标签:大小 scale 十分 view ros 相等 泛化 注意 二维
本文将主要介绍图像分类问题,即给定一张图片,我们来给这张图片打一个标签,标签来自于预先设定的集合,比如{people,cat,dog...}等,这是CV的核心问题,图像分类在实际应用中也有许多变形,而且许多看似无关的问题(比如 object detection, segmentation)最终也可划分为图像分类问题。
彩色图像通常有RGB三个通道,每个通道都是一个二维数组,比如下图即为一张200*150的图像,该图像分为RGB三个通道,所以该图像可用200*150*3 = 90000的一维数组表示,数组每个点的取值为0(黑色)到255(白色)。图像分类即将这个90000维的数组打上标签,比如 dog。

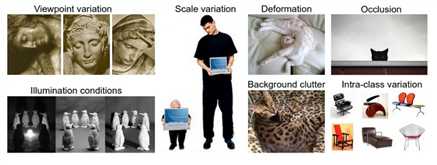
目前图像识别面临的挑战有:
图像分类的方法,目前主要是机器学习中的监督学习的方法,给定训练数据 {x(i),y(i)} 来训练一个分类器来进行分类,比如KNN算法

KNN算法中有超参数(hyperparameters )需要选个K的取值以及距离的度量(L1还是L2 距离),所以需要对数据进行划分,分别训练集与测试集,这里的测试集是十分宝贵的,用来测试模型的泛化性,而我们又要训练一个准确的模型,这时可以把训练数据进一步切分来进行Cross-validation.以下便是5折交叉验证,通过交叉验证的方法找到最优的模型,进而用测试集来测试模型的泛化能力。

KNN是非常慢的,因为每一次预测都要计算与训练数据集中所有图像的距离,找出 top k,实践KNN时需要注意一下几个问题:
1)预处理数据为0均值与单位方差(图像数据各个维度通常方差与均值都相等,因为像素介于0-255,所以图像可以省去此步骤)
2)高维数据可用PCA
3)若有很多参数,要保证测试集数据足够多,训练数据少得话就交叉验证之,交叉验证的 fold 越多,计算复杂度越高。
4)交叉验证时比如以上的图分了5折,其中用fold1 fold2 fold3 fold5 来训练,fold4 测试得到了最好的模型,这时在测试集测试时,可以不用fold4,把fold4当成burden扔掉。
Intorduction To Computer Vision
标签:大小 scale 十分 view ros 相等 泛化 注意 二维
原文地址:https://www.cnblogs.com/alan-blog-TsingHua/p/10024752.html