标签:mode 解决 one sha constrain 问题 参数 com pair
承接上上篇博客,在其基础上,加入了Wasserstein distance和correlation prior 。其他相关工作、网络细节(maxout operator)、训练方式和数据处理等基本和前文一致。以下是这两点改进的大概:
文章的四大贡献:
Wasserstein distance引入,度量NIR和VIS模态的分布差异,相比之前的sample-level的度量,这个Wasserstein distance更有效减少两种模态的分布差异,提高性能。
异质人脸识别(验证)的四大类方法:
网络结构
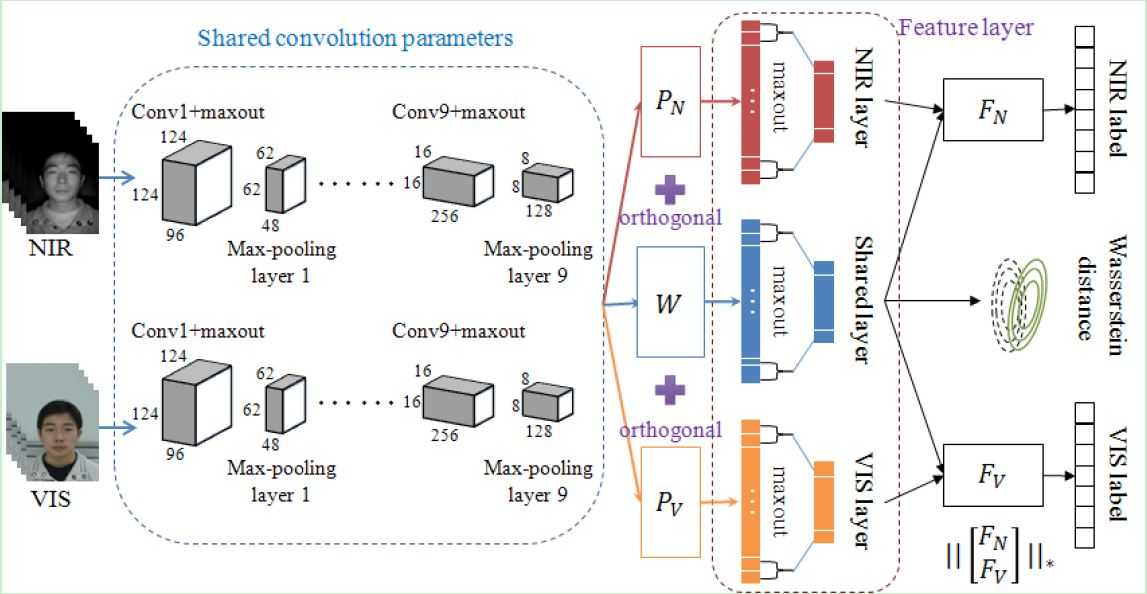
Fig 1. An illustration of our proposed Wasserstein CNN architecture. The Wasserstein distance is used to measure the difference between NIR
and VIS distributions in the modality invariant subspace (spanned by matrix W). At the testing time, both NIR and VIS features are exacted from
the shared layer of one single neural network and compared in cosine distance.
网络解释如下:
1. Modality Invariant Subspace
减轻NIR-VIS外观差异,即想办法移除掉光谱(外观)差异,那么只剩下identity信息就容易匹配了。之前的方法都是移除一些principal subspaces,假定这些子空间是包含光谱信息的。受此启发,这里引入三个映射矩阵(见上图):W,PN,PV。W用来将建模 modeling identity invariant information,P用来建模 variant spectrum information。所以输入两张图,得到三个特征:
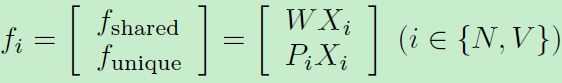
其中WX和PX分别表示共享特征和独立特征,考虑到子空间中分解特性,限制其互相无关:
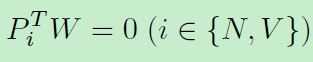
这个限制可减少参数空间,减轻过拟合。将特征表示和子空间学习两个独立步骤和合为一步。
2. The Wasserstein Distance
NIR和VIS图像的gap是异质图像识别的主要问题。之前的方法引导sample-level的限制来解决这个gap。比如有contrastive loss和triplet loss等都施加在NIR-VIS sample pairs上。这些方法仅仅考虑NIR-VIS samples的关系而非NIR-VIS 分布的关系。近来Wasserstein distance在GAN中度量模型分布和真实分布扮演了重要的角色。受到Wasserstein GAN和BEGAN的启发,我们利用Wasserstein distance来测量NIR和VIS数据分布之间的一致性。假定在非线性特征映射后同一subject遵从高斯分布。施加 Wasserstein distance 在同一subject(即同一个体identity)的分布上。具体实现细节见paper,比较好理解。
3. Correlation Prior
过拟合问题。NIR-VIS数据集通常比纯VIS数据集小得多。全连接的参数最多。本文将WCNN的全连接层分解为两个矩阵:FN、FV。分别对应NIR和VIS模态。我们希望M(下式)高度相关,使得M.T*M为一块对角矩阵。一个相关的M将减少估计的参数空间,减轻过拟合。进一步探索M的核范数。其余细节见paper。
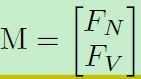
4. loss
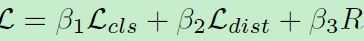
其中第一项为分类损失,第二项为W距离,第三项为proir约束。beta1=beta2=1,beta3=0.001,说明这个prior在这里不是很重要。
5. CONCLUSIONS
Same as before
Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition
标签:mode 解决 one sha constrain 问题 参数 com pair
原文地址:https://www.cnblogs.com/king-lps/p/10012172.html