标签:分享 red 读取 情况下 需要 添加 mapr puts nbsp
在map阶段读取数据前,FileInputFormat会将输入文件分割成split。split的个数决定了map的个数。影响map个数(split个数)的主要因素有:
1) 文件的大小。当块(dfs.block.size)为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
2) 文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为128m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
3) splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节
InputSplit=Math.max(minSize, Math.min(maxSize, blockSize)
其中:
minSize=mapred.min.split.size
maxSize=mapred.max.split.size
我们可以在MapReduce程序的驱动部分添加如下代码:
TextInputFormat.setMinInputSplitSize(job,1024L); // 设置最小分片大小
TextInputFormat.setMaxInputSplitSize(job,1024×1024×10L); // 设置最大分片大小
看下源码:
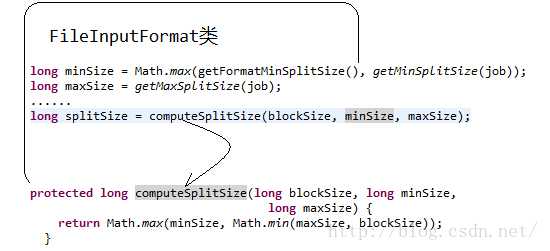
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
(1)默认map个数
标签:分享 red 读取 情况下 需要 添加 mapr puts nbsp
原文地址:https://www.cnblogs.com/bj-xiaodao/p/10025781.html