标签:http 技术 用两个 事件 image 比特 src 进制 分享图片
比特化(Bits)
假设存在一组随机变量X,各个值出现的概率关系如图;现在有一组由X变量组成的序列: BACADDCBAC.....;如果现在希望将这个序列转换为二进制来进行网络传输,那么我们得到一个得到一个这样的序列:01001000111110010010.......
结论: 在这种情况下,我们可以使用两个比特位来表示一个随机变量。
P(X=A)=1/4 P(X=B)=1/4 P(X=C)=1/4 P(X=D)=1/4
A B C D
00 01 10 11
而当X变量出现的概率值不一样的时候,对于一组序列信息来讲,每个变量平均
需要多少个比特位来描述呢??
P(X=A)=1/2 P(X=B)=1/4 P(X=C)=1/8 P(X=D)=1/8
A B C D
0 10 110 111
假设现在随机变量X具有m个值,分别为: V 1 ,V 2 ,....,V m ;并且各个值出现的概率
如下表所示;那么对于一组序列信息来讲,每个变量平均需要多少个比特位来描
述呢??
P(X=V1)=p1 P(X=V2)=p2 P(X=V3)=p3 .................... P(X=Vm)=pm
可以使用这些变量的期望来表示每个变量需要多少个比特位来描述信息:
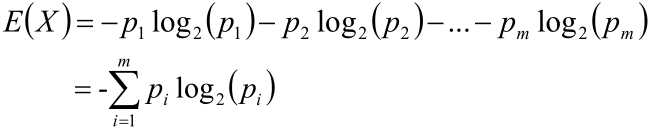
信息熵(Entropy)
H(X)就叫做随机变量X的信息熵;
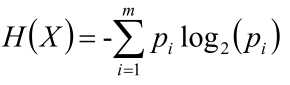
信息熵(Entropy)
信息量:指的是一个样本/事件所蕴含的信息,如果一个事件的概率越大,那么就可以认为该事件所蕴含的信息越少。极端情况下,比如:“太阳从东方升起”,因为是确定事件,所以不携带任何信息量。
信息熵:1948年,香农引入信息熵;一个系统越是有序,信息熵就越低,一个系统越是混乱,信息熵就越高,所以信息熵被认为是一个系统有序程度的度量。
信息熵就是用来描述系统信息量的不确定度。
High Entropy(高信息熵):表示随机变量X是均匀分布的,各种取值情况是等概率出现的。
Low Entropy(低信息熵):表示随机变量X各种取值不是等概率出现。可能出现有的事件概率很大,有的事件概率很小。
条件熵H(Y|X)
给定条件X的情况下,随机变量Y的信息熵就叫做条件熵。
给定条件X的情况下,所有不同x值情况下Y的信息熵的平均值叫做条件熵。
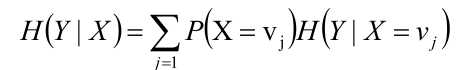
另外,一个公式如下所示:
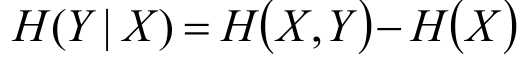
事件(X,Y)发生所包含的熵,减去事件X单独发生的熵,即为在事件X发生的前提下,Y发生“新”带来的熵,这个也就是条件熵本身的概念。
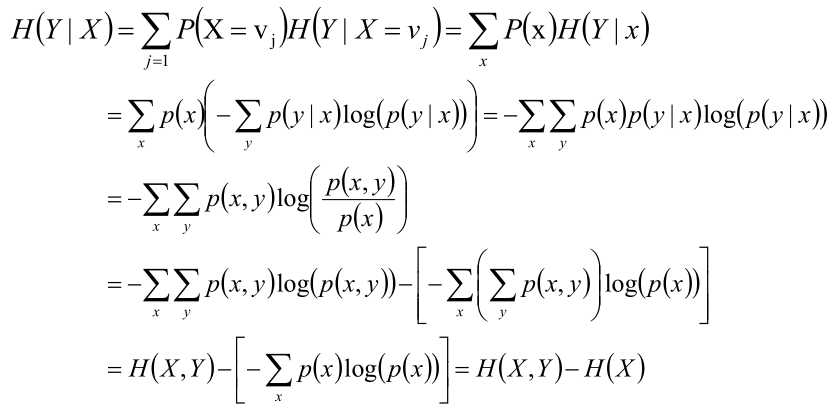
标签:http 技术 用两个 事件 image 比特 src 进制 分享图片
原文地址:https://www.cnblogs.com/pythonz/p/10017400.html