标签:成本 secure color 本地 格式 exist note 实时 包含
一、Hive简介
1、hive概述 Apache Hive?数据仓库软件有助于使用SQL读取,编写和管理驻留在分布式存储中的大型数据集。 可以将结构投影到已存储的数据中。提供了命令行工具和JDBC驱动程序以将用户连接到Hive。 数据计算:mapreduce分布式计算->难度大 hive->SQL语句 mysql 简化开发 减少学习成本 2、优缺点 优点: (1)操作接口采用了sql,简化开发,减少学习成本 (2)避免手写mapreduce程序 (3)hive执行延迟较高,适用场景大多用在对实时性要求不强的情景 (4)优点在于处理大数据 (5)支持自定义函数 缺点: (1)hive的sql表达能力有限(HSQl) (2)hive效率低(粒度比较粗,调优较难) 3、hive架构 提供了一系列接口:hive shell、jdbc/odbc、webui
Hive架构
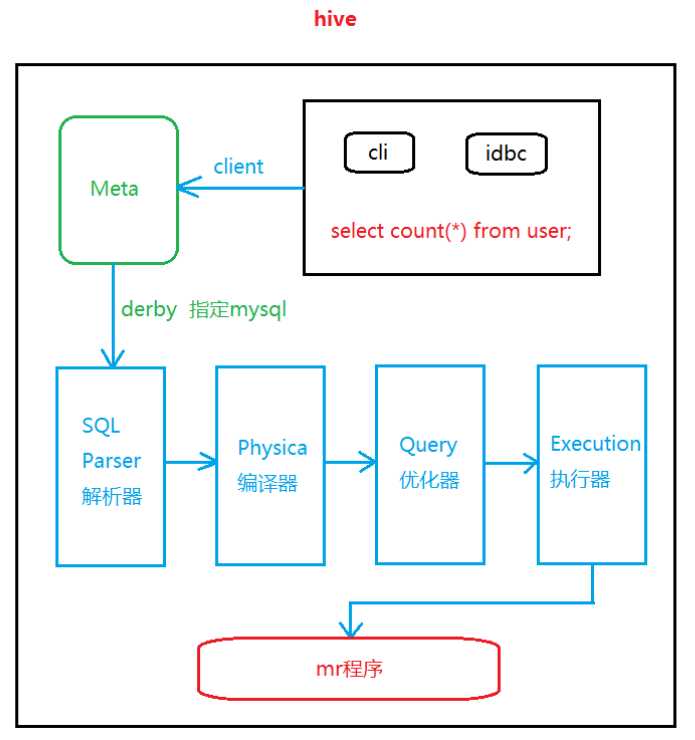
二、Hive安装
1、Hive安装 1)下载安装包 http://hive.apache.org/downloads.html 2)上传安装包 alt+p 3) 解压 tar -zxvf apache-hive-1.2.2-bin.tar.gz -C hd/ 4) 解压后的包重命名 mv apache-hive-1.2.2-bin/ hive 5) 修改配置文件 mv hive-env.sh.template hive-enc.sh vi hive-env.sh HADOOP_HOME=/root/hd/hadoop-2.8.4 export HIVE_CONF_DIR=/root/hd/hive/conf 6) 启动hive前启动hadoop集群 start-dfs.sh start-yarn.sh # start-all.sh # 不建议使用 7) 在hdfs上创建文件夹 hdfs dfs -mkdir /tmp hdfs dfs -mkdir -p /user/hive/warehouse/ 8) 启动hive bin/hive 2、hive测试 1)查看数据库 show databases; 2) 使用数据库 use default; 3) 查看表 show tables; 4) 创建表 create table student(id int,name string); 5)插入数据 insert into student values(1,"tom"); 6) 查询 select * from student; 7) 删除表 drop table student; 8) 退出终端 quit; 3、SecureCRT使用hive命令行不能回退 选择工具栏中的【选项(O)】-【会话选项】-【终端】-【仿真】-【终端】, 下拉选项选择【Linux】,【确定】即可。 这样修改完在hive命令行中输入命令就可以自由增删改了。 4、操作数据 1)准备数据 vi student.txt 1 tom 2 zhangsan 3 lisi 4 zhangsanfeng 5 xiexiaofeng 2)创建hive表 create table student(id int,name string) row format delimited fields terminated by "\t"; 3)加载数据 load data local inpath ‘/root/student.txt‘ into table student;
三、Hive数据类型
1、配置hive元数据到mysql 1)驱动拷贝 拷贝mysql--connector--java--5.1.39--bin.jar到/root/hd/hive/lib/下 2)配置Metastore到MySql 在/root/hd/hive/conf目录下创建一个hive-site.xml 根据官方文档配置参数,拷贝数据到hive-site.xml文件中(hive/conf/下创建文件) <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hd09-1:3306/metastore?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration> 2、hive数据类型 Java数据类型 Hive数据类型 长度 byte TINYINT 1byte short SMALINT 2byte int INT 4byte long BIGINT 8byte float FLOAT 单精度浮点数 double DOUBLE 双精度浮点数 string STRING 字符 TIMESTAMP 时间类型 BINARY 字节数组 3.DDL数据定义 1)创建数据库 查看数据库 show databases; 创建数据库 create database hive_db; 创建数据库标准写法 create database if not exist db_hive; 创建数据库指定所在hdfs路径 create database hive_db1 location ‘/hive_db‘; 2)修改数据库 查看数据库结构 desc database hive-db; 添加描述信息 alter database hive_db set dbproperties(‘datais‘=‘tom‘); 查看拓展属性 desc database extended hive_db; 3)查询数据库 显示数据库 show databases; 筛选查询的数据库 show database like ‘db*‘; 4)删除数据库 删除数据库 drop dabase hive_db; 删除数据库标准写法 drop database if exists hive_db; 5)创建表 创建表 > create table db_h(id int,name string) > row format > delimited fields > terminated by "\t"; 6)管理表(内部表) 不擅长做数据共享 删除hive中管理表,数据删除。 加载数据 load data local inpath ‘/root/user.txt‘ into table emp; 查询并保存到一张新的表 create table if not exists emp2 as select * from emp where name = ‘tom‘; 查询表结构 desc formatted emp; Table Type: MANAGED_TABLE 7)外部表 hive不认为这张表拥有这份数据,删除该表,数据不删除。 擅长做数据共享 创建外部表 > create external table if not exists emptable(empno int,ename string,job string,mgr int,birthdate string,sal double,comm double,deptno int) > row format > delimited fields > terminated by ‘\t‘; 导入数据 load data local inpath ‘/root/emp.txt‘ into table emptable; 查看表结构 desc formatted emptable; Table Type: EXTERNAL_TABLE 删除表 drop table emptable; 提示:再次创建相同的表 字段相同 将自动关联数据!
附件1:数据员工表 emp.txt
2369 SMITH CLERK 2902 1980-12-17 800.00 20 2499 ALLEN SALESMAN 2698 1981-2-20 1600.00 300.00 30 2521 WARD SALESMAN 2698 1981-2-22 1250.00 500.00 30 2566 JONES MANAGER 2839 1981-4-2 2975.00 20 2654 MARTIN SALESMAN 2698 1981-9-28 1250.00 1400.00 30 2698 BLAKE MANAGER 2839 1981-5-1 2850.00 30 2782 CLARK MANAGER 2839 1981-6-9 2450.00 10 2788 SCOTT ANALYST 2566 1987-4-19 3000.00 20 2834 KING PRESIDENT 1981-11-17 5000.00 10 2844 TURNER SALESMAN 2698 1981-9-8 1500.00 0.00 30 2976 ADAMS CLERK 2788 1987-5-23 1100.00 20 2900 JAMES CLERK 2698 1981-12-3 950.00 30 2902 FORD ANALYST 2566 1981-12-3 3000.00 20 2924 MILLER CLERK 2782 1982-1-23 1300.00 10
四、DML数据操作
一、分区表 1、创建分区表 hive> create table dept_partitions(depno int,dept string,loc string) partitioned by(day string) row format delimited fields terminated by ‘\t‘; 2、加载数据 load data local inpath ‘/root/dept.txt‘ into table dept_partitions; 注意:不能直接导入需要指定分区 load data local inpath ‘/root/dept.txt‘ into table dept_partitions partition(day=‘1112‘); 3、添加分区 alter table dept_partitions add partition(day=‘1113‘); 4、单分区查询 select * from dept_partitions where day=‘1112‘; 5、全查询 select * from dept_partitions; 6、查询表结构 desc formatted dept_partitions; 7、删除单个分区 alter table dept_partitions drop partition(day=‘1112‘); 二、修改表 1、修改表名 alter table emptable rename to new_table_name; 2、添加列 alter table dept_partitions add columns(desc string); 3、更新列 alter table dept_partitions change column desc desccc int; 4、替换 alter table dept_partitions replace columns(desccc int); 三、DML数据操作 1、向表中加载数据 load data local inpath ‘/root/student.txt‘ into table student; 2、加载hdfs中数据 load data inpath ‘/student.txt‘ into table student; 提示:相当于剪切 3、覆盖原有的数据 load data local inpath ‘/root/student.txt‘ overwrite into table student; 4、创建分区表 create table student_partitions(id int,name string) partitioned by (month string) row format delimited fields terminated by ‘\t‘; 5、向分区表插入数据 insert into table student_partitions partition(month=‘201811‘) values(1,‘tom‘); 6、按照条件查询结果存储到新表 create table if not exists student_ppp as select * from student_partitions where name=‘tom‘; 7、创建表时加载数据 create table db_h(id int,name string) row format delimited fields terminated by "\t" location ‘/root/student.txt‘; 8、查询结果导出到本地 hive> insert overwrite local directory ‘/root/datas/student.txt‘ select * from student where name=‘tom‘; bin/hive -e ‘select * from student‘ > /root/student.txt hive> dfs -get /usr/hive/warehouse/00000 /root;
附件2:数据部门表 dept.txt
10 ACCOUNTING 1700 20 RESEARCH 1800 30 SALES 1900
五、查询与函数
一、查询 1、配置查询头信息 在hive-site.xml <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> 2、基本查询 (1)全表查询select * from empt; (2)查询指定列select empt.empno,empt.empname from empt; (3)列别名select ename name,empno from empt; 3、算数运算符 算数运算符 描述 Col3 + 相加 field3 - 相减 field3 * 相乘 field3 / 相除 field3 % 取余 field3 & 按位取与 field3 按位取或 ^ 异或 field3 ~ 按位取反 field3 二、函数 (1)求行数count select count(*) from empt; (2)求最大值max select max(empt.sal) sal_max from empt; (3)求最小值 select min(empt.sal) sal_min from empt; (4)求总和 select sum(empt.sal) sal_sum from empt; (5)求平均值 select avg(empt.sal) sal_avg from empt; (6)前两条 select * from empt limit2; 三、where语句 (1)工资大于1700的员工信息 select * from empt where empt.sal > 1700; (2)工资小于1800的员工信息 select * from empt where empt.sal < 1800; (3)查询工资在1500到1800区间的员工信息 select * from empt where empt.sal between 1500 and 1800; (4)查询有奖金的员工信息 select * from empt where empt.comm is not null; (5)查询无奖金的员工信息 select * from empt where empt.comm is null;
(6)查询工资是1700和1900的员工信息 select * from empt where empt.sal in(1700,1900); 四、Like使用like运算选择类似的值选择条件可以包含字母和数字 (1)查找员工薪水第二位为6的员工信息 select * from empt where empt.sal like‘_6%‘; _代表一个字符 %代表0个或多个字符 (2)查找员工薪水中包含7的员工信息 select * from empt where empt.sal like‘%7%‘; (3)rlike--select * from empt where empt.sal rlike‘[7]‘; 五、分组 (1)Group By语句计算empt表每个部门的平均工资 select avg(empt.sal) avg_sal,deptno from empt group by deptno; (2)计算empt每个部门中最高的薪水 select max(empt.sal) max_sal,deptno from empt group by deptno; (3)求部门平均薪水大于1700的部门 select deptno,avg(sal) avg_sal from empt group by deptno having avg_sal>1700;注意:having只用于group by分组统计语句 六、其他语句 (1)查询薪水大于1700并且部门是40 员工信息 select * from empt where deptno=40 and empt.sal>1700; (2)查询薪水除了10部门和40部门以外的员工信息 select * from empt where deptno not in(10,40); (3)查询薪水大于1700或者部门是40的员工信息 select * from empt where sal>1700 or deptno=40;
六、join和分桶
一、Join操作 (1)等值join 根据员工表和部门表中部门编号相等,查询员工编号、员工名、部门名称 select e.empno,e.ename,d.dept from empt e join dept d on e.deptno = d.deptno; (2)左外连接 left join null select e.empno,e.ename,d.dept from empt e left join dept d on e.deptno = d.deptno; (3)右外连接 right join select e.empno,e.ename,d.dept from dept d right join empt e on e.deptno = d.deptno; (4)多表连接查询 查询员工名字、部门名称、员工地址 select e.ename,d.dept,l.loc_name from empt e join dept d on e.deptno = d.deptno join location l on d.loc = l.loc_no; (5)笛卡尔积 select ename,dept from empt,dept; 为了避免笛卡尔积采用设置为严格模式 查看:set hive.mapred.mode; 设置:set hive.mapred.mode = strict; 二、排序 (1)全局排序 order by 查询员工信息按照工资升序排列 select * from empt order by sal asc;默认 select * from empt order by sal desc;降序 (2)查询员工号与员工薪水按照员工二倍工资排序 select empt.empno,empt.sal*2 two2sal from empt order by two2sal; (3)分区排序 select * from empt distribute by deptno sort by empno desc; 三、分桶 分区表分的是数据的存储路径 分桶针对数据文件 (1)创建分桶表 create table emp_buck(id int,name string) clustered by(id) into 4 buckets row format delimited fields terminated by ‘\t‘; (2)设置mapreduce数量 set mapreduce.job.reduces; (3)设置分桶属性: set hive.enforce.bucketing = true; (4)导入数据 insert into table emp_buck select * from emp_b; 注意:分区分的是文件夹 分桶是分的文件 (5)应用 抽样测试
附件3:数据地址表 location.txt
1700 Beijing 1800 London 1900 Tokyo
附件4:数据分桶数据表 emp_b.txt
2001 hhh1 2002 hhh2 2003 hhh3 2004 hhh4 2005 hhh5 2006 hhh6 2007 hhh7 2008 hhh8 2009 hhh9 2010 hhh10 2011 hhh11 2012 hhh12 2013 hhh13 2014 hhh14 2015 hhh15 2016 hhh16
七、Hive优化
一、自定义函数 之前使用hive自带函数sum/avg/max/min... 三种自定义函数: UDF:一进一出(User-Defined-Function) UDAF:多进一出(count、max、min) UDTF:一进多出 (1)导入hive依赖包 hive/lib下 (2)上传 alt+p (3)添加到hive中 add jar /root/lower.jar; (4)关联 create temporary function my_lower as "com.css.com.Lower";
(5)使用 select ename,my_lower(ename) lowername from empt; 二、Hive优化 1、压缩 (1)开启Map阶段输出压缩 开启输出压缩功能: set hive.exec.compress.intermediate=true; 开启map输出压缩功能: set mapreduce.map.output.compress=true; 设置压缩方式: set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; 例子: select count(ename) name from empt; (2)开启reduce输出端压缩 开启最终输出压缩功能: set hive.exec.compress.output=true; 开启最终数据压缩功能: set mapreduce.output.fileoutputformat.compress=true; 设置压缩方式: set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io. compress.SnappyCodec; 设置块压缩: set mapreduce.output.fileoutputformat.compress.type=BLOCK; 例子: insert overwrite local directory ‘/root/compress/rsout‘ select * from empt sort by empno desc; 2、存储 Hive存储格式:TextFile/SequenceFile/orc/Parquet orc:Index Data/row Data/stripe Footer 压缩比: orc > parquet > textFile 查询速度: orc > textFile 50s > 54s 例子: create table itstar(time string,host string) row format delimited fields terminated by ‘\t‘; load data local inpath ‘/root/itstar.log‘ into table itstar; create table itstar_log(time string,host string) row format delimited fields terminated by ‘\t‘ stored as orc; insert into itstar_log select * from itstar; select count(*) from itstar; select count(*) from itstar_log; 3、Group by优化 分组:mr程序,map阶段把相同key的数据分发给一个reduce,一个key的量很大。 解决方案: 在map端进行聚合(combiner) set hive.map.aggr=true; 设置负载均衡 set hive.groupby.skewindata=true; 4、数据倾斜 (1)合理避免数据倾斜 合理设置map数 合并小文件 set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 合理设置reduce数 (2)解决数据倾斜 在map端进行聚合(combiner) set hive.map.aggr=true; 设置负载均衡 set hive.groupby.skewindata=true; (3)JVM重用 mapred-site.xml mapreduce.job.jvm.numtasks 10~20 (插槽)
附件5:Lower类的代码如下:
package com.css.com; import org.apache.hadoop.hive.ql.exec.UDF; public class Lower extends UDF { public String evaluate(final String s) { if (s == null) return null; return s.toLowerCase(); } }
附件6:数据表itstar.log(未显示全部)
20180724101954 http://java.itstar.com/java/course/javaeeadvanced.shtml 20180724101954 http://java.itstar.com/java/course/javaee.shtml 20180724101954 http://java.itstar.com/java/course/android.shtml 20180724101954 http://java.itstar.com/java/video.shtml 20180724101954 http://java.itstar.com/java/teacher.shtml 20180724101954 http://java.itstar.com/java/course/android.shtml 20180724101954 http://bigdata.itstar.com/bigdata/teacher.shtml 20180724101954 http://net.itstar.com/net/teacher.shtml 20180724101954 http://java.itstar.com/java/course/hadoop.shtml 20180724101954 http://java.itstar.com/java/course/base.shtml ... ... ... 20180724102628 http://java.itstar.com/java/course/javaeeadvanced.shtml 20180724102628 http://java.itstar.com/java/course/base.shtml 20180724102628 http://net.itstar.com/net/teacher.shtml 20180724102628 http://net.itstar.com/net/teacher.shtml 20180724102628 http://net.itstar.com/net/course.shtml 20180724102628 http://java.itstar.com/java/course/android.shtml 20180724102628 http://net.itstar.com/net/course.shtml 20180724102628 http://java.itstar.com/java/course/base.shtml 20180724102628 http://java.itstar.com/java/video.shtml 20180724102628 http://java.itstar.com/java/course/hadoop.shtml
标签:成本 secure color 本地 格式 exist note 实时 包含
原文地址:https://www.cnblogs.com/areyouready/p/10016487.html