标签:网络 lam ima gradient global 很多 复杂 layer 图片
指数衰减率globalStep=tf.Variable(0)
learningRate=tf.train.exponential_decay(0.1,globalStep,100,0.96,staircase=True)
learningStep=tf.train.GradientDescentOptimizer(learningRate).minimize(losss,global_step=globalStep)正则化
正则化可避免过拟合,模型的复杂程度,由神经网络的所有参数决定,w和b,一般是由权重w决定。
1.L1正则化
L1: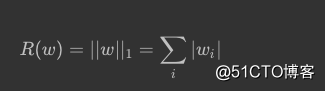
L2: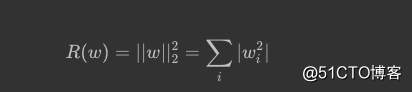
L1使参数变得稀疏,很多参数会为0,这样,可以达到类似特征提取的作用。L1不可导。
L2公式可导,所以对其优化更简洁,但其没有稀疏作用。
可将2个正则化一起使用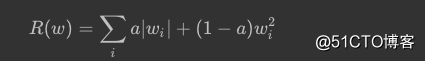
#L2
loss=tf.reduce_mean(tf.square(y_-y)+tf.contrib.layers.l2_regularizer(lambda)(w)
#lambda为正则化权重,即:R(w)*lambda
#L1
loss=tf.reduce_mean(tf.square(y_-y)+tf.contrib.layers.l1_regularizer(lambda)(w)
标签:网络 lam ima gradient global 很多 复杂 layer 图片
原文地址:http://blog.51cto.com/13959448/2321783