标签:shuffle过程 聚合 一般来说 enc alt 拉取 sch iter 源码
一般来说,在执行shuffle类的算子的时候,比如groupByKey、reduceByKey、join等。 其实算子内部都会隐式地创建几个RDD出来。那些隐式创建的RDD,主要是作为这个操作的一些中间数据的表达,以及作为stage划分的边界。 因为有些隐式生成的RDD,可能是ShuffledRDD,dependency就是ShuffleDependency,DAGScheduler的源码,就会将这个RDD作为新的stage的第一个rdd,划分出来。
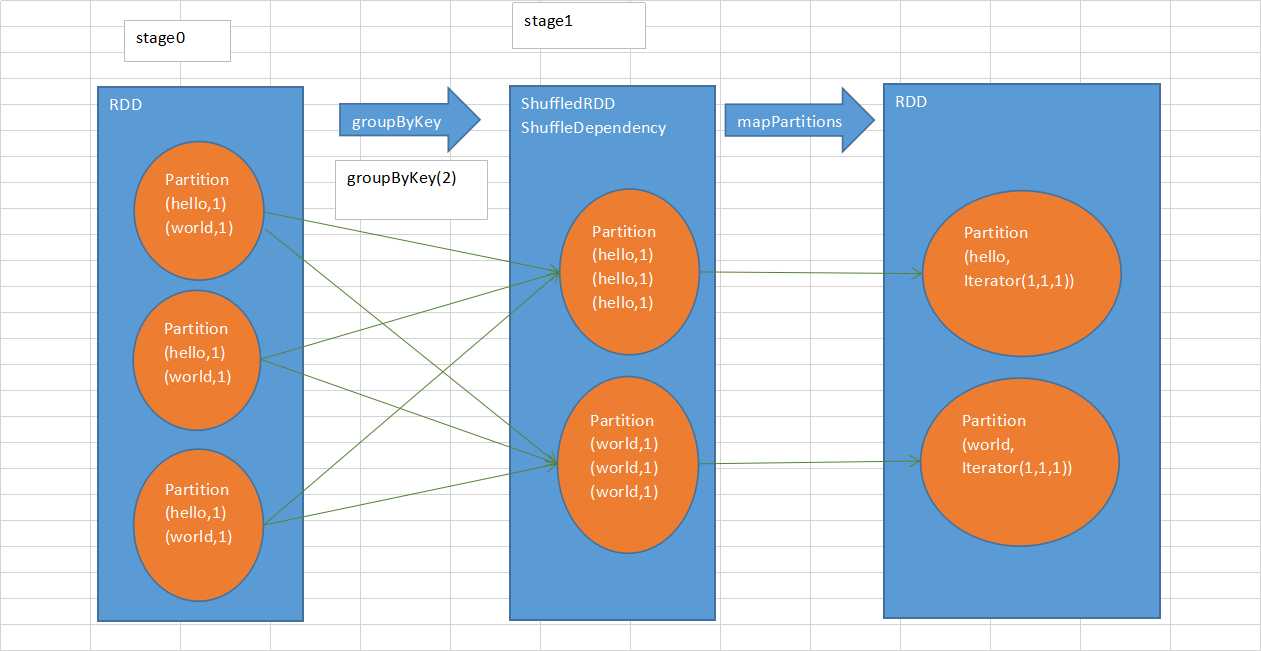
groupByKey等shuffle算子,都会创建一些隐式RDD。比如说这里,ShuffledRDD,作为一个shuffle过程中的中间数据的代表。 依赖这个ShuffledRDD创建出来一个新的stage(stage1)。ShuffledRDD会去触发shuffle read操作。从上游stage的task所在节点,拉取过来相同的key,做进一步的聚合。 对ShuffledRDD中的数据执行一个map类的操作,主要是对每个partition中的数据,都进行一个映射和聚合。这里主要是将每个key对应的数据都聚合到一个Iterator集合中。
标签:shuffle过程 聚合 一般来说 enc alt 拉取 sch iter 源码
原文地址:https://www.cnblogs.com/daiwei1981/p/10016059.html