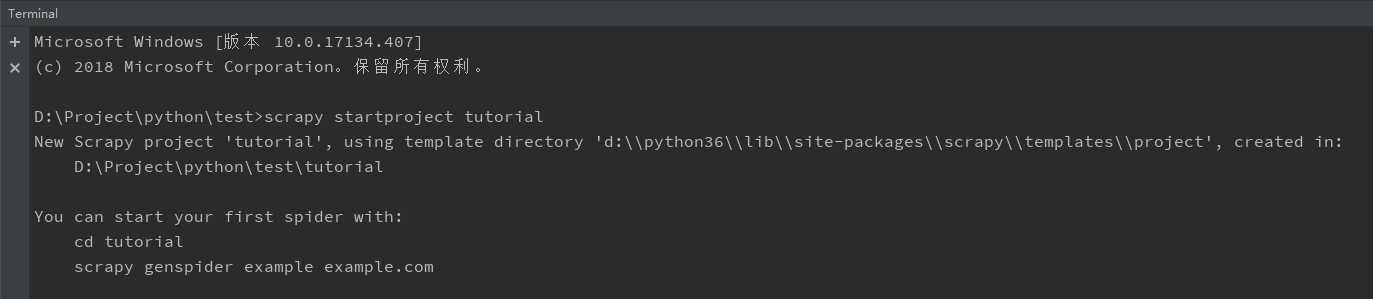 项目创建好了之后结构如下:
项目创建好了之后结构如下:
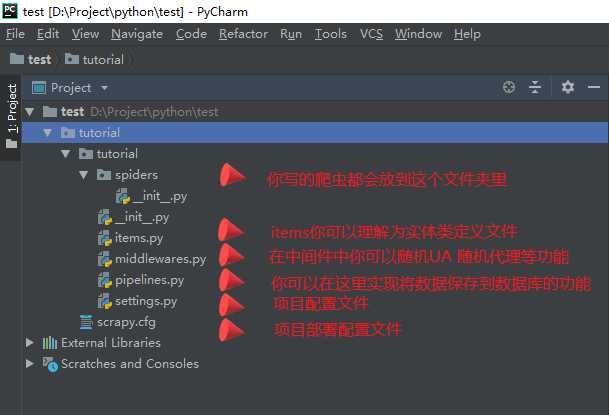 接下来我们按照命令行里的提示转到爬虫目录使用模板生成我们第一个爬虫,键入如下命令:
接下来我们按照命令行里的提示转到爬虫目录使用模板生成我们第一个爬虫,键入如下命令:
cd tutorial\tutorial\spiders
scrapy genspider quotes quotes.toscrapy.com
这里quotes是你爬虫的名称,注意这个名称必须是项目里唯一的(即其他爬虫不能使用同样的名字,否则会报错) quotes.toscrapy.com是你要爬取数据的网站的域名

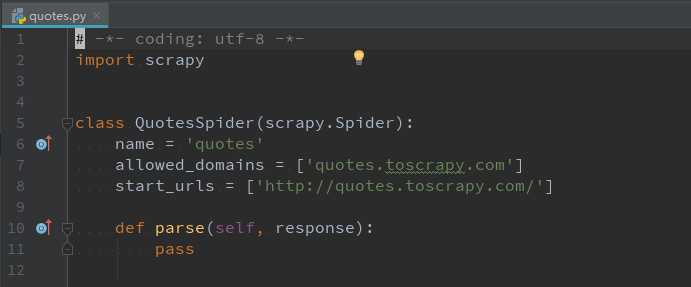 执行完命令之后会在spiders这个文件夹里出现quotes.py这个文件,这就是我们第一个爬虫
执行完命令之后会在spiders这个文件夹里出现quotes.py这个文件,这就是我们第一个爬虫
这里引入了scrapy包,创建了一个QuotesSpider类继承了scrapy.Spider类,QuotesSpider类的name就是上面提到的必须唯一的爬虫名称,allowed_domains表示爬虫只爬取这个数组里记载的域名的网页,start_urls是爬虫开始爬取数据的url(如果使用了start_urls,则会把response自动交给parse函数处理)
接下来我们改造一下爬虫,把爬取的网页保存下来。quotes.toscrapy.com这个网站是Scrapy官方建立的给大家练习爬取数据的网站没有链接到其他网站,allowed_domains可以先删掉,但要保留start_urls数组 或者start_requests函数以及解析response的解析函数。
start_urls数组和parse函数与start_requests函数和parse函数是等价的,它们区别是如果你使用了start_urls数组就只能使用parse函数解析response,如果使用了start_requests函数可以指定回调的解析函数不一定是parse函数也可以是parseXXX,start_urls是start_requests的一个简写。
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = ‘quotes‘ def start_requests(self): urls = [ ‘http://quotes.toscrape.com/page/1/‘, ‘http://quotes.toscrape.com/page/2/‘, ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): page = response.url.split("/")[-2] filename = ‘quotes-%s.html‘ % page with open(filename, ‘wb‘) as f: f.write(response.body) self.log(‘Saved file %s‘ % filename)
执行一下
scrapy crawl quotes
会在执行命令的目录下得到两个html文件,这样我们第一个简单的爬虫就完成了,它成功的保存了两个html文件。
但是实际工作中我们是不会满足于只保存网页的,我们要把网页里有用的数据保存下来,这就需要我们对网页内容也就是html进行解析,Scrapy给我们提供了一个命令行的方式获取html
scrapy shell "http://quotes.toscrapy.com/page/1"
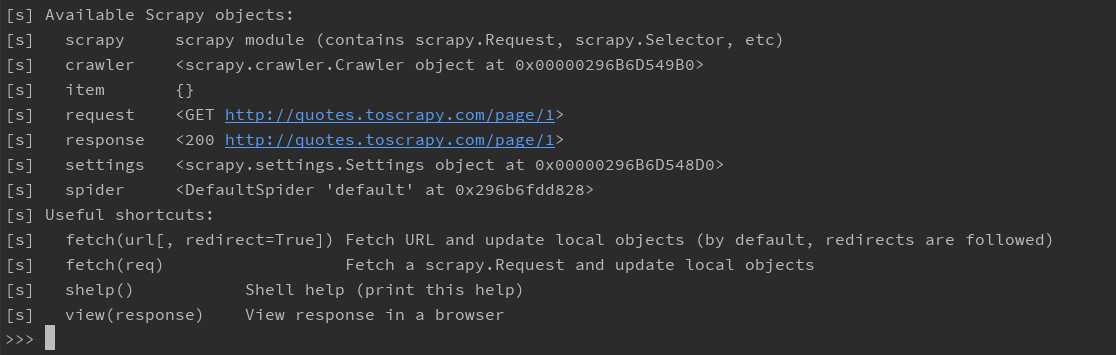 通过命令行获得网页的html代码后我们就可以对html进行解析了,Scrapy提供了css选择器解析和XPath解析两种方法,当然也可以结合beautifulsoup lxml等进行解析,如果有兴趣可以自学。
通过命令行获得网页的html代码后我们就可以对html进行解析了,Scrapy提供了css选择器解析和XPath解析两种方法,当然也可以结合beautifulsoup lxml等进行解析,如果有兴趣可以自学。
如果实在是懒的话可以在chrome中打开网页按F12 然后按Crtl+Shift+C用鼠标选择你想选择的元素在Elements标签页中右键点击然后Copy->Copy selector 或者copy XPath
键入
response.css(‘title‘)
如果没有意外的话会返回
[<Selector xpath=‘descendant-or-self::title‘ data=‘<title>Quotes to Scrape</title>‘>]
键入
response.css(‘title::text‘).extract_first()
会把html标签去掉直接返回title的内容Quotes to Scrapy
接下来我们再来把爬虫改一改使用css选择器将text字段,author字段,tag字段提取出来,然后注意到这个网页的右下角有下一页的链接,我们可以把下一页的链接也提取出来继续请求并解析。
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = "quotes" start_urls = [ ‘http://quotes.toscrape.com/page/1/‘, ] def parse(self, response): for quote in response.css(‘div.quote‘): yield { ‘text‘: quote.css(‘span.text::text‘).extract_first(), ‘author‘: quote.css(‘small.author::text‘).extract_first(), ‘tags‘: quote.css(‘div.tags a.tag::text‘).extract(), } next_page = response.css(‘li.next a::attr(href)‘).extract_first() if next_page is not None: next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback=self.parse)
键入
scrapy crawl quotes -o quotes.json
添加了-o 参数将解析好的数据生成到quotes.json文件中。Scrapy可以很方便的将数据生成到json/csv/jl(json line) 文件中。
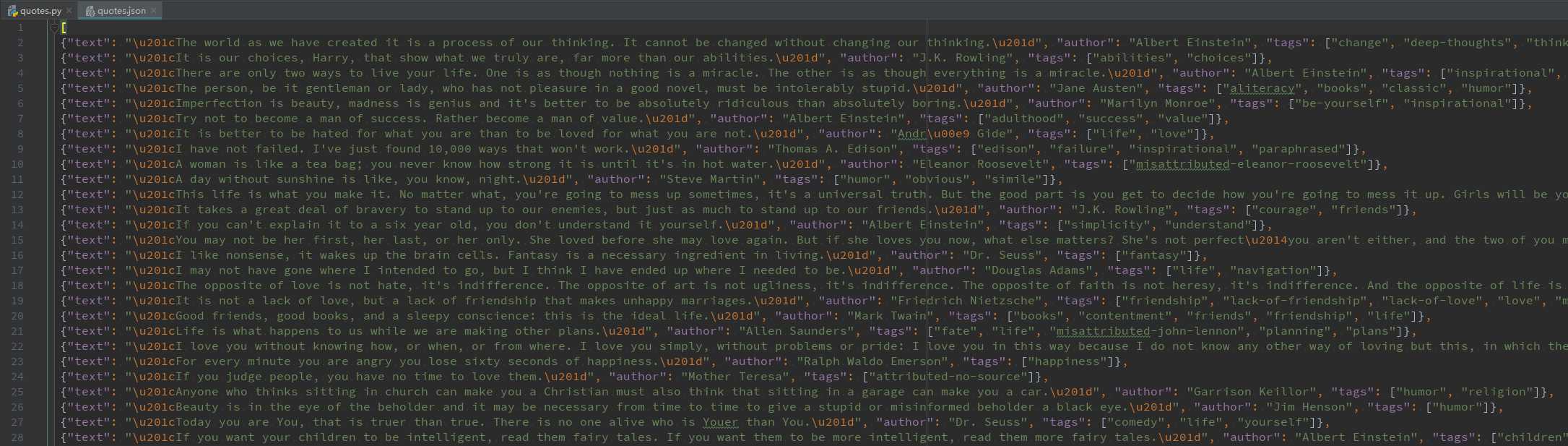
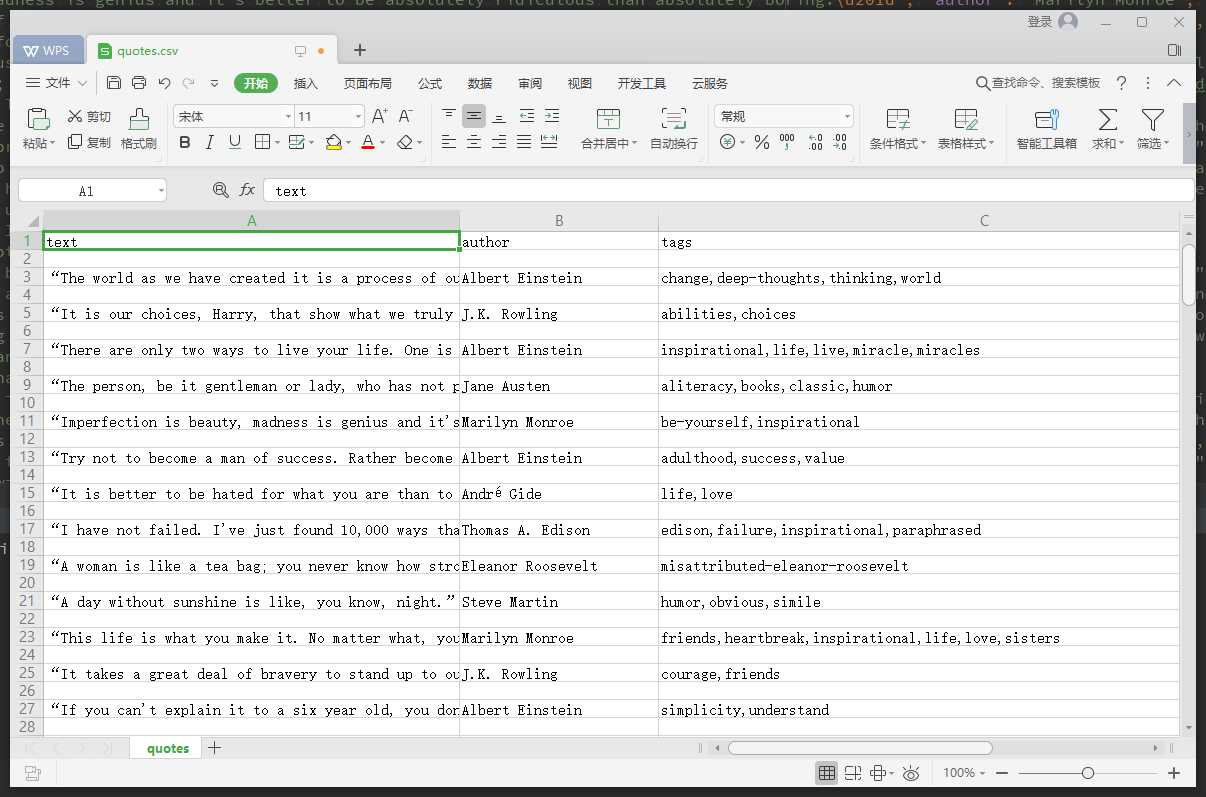
好了,到这里基本上你就算是入门了。
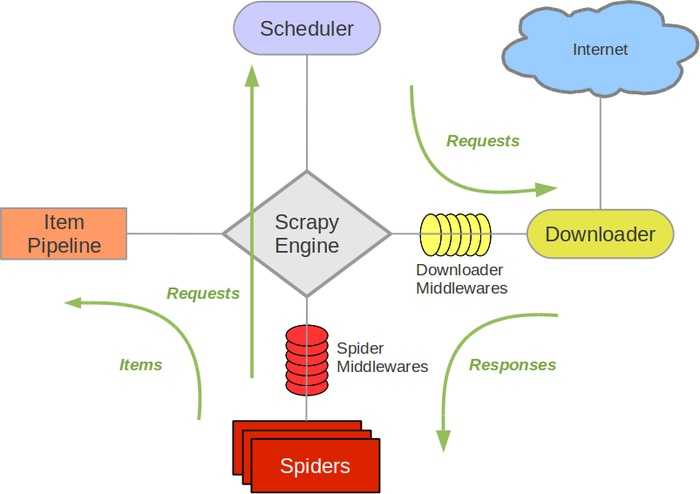
上图是网上广为流传的一张Scrapy的原理图,简单说一下吧一切的开始是从spider(爬虫)开始的。
**************************
最后如果你愿意的话,请随意打赏。


标签:需要 svc 自动 unit div csv parse 找到你 适合
原文地址:https://www.cnblogs.com/sinkingcn/p/10014469.html