标签:mpi sha read erro config autoconf uniq include div
最近在github上面看到一个开源的ocr文字识别库,感觉效果还可以,所以在这里介绍一下,这个项目的原地址在:https://github.com/tesseract-ocr/tesseract。
tesseract库支持你训练自己的文字识别模型,当然其本身已经提供了几十种不同语言模型,你也可以直接下载使用,最新的4.0版本使用了LSTM神经网络框架,
在识别中文方面效果还是不错的。tesseract有两种使用方式,一种是安装完成以后,通过命令行向tesseract应用传入要解析的图片,翻译完成后输出一个txt文件;
第二种方式是自己写程序调用api函数。
下面介绍一下tesseract库的使用方法。
如果你用的是ubuntu18.0.4那么安装很简单:
在终端输入指令安装即可:
sudo apt-get install tesseract-ocr
sudo apt-get install libtesseract-dev
如果你跟我一样是使用ubuntu16.0.4,那么需要按照我下面的方法来安装,因为16.0.4采用上面的办法安装的是3.0的版本,3.0解析的效果不是很好。
如果你是在windows平台或其他平台可以参考:https://github.com/tesseract-ocr/tesseract/wiki/Compiling。
(1)安装依赖库
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
sudo apt-get install libicu-dev
sudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
sudo apt-get install git
(2)安装leptonica 1.74
cd ~/Download
git clone https://github.com/DanBloomberg/leptonica
cd leptonica
./configure
make
make install
(3)安装tesseract
cd ~/Download
git clone https://github.com/tesseract-ocr/tesseract
cd tesseract
./autogen.sh
./configre --prefix=/usr/local
make
make install
(4)下载语言包
tesseract提供了三种模型,testdata:普通模型,testdata_fast:快速识别模型,testdata_best:最佳识别模型,
在:https://github.com/tesseract-ocr/tessdata_best目录下下载:eng.traineddata、chi_sim.traineddata、chi_sim_vert.traineddata三个文件,
然后将这三个文件复制到/usr/local/share/testdata目录下,如果你想识别其他语言也是下载语言识别模型然后放到testdata目录下即可。
(5)设置语言模型路径
vim ~/.bashrc
在末尾添加:export TESSDATA_PREFIX=/usr/local/share/tessdata/
然后关闭终端,重新打开终端生效。
(6)测试识别库
在终端输入
tesseract --version看版本是否如下:

输入:
tesseract --list-langs查看语言模型是否正确:
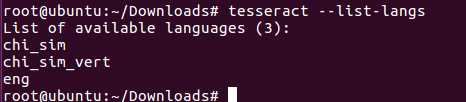
可以看到自动识别了英语和简体中文模型了。
然后随便找张有中文字符的图片进行识别测试:
tesseract 1.jpg out -l chi_sim
参数说明:1.jpg:要解析的文件
out:解析输出的文件名
-l chi_sim:采用的语言模型,这里选择了简体中文。
我识别的原文:

识别到的文字如下:
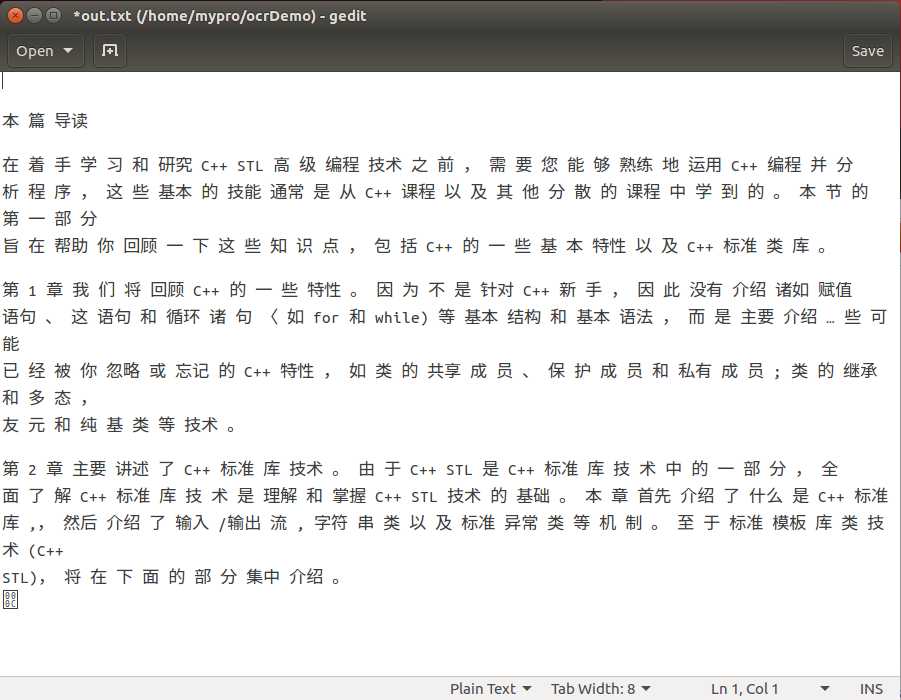
(7)用C++调用api进行识别测试。
代码:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <iostream>
#include <memory>
using namespace std;
int main()
{
tesseract::TessBaseAPI api;
cout<<"version:"<<api.Version()<<endl;
if(api.Init(NULL,"chi_sim")==0)
cout<<"Init Ok"<<endl;
else
{
cout<<"Init error"<<endl;
return -1;
}
api.SetPageSegMode(tesseract::PageSegMode::PSM_AUTO);
api.SetVariable("save_best_choices","T");
auto pixs = pixRead("./1.jpg");
if(!pixs)
{
cout<<"load image error"<<endl;
return -2;
}
api.SetImage(pixs);
api.Recognize(0);
cout<<std::unique_ptr<char[]>(api.GetUTF8Text()).get()<<endl;
api.Clear();
pixDestroy(&pixs);
return 0;
}
makefile:
CXX := g++ CXX_FLAGS := -Wall -Wextra -std=c++11 -ggdb BIN := . SRC := . INCLUDE := LIB := LIBRARIES :=-llept -ltesseract EXECUTABLE := ocrDemo all: $(BIN)/$(EXECUTABLE) run: clean all clear ./$(BIN)/$(EXECUTABLE) $(BIN)/$(EXECUTABLE): $(SRC)/*.cpp $(CXX) $(CXX_FLAGS) -I$(INCLUDE) -L$(LIB) $^ -o $@ $(LIBRARIES) clean: -rm $(BIN)/*
测试效果:
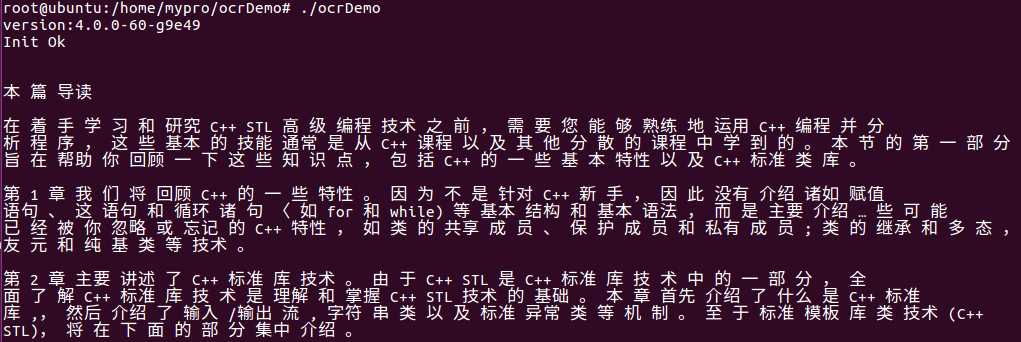
标签:mpi sha read erro config autoconf uniq include div
原文地址:https://www.cnblogs.com/WushiShengFei/p/10020481.html